Data processing architectures – Lambda and Kappa examples
Principal Researcher in Artificial Intelligence, Ericsson Research
Principal Researcher in Artificial Intelligence, Ericsson Research
Principal Researcher in Artificial Intelligence, Ericsson Research
Movie recommendations
Movie recommender systems are an important part of modern media delivery platforms, as they enable a personalized service experience by suggesting relevant movies to users. The ability to deliver accurate and diversified recommendations on time is key for user retention, and thus for revenue generation.
Movie recommender systems typically base their recommendations on a combination of implicit and explicit feedback collected from users. Examples of implicit feedback are clicks, movie views, and location. Explicit feedback is typically collected in the form of movie ratings. Predictions are used to generate lists of personalized movie recommendations.
The design and implementation of a movie recommender system is a challenging task, since there needs to be a balance between accuracy and responsiveness. Accuracy is important to really make the movie predictions relevant. Responsiveness is important in order to provide near real-time recommendations when the users interact with the movie delivery platform.
To enable accurate and responsive movie recommendations, scalable prediction methods are needed. Moreover, such methods need to be implemented within a scalable data processing system. Collaborative filtering approaches via Matrix Factorization (MF) have shown to produce good results in generating predictions at scale, read more here. Production systems implementing collaborative filtering based on MF typically have the following requirements:
- Training of large MF models from scratch.
- Incremental updating of MF models.
The former requirement is necessary in order to train the initial MF model. The latter requirement is necessary to provide responsiveness to the arrival of new user preferences, e.g., ratings, clicks. Training from scratch for every new user preference would cause significant computation cost. Algorithms such as Alternating Least Squares (ALS) can be used to train MF models from scratch in a distributed fashion, and other algorithms exist to incrementally update MF models.
The Lambda Architecture is a good candidate to build a MF-based recommender system, because it fulfills two important requirements: (a) a batch layer for initial model training; and (b) incremental updates via the speed layer. A batch layer enables accurate predictions while the speed layer allows for real-time updating, which is key to responsiveness. The algorithms used in the batch and real-time layer are different, which prevents us from using the same codebase.
This year we have implemented a movie recommender system for one of our personalization projects, using the Lambda architecture. Implementing the Lambda architecture is known to be a non-trivial task, as it requires the integration of several complex distributed systems, like Apache Kafka, Apache HDFS, or Apache Spark; as well as machine learning libraries, for example Apache Mahout or Spark MLlib. We have therefore tried to reuse as much code as possible.
Cloudera Oryx is an existing open-source implementation of the Lambda architecture that we decided on adopting. Oryx is based on several technologies that we were already using, including Apache Kafka and Apache Spark. Moreover, it is designed to serve as a framework for implementing machine learning applications with real-time requirements. Actually, a movie recommender is one such application that is shipped with Oryx. The Oryx architecture, shown in Figure 1, is based on four layers: data transport, batch, speed, and serving.
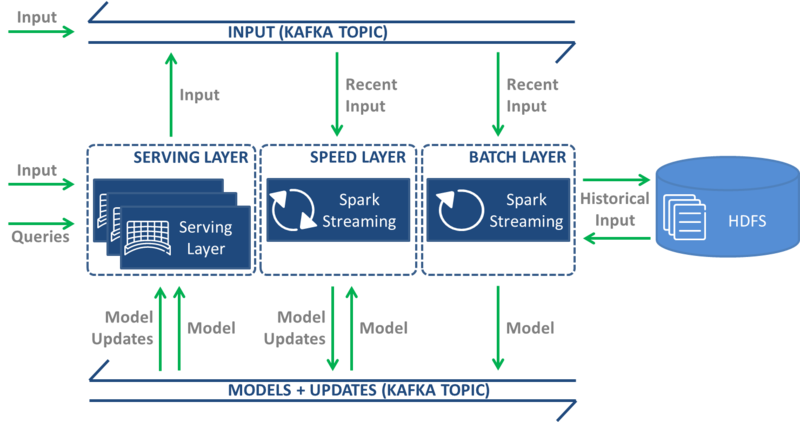
Figure 1 Cloudera Oryx architecture
The data transport layer receives and moves data between the layers. Two types of data are moved in the movie recommender application: (1) user-movie preferences; and (2) initial MF model and MF model updates. The data transport layer is implemented using the Apache Kafka publish-subscribe messaging system. Apache HDFS is used to persist the MF model in PMML format along with all historical data (tuples of user id, movie id, rating, and timestamp).
