Telecom troubleshooting: Introducing a new recommender system for trouble report tickets
Principal AI Technology Leader, Business area cloud and software services
Data Scientist at GAIA
Applied Researcher in Tractable AI
Principal AI Technology Leader, Business area cloud and software services
Data Scientist at GAIA
Applied Researcher in Tractable AI
Principal AI Technology Leader, Business area cloud and software services
Data Scientist at GAIA
Applied Researcher in Tractable AI
Manually troubleshooting the complex software and hardware infrastructure in modern telecommunication systems is often a slow process. As many of the failures may lead to service downtime or reduced customer satisfaction, they must be quickly detected, identified, and resolved.
Usually, when engineers observe a fault in a running system that they cannot solve on site, they create a Trouble Report (TR) to track the information regarding the detection, characteristics, and an eventual resolution of the problem. Traditionally, steps in the process of troubleshooting TR tickets are not automated and are done using human expertise, as depicted in Figure 1. With today’s impressive development in machine learning, specifically in Natural Language Processing (NLP), we can automate some steps and consequently shorten the process by analyzing historical TR data and infer a solution to new problems faster and more accurately. To do that, we are proposing a solution that consists of ranking past TRs with respect to their relevance to a new problem. For that, first we need to understand the text-ranking problem.
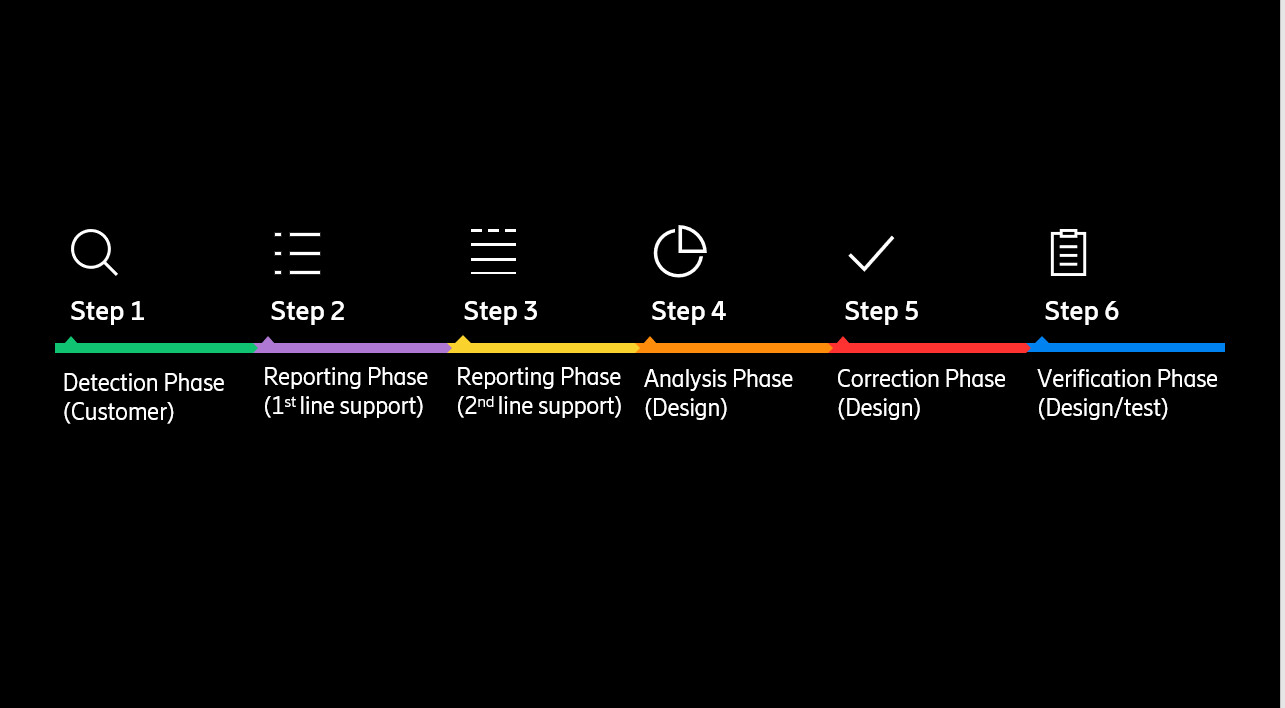
Figure 1: Steps of a troubleshooting process.
