5G: flexibility or high performance? Both!
An OpenFlow SW switch compares to a low-end HW router
In NFV/cloud systems, one main component is the software switch – or virtual switch – which handles packets coming in on the physical interfaces and distributes them to the correct virtual network function. But it can do much more: today, OpenFlow (OF) is probably the most suitable protocol to control virtual switches and it is capable of many things in addition to mere forwarding.
We have shown that the extra flexibility that comes with OpenFlow does not ruin performance. Our highly optimized software switch (demonstrated at MWC 2015 and SDN & OF WC 2015) has performance that is comparable to legacy solutions. One of our demo scenarios includes a router that can forward 100 Gbps with small (96 byte) packets on a fairly old Intel machine using 10 cores. Or, in other words, the flow switch can forward more than 100 million packets per second, which is comparable to a low-end hardware router.
Enhancing flexibility of OpenFlow even further without losing high performance
But what happens if some network function is not supported by the OpenFlow protocol? The traditional NFV way, using virtual machines or containers, does not have high enough performance today. One solution is defining and using domain specific languages. But we propose that a simpler way is to extend OpenFlow, and in this blog post we will explain how.
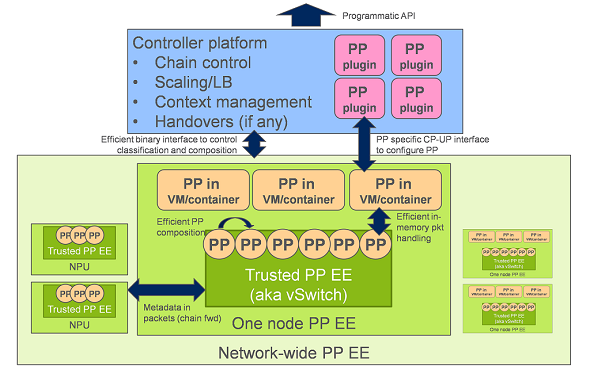
It's always possible to implement a network function as a separate entity and run it in a virtual machine or container. This is the basic idea of NFV. The EU co-funded project “UNIFY” goes one step further when introducing its “Universal Node” (UN). The UN concept already acknowledges and benefits from the fact that some network functions can be so-called “switch internal” network functions, in addition to those in VMs and containers. This basically means that if a function, for example a firewall, or routing, can be done in the switch, the entire pipeline – the chain of network functions – can be optimized.
What is this optimization about? First, the host machine – virtual machine I/O interfaces have significant overhead. This is true even for high-speed optimized variants such as Intel DPDK's shared memory based I/O as well as for the currently very popular container based technologies. The overhead can be negligible for Virtual Network Functions (VNF) that require significant processing, such as a deep packet inspector functions. Traditional NFV processing also has a clear advantage: because of the long and variable processing time it is better to run the VNF pipeline separated from the higher speed switch pipeline. There is one more clear use case where a VNF should be placed in a well-controlled virtual environment: if we use 3rd party software components that cannot be treated as trusted applications.
On the other hand, relatively simple functions like NAT (Network Address Translation), a new protocol encapsulation or some other simple packet manipulation, can’t afford this overhead. Note that most mobile or residential networking functions are of this kind. They are not extremely complex, but combined in many different ways, and the amount of new functions and combinations will increase rapidly in the future driven by IoT and 5G. Standardizing or implementing all new elements in hardware simply takes too long, thus for these functions a flexible software implementation seems to be an ideal choice. As the performance is critical, these packet processing functions should be part of the switch pipeline and the entire pipeline should run in a run-to-completion mode, where the entire lifetime of the packet is spent in one piece of code, which minimizes context switches and memory transfers.
A platform for real-time composition
In order to support real-time composition of packet processing primitives, we designed an interface where external applications can register their function calls to the switch. But it is more than just specifying a callback. The API can also take care of auxiliary functionality that is required for each application anyway, such as table and memory management or the relocation of states/context between different nodes for handover. This way the performance will be much higher than by doing it the traditional NFV way: in virtual machines. Functions can be simpler since they can rely on the highly optimized table and memory management of the system. It also becomes possible to apply the just-in-time linking infrastructure that already exists in the switch, to new packet processing functions. JIT linking here means that (part of) the pipeline is realized by simply copying the machine code of basic packet processing primitives one after the other, with static data possibly also stored in code. That way, the amount of branches and memory accesses is reduced, resulting in a low overhead composition.
In short, we envision a platform which can be used to dynamically compose data plane nodes from packet processing primitives (PPs), using any of the following composition methods: JIT linking, function calls or generic code running in separate VMs or containers; all in a single system, using the same abstraction. We envision that the composition supports different hardware architectures, such as network processors (NPUs) or chips with hardware acceleration for certain tasks. The exact nature of the composition used by a particular primitive is hidden from the control plane, allowing continuous performance innovation inside the data plane node, while the ability to add new packet processing functions regardless of their size enables continuous feature innovation.
Changes in the OpenFlow protocol
There is always a price to pay. In our case, it is the change needed in the OpenFlow protocol to support the addition of new packet processing functions.
Two types of functions are considered: one is a simple action type that has no state. An example: to copy one header field to another, perhaps after some arithmetic. Another type of function can maintain state for various packet flows (called “context”) and is always invoked with a specific context instance. The implementation is similar to meters in OpenFlow: invoking the function is possible from a generic OpenFlow table, whereas the processing function itself would store the context in its own table (managed in most cases by the switch).
Where does this take us? We now have match tables with action lists that may include any action from an extensible set of actions, all of which can be very small, very large or anything in between. This sounds a pretty generic data plane abstraction, especially if the match fields are also made programmable, such as in protocol oblivious/independent forwarding (POF/PIF) or in P4.
Can we see it as a future for OpenFlow? The POF/PIF and P4 initiatives all point in a direction where programmable packet processing will not depend on standardized OpenFlow action sets anymore. In those initiatives, the programmer can program actions on a very low abstraction level, using a domain specific programming language. But do we have to go that far and completely drop OpenFlow? Or is it enough to include just the painfully missing pieces like self-learning and context handling?
We believe, that by extending OpenFlow, we can have a system where most of the functionality is executed in the very optimal switch pipeline, while the possibility will remain to support standard VNF based applications. To us, this seems a simpler way than defining an action language that is able to utilize the special features of all NPUs and CPUs.
Gergely Pongrácz, Zoltán Turányi, Gábor
Enyedi, László Molnár, András Császár
Ericsson Research, IP & Transport research
Dániel Gehberger, Balázs Pinczel,
Bence Formanek
Ericsson Research, Cloud Technologies research