Enhancing service mobility in the 5G edge cloud and beyond
Master Researcher, Cognitive distributed cloud
Senior Researcher, Cloud
Master Researcher, Cognitive distributed cloud
Senior Researcher, Cloud
Master Researcher, Cognitive distributed cloud
Senior Researcher, Cloud
What is the best way to implement cloud native edge services in 5G and beyond?
The edge cloud offloads computing from user devices with lower latency, higher bandwidth, and less network load than centralized cloud solutions. Services that stand to benefit immensely from edge cloud support in 5G and future 6G include extended reality, cloud gaming and co-operative vehicular collision avoidance.
A challenge arises with the mobility we expect in mobile networks: How to move a service along when the end-user moves? When the terminal moves physically, the service should be relocated again to the closest edge cloud.
Terminal mobility has been supported by several generations of cellular networks – we can move around with our mobile devices and the network keeps calls and other services running. But now with the edge cloud, server-side mobility is also needed.
Independent of the actual intent or policy behind a service relocation, the service itself may or may not be stateful.
Stateful vs stateless services
In the digital world, stateless services can be implemented, for instance, with serverless or Function-as-a-Service (FaaS) technologies. The relocation of such services can be handled, for example, using load balancers, or – in the case of Kubernetes, which we are looking at here – ingress services. However, serverless services that can serve clients purely based on ephemeral input from the client are rare; even serverless services often need to store some state in databases, message queues or key-value stores. Upon relocation of the service, its state should follow along and be transferred to the proximity of the service, preferably in a vendor-agnostic way. Otherwise, the service may experience, for instance, unexpected latencies when it is trying to access its state.
While stateless services are ideal in the cloud-native philosophy, some stateful legacy services could be too costly to be rewritten to be stateless, or the performance of some applications could be simply better as stateful. In such a case, the relocation of the service could be handled with container migration in the case of Kubernetes. The benefit of such a scheme is that it works with unmodified applications. The main drawback is that existing connections based on the popular Transport Control Protocol (TCP) may break because the network stack is not transferred along with the container. This may cause service interruptions that can even be noticeable in the terminal.
Implementing cloud native edge services
Our approach is an attempt to find a balance between the different constraints: the application is allowed to be stateful but needs to be able to push its state into a database and restore it. The rest is handled by the underlying framework. But what would such a system then look like?
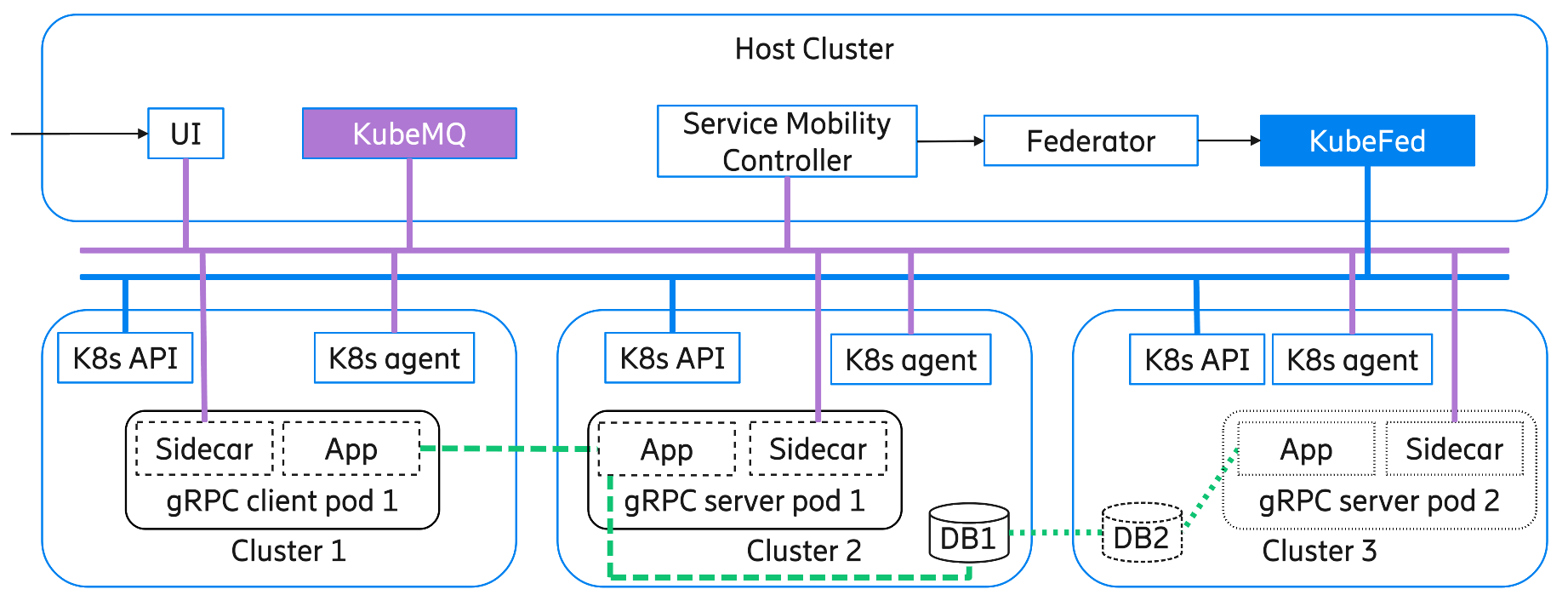
Figure 1: The system architecture of the proposed implementation prototype