The batch layer uses a Spark Streaming job with a very long time interval (hours). It saves the data captured in the most recent time interval to HDFS, merges it with the historical data on HDFS, and starts the MF model building process. For the movie recommender application, the ALS algorithm of Apache Spark MLlib is used to build the MF model. The resulting model is stored on HDFS and published on the data transport layer.
The speed layer uses a Spark Streaming job with a very short time interval (seconds). It receives the full model from the data transport layer and performs incremental/online model updates as new data arrives. For example, as users rate movies, the ratings are instantly incorporated into the model, thus allowing near real-time recommendations. The updated model is published on the data transport layer.
Finally, the serving layer is implemented using an embedded web server. The speed layer receives models – initial and updates – over the data transport layer and stores them in-memory. A REST API is provided to interact with the system. Two types of interactions are supported to ingest data and consume models. Examples of data ingestion include new user-movie preferences, and examples of model consumption include model queries such as the N most popular movies.
Human mobility analytics
As a second example, we will now look at a use-case developed a while back in Ericsson Research, called real-time human mobility analytics (rtHMA). This use-case is built around the idea that mobile networks generate a lot of location tagged data, which can be mined to provide high-level patterns of how people move around in a city or country.
Data typically consists of a timestamp, a hashed identifier, and a location identifier that points to a mobile network cell. The location is not as precise as GPS coordinates, but sufficient for an approximate position - airport, particular suburb, stadium, theme park, shopping mall, and so on.
What rtHMA does is consume this data in real-time and output resulting movement patterns in the form of Origin/Destination matrices.
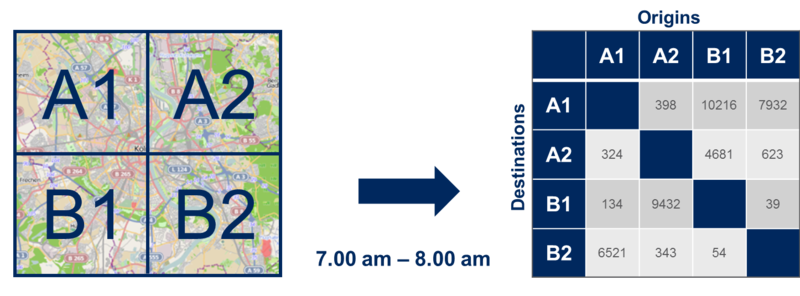
Figure 2: Example of Origin/Destination Matrix.
An Origin/Destination (O/D) matrix is a tool used by some industries, for example transportation, to model mobility demand at city or country level. In each row and column of the matrix, we have the complete list of the locations we want to study – airport, suburb A, suburb B, and so on – and in each cell of the matrix, we have the number of people who traveled from the corresponding column location to the corresponding row location during a specified period of time. Figure 2 shows a city split in 4 different locations: A1, A2, B1 and B2. By reading the O/D matrix on the right side, we can see that 324 people traveled from location A1 to location A2 between 7AM and 8AM.
The algorithm that parses trips out of a stream of location data has been implemented in an Apache Storm topology. Data is fed into the topology in real-time through a TCP socket (a message bus like Apache Kafka could also have been used). Once the trips are parsed, results are saved into a relational database (Postgres) and can be queried using a REST API that we implemented in Python using Django.
This whole pipeline is also able to analyze historical data. To do so, the only step needed is to have historical data in one or several files, and to pipe the content of these files into a netcat instance pointing at the Storm topology socket. From the Storm topology perspective, there is no difference between historical and real-time data. If historical data is replayed, historical data results are overwritten in the database. If Kafka had been used, similar results would have been obtained by having the topology process all retained data of a pre-defined topic.
Before the aforementioned Storm topology was implemented, we actually had an earlier implementation of the algorithm in Apache Hadoop. The process was similar except that data had to be loaded from HDFS. When implementing the Storm version, our initial plan was to keep the Hadoop implementation when working with stored data, as opposed to real-time streams. However, once we realized that the Storm implementation was capable of processing historical data just as fast as the Hadoop one, we simply deprecated it and only kept Storm as a pure Kappa implementation of the use-case.
In this blog post we have presented two example applications for Lambda and Kappa architectures, respectively. As can be seen from our discussion, there is no one-size-fits-all solution for all applications. The movie recommender application clearly benefits from having batch and speed layers in order to achieve batch and incremental model training. This is natural as different algorithms are used for the two layers – training from scratch in the batch setting and incremental training in the speed layer. On the other hand, the rtHMA application does not require distinct algorithms, and hence can be easily implemented using a single layer. We can conclude that the big data processing architecture choice is application dependent and needs to be well thought through.
Eugen Feller and Julien Forgeat,
Ericsson Research, Silicon Valley.