The Text-Ranking problem
The text-ranking problem can be defined as generating an ordered set of texts retrieved from a corpus of documents in response to a query for a particular task. A diagram representing the problem can be seen in Figure 2.
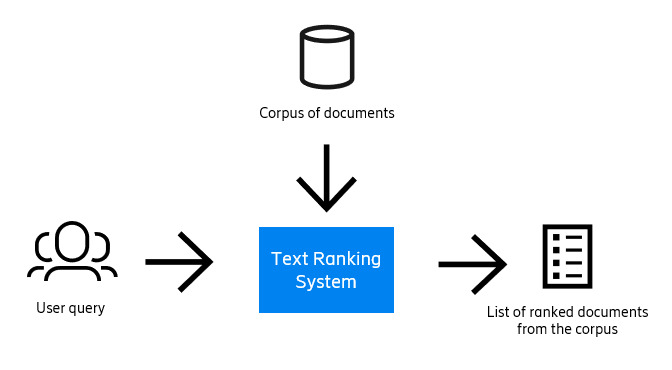
Figure 2: Diagram of the text-ranking problem.
The main elements are first the query, which is a text that explains a problem that has occurred. Then we have the corpus of documents, which is a collection of solutions from past TRs. And finally, we have the output, which is a ranked list of the most relevant solutions from past TRs to the query.
Nowadays, there are many techniques for text ranking, which are summarized in Figure 3. They are divided between BERT-based and Pre-BERT methods. BERT is a transformer-based machine learning technique for natural language processing (NLP) pre-training developed by Google. The BERT-based methods are much more accurate because of semantic understanding of the text but have high latency, while the pre-BERT techniques are very fast but lack accuracy.

Figure 3: State-of-the-art techniques for text ranking.
BERTicsson
We present a model for retrieving accurate solutions to newly reported problems in telecommunication with low latency. It’s a recommender and text-ranking model that is composed of three stages (see Figure 4):
- The pre-processing stage that cleans the input TRs.
- The Initial Retrieval (IR) stage that retrieves a top-K candidate list of documents with answers relevant to the problem.
- The Re-Ranker (RR) stage that ranks the top-K candidate list provided by the IR and outputs the final list of ranked answers.
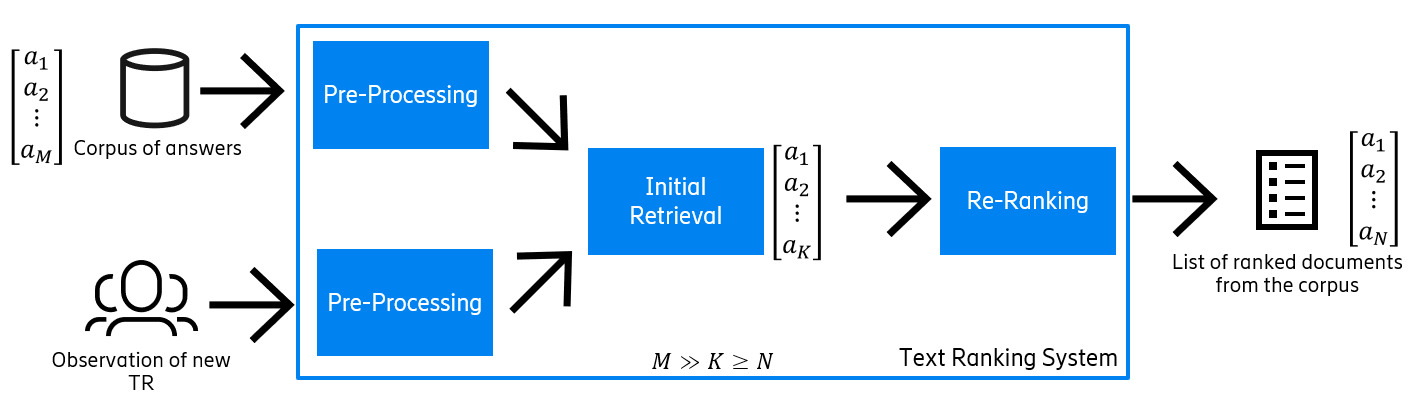
Figure 4: General overview of the architecture of BERTicsson.
