3 ways to train a secure machine learning model
MC^2 team, RISELab, UC Berkeley
Senior Data Science Manager
MC^2 team, RISELab, UC Berkeley
Senior Data Science Manager
MC^2 team, RISELab, UC Berkeley
Senior Data Science Manager
Training a machine learning model requires a large quantity of high-quality data. One way to acquire this is to combine data from multiple organizations. However, data owners are often unwilling or unable to share their data openly due to privacy concerns and regulatory hurdles. For example, enterprises naturally want to protect the privacy of their customer data or prevent sensitive data about their operations from being leaked to their competitors.
So, how can we mitigate such privacy concerns?
Secure and collaborative machine learning
Secure collaborative learning enables multiple parties to build a mutual, robust machine learning model without openly sharing their data with each other – addressing concerns over data privacy and access rights. Banks can collaboratively train models to detect money laundering while keeping their individual transaction data private. Healthcare institutions can privately pool their patient data so they can collaborate on medical studies. Mobile network operators can predict fluctuations in call rates by collectively analyzing their traffic data. The possibilities are vast and promising.
In this blog post, we introduce a new platform for secure collaborative learning that’s currently under development at UC Berkeley’s RISELab – and share Ericsson’s plans to apply the platform to telecom use cases through a new research partnership.
What is the MC2 platform?
The RISELab at UC Berkeley is working on a platform called MC2 (Multi-party Collaboration and Coopetition) for secure collaborative learning. The MC2 project is an effort to enable secure collaborative learning without needing parties to share their entire data in plaintext. MC2’s overarching goal is to make secure collaborative learning practical for everyone.
At a high level, collaborative learning algorithms work as follows:
Each party computes a summary of its data, and provides this summary to a centralized cloud service, or directly to the other parties. The summaries are then aggregated and used to perform updates on an ‘intermediate’ model – which is then shared with all parties. Next, the parties individually compute updates to the model using their local data, and then summarize the updates they’ve applied. These summaries are then exchanged and aggregated as before, and the process continues until the final global model is obtained.
3 secure approaches to collaborative machine learning
Within this general paradigm, there are three important settings – each offering a varying degree of security guarantees and performance:
Federated: parties jointly train a global machine learning model with the help of a centralized aggregator, by exchanging summaries of their individual data in the clear. These individual summaries are used to iteratively update the global model, as described above.

Federated with secure aggregation: in this case, the parties aggregate their local updates using a secure protocol (e.g. via cryptography) which preserves the privacy of the local updates. The intermediate aggregates, however, are revealed to each party as before.

Coopetitive1: The work ‘coopetitive’ is a portmanteau of ‘cooperative’ and ‘competitive’. Here, parties and an (optional) aggregator begin training a machine learning model while exchanging only encrypted data with each other. All intermediate data (local summaries as well as the aggregated updates) always remain encrypted, even during the computation.

