How to tackle air quality prediction using machine learning
Principal Researcher, AI systems
Principal Researcher, AI systems
Principal Researcher, AI systems
The use of statistical methods to estimate or predict the behavior of a phenomenon in the future has been common practice in many disciplines such as health care, trading, auto insurance and customer relationship management. The goal of these methods is not necessarily the prediction of the exact outcome, but a determination of the likelihood of different outcomes, since in that case one can prepare accordingly. Machine learning has further empowered such methods, allowing them to become even more accurate by using more data and additional computation.
Still, getting access to such data can be problematic in different cases for three main reasons:
- Volume: it can be very expensive to transfer such information since that can be taxing on network resources.
- Privacy: the information that is collected can be sensitive privacy-wise; whatever process has access to such data is exposed to specific details belonging to different individuals.
- Legislation: in certain countries, data concerning the constituents of that country is not allowed to be moved outside the country for legal reasons.
Predictive models require lots of data, which can be problematic since storing such data is expensive and transferring such data can create a significant load on networks.
What if there was a method that would allow for the training of predictive models without the need to transfer needed data in its original raw form.
To tackle this challenge, we collaborated with Uppsala University in Sweden, in the scope of a Computer Science project course that is part of their curriculum. Student projects are a regular part of our research work, which allow us to explore specific technology areas while also nurturing important relations with academia.
Air quality prediction
This year, we decided to set our sights on air quality prediction. Obviously, poor air quality has severe effects on people’s health. If we can predict air quality, we can adjust our behavior on different levels ranging from individual behavior to communities, to nations and even globally. One such example is Beijing where in the case of poor air quality, coal factories are suspending their operation.
Predicting air quality is a challenging problem since air quality can differ significantly from one place to another – from quiet residential areas and parks to busy streets and industrial areas. We also need to consider atmospheric patterns such as rain, air pressure, temperature, etc., which affect the volume of each pollutant in the air. The data collected can be used beyond studying air quality; we can aspire towards predictive methods that can help us proactively determine different measures that we can take that could improve air quality and/or shield sensitive groups from its effects.

Learn more on federated learning
Read the Ericsson Technology Review article, Privacy-aware machine learning with low network footprint.
Click herePutting predictive models to the test
The goal of the project was to depart from the use of centralized data – large aggregations of data from multiple air quality monitoring stations. That is the usual approach for training supervised machine learning models, but it requires the transfer and aggregation of large volumes of raw data.
Instead, the students investigated federated learning which enables a machine learning model to be trained at each station and thereafter combine such models using federated averaging.

Our article Privacy-aware machine learning with low network footprint describes the benefits of federated learning in telecommunications. Since only the parameters of the predictive models are transferred, this can decrease the volume of traffic in the network.
In the scope of this project, we envisioned a decentralized setup consisting of multiple air quality stations where each station would collect data for a specific area, have compute capabilities that would enable it to train a predictive model using locally collected data and communicate with other air quality stations.
Since such a setup does not yet exist, the students simulated it by looking into measurements collected by the Swedish Meteorological and Hydrological Institute (SMHI). Even though that was a centralized dataset, the students divided it per weather station (Stockholm E4/E20 Lilla Essingen, Stockholm Sveavägen 59, Stockholm Hornsgatan 108, and Stockholm Torkel Knutssonsgatan) and trained four individual models which were later aggregated via federated averaging.
Validating results always requires a baseline for comparison. In this case, a high performing centralized model was developed to validate against the federated models. Each student worked on the same train/test/validation dataset but explored it in different ways, using different features and different machine learning model architectures. Testing such models in parallel and evaluating them based on their accuracy – Symmetric Mean Absolute Percentage Error (SMAPE) and Mean Absolute Error (MAE) to be exact – enabled the students to cover a large area of different settings and converge to a high performing centralized model.
Outcome
10 input features were used as input to the machine learning model which was trained by the students:
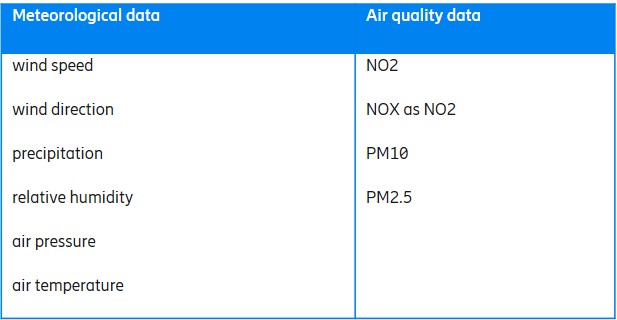
Different models were implemented including Long Short-Term Memory Networks (LSTM) and Deep Neural Networks (DNNs) to predict the next 1, 6, and 24 hours.
In the centralized case, the models that aimed to predict the next hour performed on average better than those that aimed at predicting the next day. Scores ranged from 0.282 to 0.5214 SMAPE and 0.22 to 0.47 MAE.
On the federated model side, similar MAE scores were observed, which shows that the decentralized setup we originally envisioned could be supported by decentralized training techniques such as federated learning.
If you want to dig into details, check out the project reports from the two project groups. You can find all about the implementation on our Decentralized Air quality Monitoring and Prediction GitHub.
Round off
Ericsson Research and Uppsala University have a long history of collaboration within the scope of the Computer Science project course, which is basically where we, the industry, get to pitch a challenging problem to a group of brave students. Within this premise, our guidance combined with the supervision provided by the university enables the students to self-organize and tackle this challenge. This usually entails embracing the SCRUM way of working, putting a lot of effort on the development of a working prototype, letting off some steam at a social event and finally sharing the codebase and the project report to make this work available to others.

The student teams from Uppsala University met with their teaching assistants and Ericsson supervisor Konstantinos Vandikas on Teams
But this year was different. As a result of the COVID-19 pandemic, the entire course needed to be handled remotely. This posed an interesting challenge since the students did not get to be in the same room and enjoy working side by side on this task and getting to know each other while whiteboarding. Instead, they needed to do it all remotely, including the social event. To handle this productively, the teaching assistants implemented a small competition – a mini version of Kaggle, which enabled the students to compete by trying out different hypermeters when tuning their predictive models.
Towards the creation of a more sustainable planet, it’s great to see how techniques such as federated learning can contribute, not only by simplifying and improving the process of training a machine learning model and its overall lifecycle management, but also how it can improve the quality of people’s lives through air quality prediction. We anticipate more applications of federated learning and other techniques contributing towards that goal.
Learn more
Read project report from group 1
Read the project report from group 2
Learn details of the implementation on our Decentralized Air quality Monitoring and Prediction GitHub.
Explore how ICT including AI help pioneer a sustainable future.