Before explaining how the system works, let us first focus on what the system is supposed to achieve. The illustration above shows four different clouds each represented as a Kubernetes cluster with the host cluster on the top managing three edge clusters shown at the bottom of the figure. The goal is to be able to move or relocate a stateful server-side application (gRPC server pod 1) from the second cluster to the third cluster without the application losing any state. To quantify how well the system avoids service interruptions during the relocation, the server-side application is connected to a test application (gRPC client pod 1, located in the first cluster) that is constantly measuring latency to the server pod and sending the measurements to the server which the server stores as its “state”. The challenge here is this state must remain intact when the system relocates the server pod across cluster boundaries. Further, how can this be achieved with minimized service interruption?
| Component | Purpose |
| User Interface (UI) | Web-based UI that can be used to visualize the topology |
| KubeMQ | Publish-subscribe service to facilitate signaling between system components |
| Service Mobility Controller | Orchestrates the process of relocation of server pod running and its state |
| Federator | An optional wrapper for KubeFed allowing easier (un)joining of a cluster to the federation |
| KubeFed | Federated Kubernetes supports launching and terminating of workloads in a multi-cluster environment |
| K8s API | Unmodified K8s API available in each cluster |
| K8s agent | Observes the status of the pods (e.g., “running” or “terminated”) and reports to Service Mobility Controller |
| App | The actual workload or application running in a container. Both the client and server applications communicate over gRPC |
| Sidecar | A system container based on Network Service Mesh (NSM) framework, running in the same pod as the App. The connectivity between applications is managed by NSM. |
| gRPC client/server pod | The pod hosting either the gRPC client or server application |
| Database (DB) | In-memory key-value store based on Redis used for storing the latency measurements at the server pod |
Figure 2: Description of the purpose of the prototype’s individual components
How does the proposed solution work? When the server-side pod needs to be moved, the service mobility controller (SMC) launches replicas of the server-side pod, including the database, to cluster 3. Then the SMC starts to synchronize the database replica in cluster 3 with the one in cluster 2. When the database synchronization is almost complete, the SMC temporarily blocks the server-side pod until the database synchronization is completed. After this, the SMC instructs the test client to re-establish communications to the new server pod. Finally, the SMC then tears down the unused resources in cluster 2.
Performance of a service mobility prototype
We evaluated the performance of prototype from the viewpoint of service interruptions as shown in the figure below. The x-axis shows how often (every x millisecond) the gRPC client was measuring latency. The y-axis shows how many times the gRPC client had to retransmit the data during the relocation of the gRPC server (green bar) and the standard deviation from ten test runs (the error bar).
