What makes movies similar?
Senior Researcher, Human-Computer Interaction
Senior Researcher, Human-Computer Interaction
Senior Researcher, Human-Computer Interaction
“What movie should we watch this evening?”
We’ve all been there.
From Netflix to Hulu, the need to create effective movie recommendation systems is extremely important given the huge demand for personalized content. Often the sheer range of choices is bewildering.
If you’re like me, one way to find movies is by searching for movies similar to something you’ve watched before. This of course requires your system or provider to know what it means for a movie to be similar or not similar to each other.
Here, I will discuss how we can improve perceived similarity, define what makes two movies similar, and outline the benefits of improving recommendations. Consider this my attempt to help make your Friday evenings that little bit more peaceful…
Similarity-based recommender systems today
When we view items in an online store, it is pretty common to see similar items. For example, let’s say I am in a video-on-demand store where I choose the movie Big Buck Bunny, the system could show me other similar movies such as in the image below.
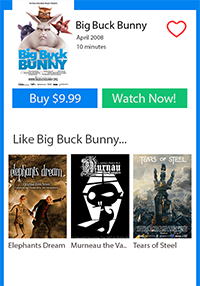
Figure 1 An example of how online systems could show items similar to one the user has selected.
This approach of recommending similar items is pretty common in a lot of online stores. We at Ericsson have referred to this as “More Like This” recommendation. Other providers use different terminology including “People who liked this also liked…”, “people also watched…”, “you may also like…”, “other movies like this”, and many others. Regardless of the exact terminology, the basic idea is the same: to recommend other movies that are similar to the one that is chosen.
Improving perceived similarity in movies
From a technical perspective we consider items to be similar if they share similar features. That’s a somewhat circular definition, so let’s explore it a little bit. There are two basic approaches that can be used: content-based similarity and collaborative similarity.
Content-based similarity
In content-based similarity, items are considered similar if they share the same metadata. For example, items that share the same genre might be considered similar. So, a movie that is action-comedy is more similar to another movie that is also action-comedy than one that is an action-thriller.
Now we can mix that with other metadata such as the movie’s title, director, producer, cast, and many more. For example, an action movie starring Arnold Schwarzenegger is similar to another action movie starring Arnold, but not similar to a comedy starring Arnold.
Collaborative similarity
Collaborative filtering on the other hand uses data about the people who watched the movie. So, if everyone who watched movie A also watched movie B, then we can infer that movies A and B must be somehow similar. This approach is referred to as item-item collaborative filtering and has some benefits over the content-based similarity. For example, collaborative filtering does not need to know anything about the items themselves, only that the same group of people watch them.
These methods used to find similar items are rooted in information retrieval and machine learning, and are often used to find similar items, such as movies.
An important question for us to ask is: do people agree with what the algorithms say?
In 2015, we decided to put this to the test with the help of a few students from Carnegie Mellon University Silicon Valley.
The students built a system which implemented existing similarity methods and crowdsourced for perceived similarity. Users could go into the system, find movies that they knew, then tell the system if they agreed with the suggested similar movies. We recruited a small number of participants for this study. From this exercise we found that people tend to agree with existing similarity methods about 50% of the time (Colucci et al., 2016).
We thought that we could do better than that. So, using this feedback as labels we retrained a few rudimentary machine learning models using movie metadata as input. Then we tested it with a different set of people to see if we could do any better.
We found that our best method was about 30% better with a precision of .67 which is a fancy way of saying people agreed with 67% of the suggestions, as compared to the benchmark of 51% with existing methods.
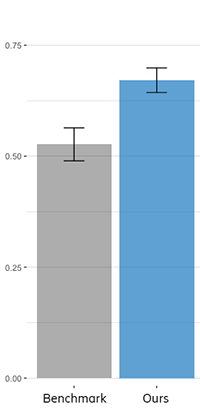
Figure 2 Our method demonstrated clear improvements over existing methods.