The federated approach is less secure because the aggregator sees the individual model updates from each party, and the parties see the aggregated intermediate models. Though the individual updates are only ‘summaries’ of each party’s data and do not directly reveal the entire party’s data, they can reveal significant information about it. Similarly, the aggregated intermediate models may reveal information about other parties’ data to each party. The coopetitive setting provides stronger security because the aggregator does not see the individual updates, nor do the parties see the intermediate aggregated models – all of these are exchanged in encrypted form and kept that way. Only the final model is revealed at the end of the training process, and the parties can decide whether to reveal it only to the aggregator (if present), or to reveal it to the other parties.
On the other hand, with respect to performance, the coopetitive approach is slower than the federated approach because it requires more cryptographic processing (or more computation in specialized hardware) to provide the required levels of security.
Because of the tradeoff between performance and security, MC2’s goal is to support all three modes so that users can choose the modes that best fit their applications. For example, the federated setting may be suitable in a situation where all parties belong to the same umbrella organization but cannot directly share their data with each other due to regulations and compliance issues. In contrast, the coopetitive approach will likely be more apt in situations where the parties are business competitors (and hence, do not trust each other), but are collaborating for mutual benefit.
As a starting point, we are implementing a secure version of the popular XGBoost algorithm within the MC2 platform for training gradient-boosted tree ensembles. The rest of this blog post focuses on RISELab and Ericsson’s collaboration to deploy MC2 for training a machine learning model – the XGBoost model – in the federated setting, for telecom use cases.
Use case: Collaborative learning in Telecom
One important area for secure collaborative learning is in telecommunications. More than 40 percent of the world’s mobile traffic passes through networks delivered by Ericsson. Ericsson-managed networks serve over 1 billion subscribers and have to deal with a variety of issues – ranging from hardware faults to performance problems – that can benefit from machine learning. Some of these issues are common across different networks, but each network is heterogeneous in nature and configurations could differ vastly. Machine learning can provide robust algorithms that deliver similar accuracy across different operators and networks.
In particular, machine learning is well-suited for applications like hardware fault prediction; detecting non-responsive cell sites (‘sleeping cells’); or predicting performance measurements such as blocked or dropped call rates. However, telecommunications systems tend to be extremely reliable, so a single operator may not generate enough fault data to produce robust models. Clearly, using data from multiple operators would enable the creation of stronger, more accurate models that are applicable across a wider variety of situations. Furthermore, since individual operator datasets tend to be highly imbalanced, learning from different, heterogeneous systems helps find root causes of problems, and produces a better model overall.
However, this operator data is often sensitive. It may reveal details about the operator’s network operations, or possibly end user information. Sharing it between operators is likely not possible for competitive, practical, or even legal reasons. Secure collaborative learning mitigates these problems by building models using data from multiple operators, while keeping that data secure and separate. In this scenario, each operator’s data resides in its own heterogeneous environment. Secure collaborative learning enables training across these operators by only allowing each operator to compute updates on its local data using a shared global model. Ericsson then acts as an aggregator that collects and combines each operator’s local updates into a new global model. The global model is given back to the operators for further model updates.
Using RISELab’s federated XGBoost software, Ericsson has been able to train gradient-boosted tree ensembles on its telecom use case. Tests on the federated setup yielded promising results – Ericsson found that the accuracy of federated XGBoost was comparable with running XGBoost on a centralized dataset.
Next step: Federated learning with secure aggregation
Data summaries shared with the aggregator during federated learning can potentially leak significant information about the underlying dataset. In many cases, stronger security guarantees are desirable.
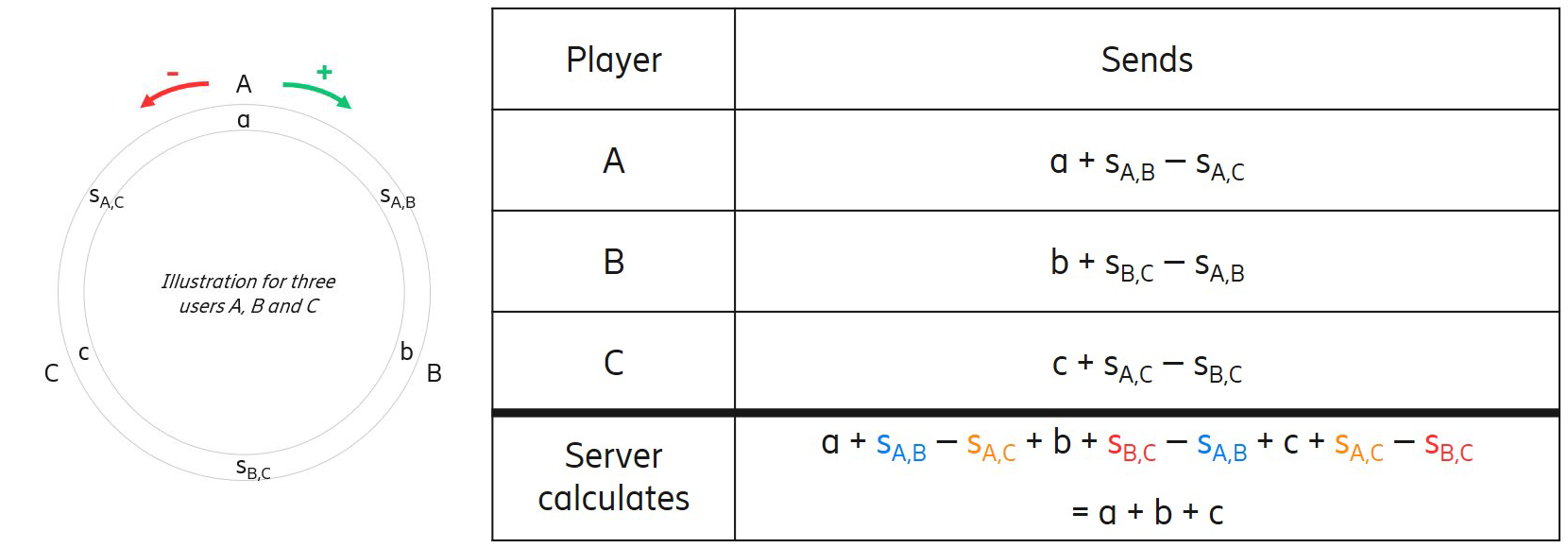
The next step for Ericsson is to test federated learning with secure aggregation, so that intermediate data summaries are not revealed to the aggregator. The figure below provides intuition behind the secure aggregation protocol.
Primary goal
- Suppose we have a number of users A, B, C, . . . who each have a secret a, b, c, . . .
- We want to calculate (a + b + c + . . .) at some central server in a way that nobody sees the individual values, not even the server
Threat model
- We want to keep individual values secure
- The final sum will be known to the server (then possibly released)
- No protection against a client lying about his value to make an incorrect sum
Approach - Masking contributions by adding random values
- Each pair of U and V coordinate to generate a shared secret random number su,v known only to them
- Mask contribution by adding and subtracting these values
Click to see the enlarged graph
Read more
The MC2 project is going in an exciting direction. We’ll continue to work on a variety of tools for privacy-preserving machine learning.
Please check out our project page for updates!