A closer look at Calvin
Research Leader Cloud systems and platforms
Research Leader Cloud systems and platforms
Research Leader Cloud systems and platforms
We are not quite there yet, and the work on Calvin is by no means done. We will continue to develop and improve the platform in the foreseeable future. So far, we have a reference implementation, showing some of our ideas on how device interaction should work. In the coming months, we hope to get the ball rolling by adding more examples, actors and applications, as well as improving the platform as a whole.
With this post, we hopefully add some substance to the discussion, and answer some of the questions you might have. If, after reading this, you have ideas that would make for good Calvin applications, let us know! Or, better yet, experiment with the platform and see what you can build with it!
Ola Angelsmark, Ericsson Research

Introducing Calvin
The lifecycle of a Calvin application is divided into four discrete stages – describe, connect, deploy, and manage – discussed below. For most applications today, whether distributed or not, these stages are mixed without clear borders between them. In Calvin, however, they are distinct and separate with very little overlap.
Describe
In this first stage, the functionality of an application is described using actors as the smallest functional units. The level of detail in the description can differ widely between applications and even within an application. In a home automation system, an actor running on a thermometer, a function which require very little in way of computational power, may be reporting to an actor which handles data base access, which requires more in way of computation power. Similarly, in a surveillance system at a store or an event, there may be an actor handling the images from a camera at the entrance, sending them to an actor detecting the number of people entering or leaving, reporting this to an actor keeping track of the number of people in the building, which in turn controls whether the doors should allow more people to enter.
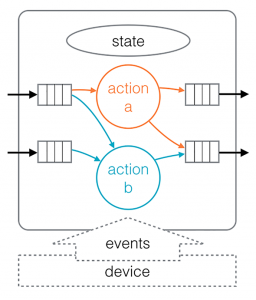
Figure 1: An actor
Although actors are intended to be reusable components developers pick from a large library, there will be times when implementing a new one is appropriate. This is especially true when developing applications using brand new functionality that has not yet been added to the library. Since the runtime, and not the actor, does the heavy lifting, the actor will only work with the specific problem at hand. (How to actually implement an actor is described in the documentation on the GitHub wiki, but may be the topic of a future post.)
Connect
Once the necessary functionality (that is, actors), have been identified, the application is then constructed by connecting these actors. For this we have a small declarative language called CalvinScript. It is used to declare which actors we want to use, and how they should be connected. It can also be used to describe composite actors, allowing for easy reuse of components solving common problems.
A sample Calvin script
The language is intended to be intuitive and straightforward. In figure 2, we have a small script for describing an application where images from a camera are scanned for faces, and an alert is raised if one is detected.
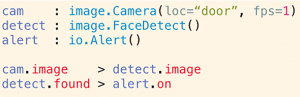
Figure 2: A Calvin script
This component, which is part of a Calvin webserver, checks whether an incoming HTTP GET request is well-formed. The component was originally written as text – we have so far no drag-and-drop programming environment – but we have found that the graphical representation is quite useful for reviewing larger components. The webserver is available among the examples in the GitHub repo.
Deploy
The last two stages, deploy and manage, are so far the least investigated. Primarily, this is due to the fact that the first two have to be in place before these can be looked at more in-depth. Deployment in this setting is determining where each actor should be running. Unlike more traditional IoT and Cloud applications, the initial deployment is by no means the final. Since actors can (more or less easily) be moved independently, it is possible to rearrange the application as the environment changes. The current implementation supports static deployment of actors; that is, each runtime is told which actors to instantiate and execute, and the user or operator has to manually initiate migration between runtimes.
The next step is to implement support for automatic deployment and migration – where an actor, a group of actors, or even the whole application, has a set of requirements that has to be fulfilled. These requirements could be unconditional, or hard, in which case an actor cannot execute at all unless they are satisfied – for example, if some critical resource is unavailable on the current Calvin platform. In the earlier example, the Camera actor is unlikely to function at all if there is no camera, or image stream, available. Note that this does not prevent the actor from being instantiated, connected and migrated, so the application can always be deployed, but it may be the case that not all actors in it can deliver their desired functionality. This also makes it easier to handle failures in the system – if an important resource disappears, the application is still running, and the actor, which is now missing a requirement, can be migrated to a different Calvin device where it is satisfied.
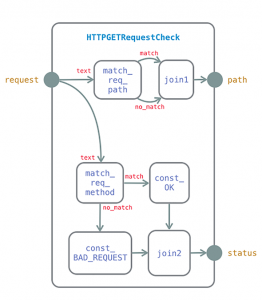
Figure 3: A complex actor/component
Manage
The last stage, management and operation of applications and systems, is probably where most of the future work will happen (and is needed.) Presently, what is available is the possibility to locate applications and actors in the system. It is obviously straightforward to keep track of those on a given runtime, but for a system consisting of several runtimes with a multitude of applications and actors, it can be a bit tricky. For this reason, the runtime can be queried for this information. Similarly, it is possible to check the actors and their firings, what is on the ports, and step through the execution. In short, some bookkeeping and debugging functionality is available, but there is of course much left to do. A quite interesting track is to investigate scaling of actors – if the system discovers a performance bottleneck, there may be situations where actors can be duplicated to better handle the load.
Adopting Calvin
One important feature of Calvin is the possibility to gradually introduce it in a system without having to replace or upgrade existing devices. This is especially important before devices with Calvin support are widely available, i.e. now. It means that it is possible to build a system based on Calvin from the start, without having to wait for upgrades with Calvin support.
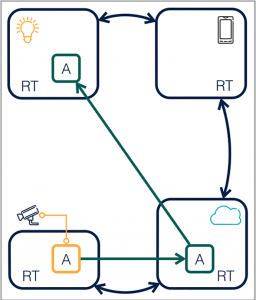
Figure 4: A system with a proxy actor
For some services, it may be desirable to have both the old and the new system running in parallel, and this is of course also possible; either by keeping the proxy actor in place, or have the old service replaced with one executing on a Calvin runtime.
Figure 4 shows an example of a partial adoption of the Calvin runtime. The actors are running natively on Calvin on most devices, but the platform is not yet available on the camera, so for that device, a proxy actor is necessary. For devices that cannot be upgraded, using a proxy actor may even be a permanent solution.