The reason our approach worked was simple: existing methods tend to use unsupervised learning or heuristics methods, where the definition of similarity was defined by the developers.
In our research however, we started by asking people to submit their perceived similarity, hence giving us labels that we could use to build supervised learning models. In other words, our approach was data-driven, and built from the ground up to specifically match user perception of what is similar, and not what developers think is similar.
We have since investigated ways to further improve the discovery of similar movies, including a collaborative-content hybrid method that could have the best of both worlds. We found that we could go up to 72% with these more advanced methods (Leng et. al 2018).
Pretty impressive considering we only had about 4000 labels from 14 people who each spent about 40 minutes in the system.
What makes two movies similar?
The question that we often get is what actually makes two movies similar. We found researchers who build similarity models often use three features or metadata of a movie: genre, director, and cast. Movies that have more of these in common are considered more similar. In our research, we found that a very important metadata to be considered is writer. Writer was the second-best predictor of perceived similarity behind genre, while directors and cast were the lowest among the features that we considered, behind even the year of release.
This finding was quite surprising to us, as we have not found any research that mentioned the importance of writer towards similarity. But we think it makes sense. Writers tend to write similar stories, while directors are like guns for hire. They may tell a story in a similar way, but as it turns out that is not sufficient to make people believe two movies are similar.
There are also movies where the same person both writes and direct the movie, such as Quentin Tarantino movies. People often consider these movies to be quite similar, but perhaps that perception is more due to the fact that they share the same writer rather than the same director.
Impact of improving similarity
The main reason we should care about improving similarity is that it improves the user experience. One way it does that is by improving trust in the system. Imagine looking for the movie Titanic and having the system tell you that other similar movies include Iron Man, Ninja Turtles, and Thor. I would have a hard time trusting that system.
Another reason to improve similarity is that improving similarity improves recommendations. Recommender systems are also separately used in online systems, it tries to recommend new movies for you to watch based on movies you have watched before. By improving what we know about similarity, it is possible for us to improve recommendations as well (Wang et al., 2017).
Recommender systems excel when the system knows a lot about the user, which requires a lot of user-item data, such as which users watched which movies and if they liked the movie they watched. But this makes it hard to recommend new movies where there is no consumption data, often referred to as the ‘cold-start problem’. It is likewise hard to provide recommendations to new users whom we know nothing about, therefore even harder for new content providers who have little to no user-item data.
Similarity-based recommendations on the other hand can be done using only the metadata of the movie. And as we gain more information about the user’s preferences, we can slowly improve. Similarity-based recommenders can also be used in systems that do not have user login, such as in-flight entertainment systems or in hotel rooms. The ability to provide recommendations without knowing anything about the user could also allow for privacy-preserving recommender systems.
While metadata such as Genre, Writer, and Cast come pre-packaged with most movies, we have also experimented with extracting metadata from movies. Will we use extracted metadata to find similar movies in the future? Stay tuned to find out!
Further Reading
Here are a few published works in this area done by our collaborators at CMU:
1. Colucci et al. (2016) – Evaluating item-item similarity algorithms for movies.
2. Wang et al. (2017) – Content-Based Top-N Recommendations with Perceived Similarity
3. Leng et al. (2018) – Finding Similar Movies: Dataset, Tools, and Methods
Acknowledgement
Thank you to the CMU students who have worked on this research initiative over the years: Lucas Colucci, Tong Yu, Prachi Doshi, Kun-Lin Lee, Jiajie Liang, Yin Lin, Ishan Vashishtha, Charlie Wang, Arpita Agrawal, Xiaojun Li, Tanima Makkad, Ejaz Veljee, Hongkun Leng, Caleb De La Cruz Paulino, Momina Haider, Rui Lu, Zhehui Zhou. The CMU staff who supervised the practicum projects: Jia Zhang, Ole Mengshoel, Jeannice Samani. And the Ericsson staff who have co-supervised, consulted, or advised and guided me: Julien Forgeat, Per-Erik Brodin, Nimish Radia, Per Karlsson.