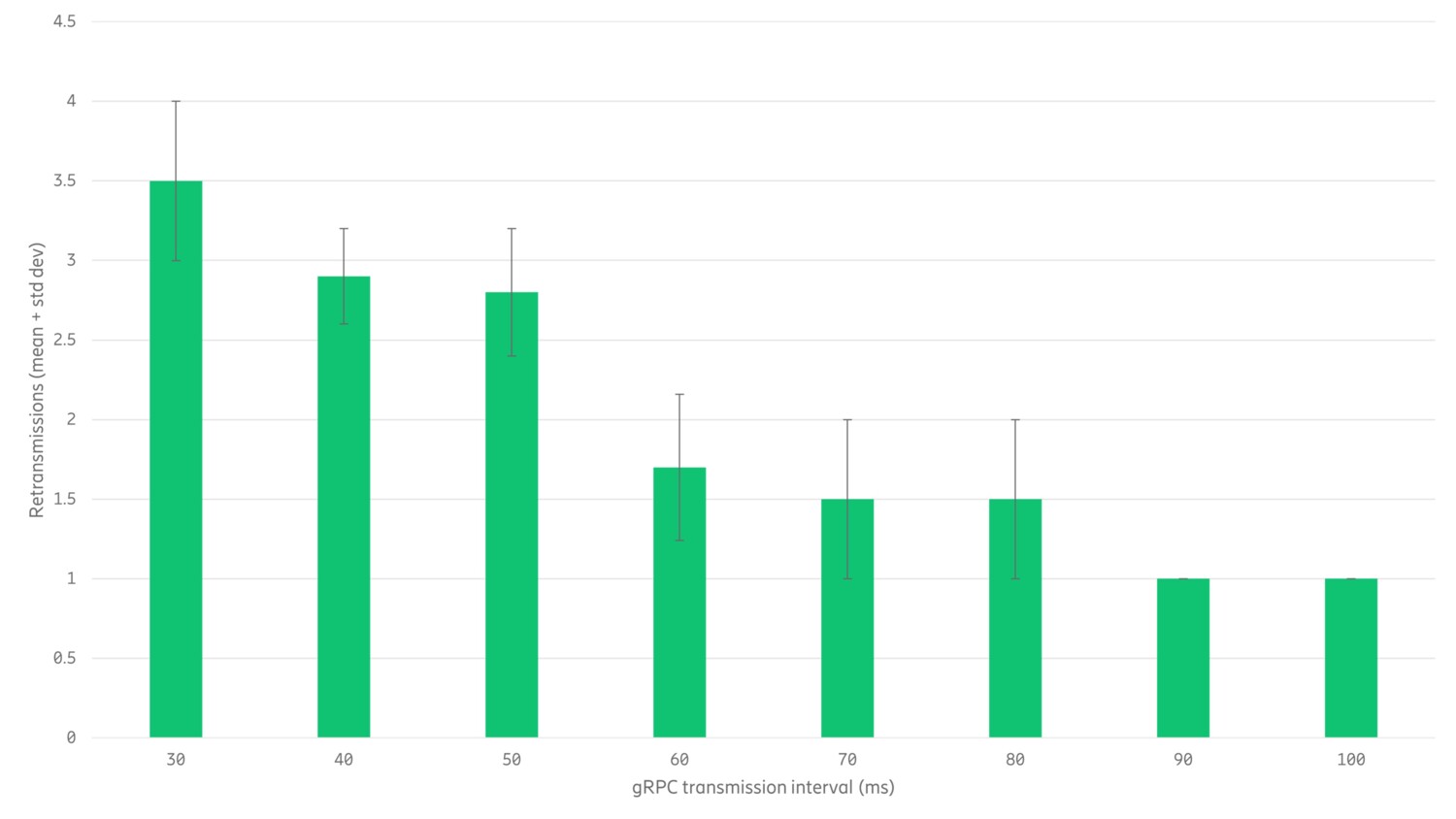
Figure 3: Evaluating the prototype’s performance based on service interruptions
In the figure above, the leftmost bar shows that gRPC client had to retransmit 3.5 times on average when the client was measuring latency every 30 milliseconds. Towards the right side of the figure, the number of retransmissions decline to a single retransmission at 90 and 100 millisecond latency measurement intervals. It is worth noting that no packets are dropped because the gRPC utilizes reliable TCP as its transport. The measurement environment was also challenging in the sense that Kubernetes was operated on top of virtual machines in an OpenStack environment that was also running other workloads, and link throughput was constrained to 1 Gbit/s.
Based on our evaluation with the prototype, we believe that it is possible to support relocatable, stateful services in a multi-cloud environment. Moreover, it is possible to achieve this in a cloud-native way and to optimize the underlying application framework to minimize service disruptions. We believe the proposed solution for Kubernetes could be used for implementing relocatable and interruption-free third-party services within the 3GPP edge computing architecture, for the application-context relocation procedure in specification 23.558, to be more exact. Further, edge computing architecture with support for service mobility could be used as a building block in different scenarios, like the mentioned extended reality, cloud gaming, and co-operative vehicular collision avoidance use cases.
Quest for next generation cloud-native applications
The results shown in this article are preliminary and require further analysis. The prototype can further be optimized and could also be benchmarked against container migration. Our work is a complementary solution for migration, not a competing one; one could utilize whichever fits better with the service in question. In container migration, the application is unaware of the migration, whereas in our approach the application is aware of its relocation and state transfer procedures, even though some parts are hidden from the application.
We have barely scratched the surface with our prototyping efforts; this begs the question of how the next generation of cloud-native applications are written and what is the responsibility split between the application, cloud-integration framework, and the underlying cloud platform?
Learn more
Visit Ericsson’s edge computing pages to explore the latest trends, opportunities and insights at the edge.
Find out how edge exposure can add value beyond connectivity in the 5G ecosystem.
Explore our earlier work in the field on multi-cloud connectivity for Kubernetes in 5G.