The pre-processing stage prepares the data for the IR and RR stages as the text of these TRs may contain many abbreviations, typos, tables, and numerical data that make the process more difficult. The input data is a newly reported problem and corpus of documents, and the output is both the preprocessed query and the documents that are ready to be given to the IR and RR stages. It has five main steps: tokenizing text, detecting and replacing abbreviations (for example, if one of the acronyms detected is CCS, this module will substitute it for Common Channel Signaling) and handling special tokens like extra spaces, newlines, and gaps between words, as well as any punctuation signs.
The Initial Retrieval (IR) stage gets the pre-processed query and documents, and after analyzing them, creates a top-K candidate list of the most relevant documents (answers) to the query. The candidate list should have all the relevant documents to the query (if possible). However, the order of the documents in the candidate list is not important at this stage, meaning that the documents with the most relevant answers do not need to beat the first positions of the list. We use Sentence-BERT for this stage. Sentence-BERT is a representation-based model that creates the dense vectors Q and D as embeddings for the query ‘q’ and the document ‘d’, respectively. It then uses cosine similarity to compute the similarity between the Q and D (Figure 5a).
The Re-Ranker (RR) stage receives a query ‘q’ and the top-K candidate documents relevant to ‘q’ and returns the final list of top-N ranked documents (Figure 5b). The length of the final list is smaller or equal to the length of the candidate list: N ≤ K. In this stage, we use monoBERT. The input to monoBERT is composed of a query ‘q’ and a document ‘d’, the special tokens [SEP] and [CLS] in the form of “[CLS]q[SEP]d[SEP]”. Once monoBERT tokenizes the input sequence, it forwards them to the internal BERT in monoBERT to create the contextual embeddings for all the tokens. Next, it forwards the embedding of the [CLS] token to a single linear layer that outputs a scalar value indicating the probability of the document ‘d’ being relevant to the query ‘q’.
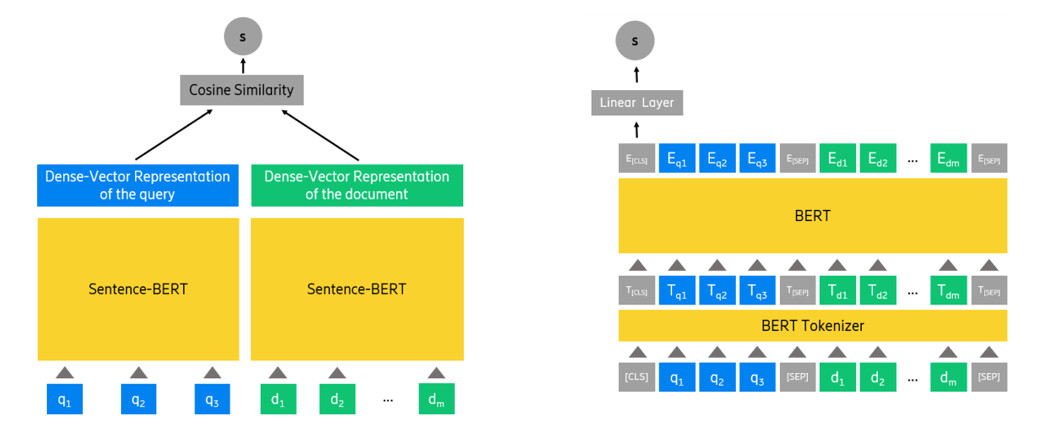
Figure 5: Architecture of the a) IR stage and b) the RR stage.
Implementation
The data we use to train and test BERTicsson is the Ericsson troubleshooting data consisting of finished 4G and 5G radio network TRs. Generally, each TR in the dataset has the following fields:
- Heading: A short sentence that gives a summary overview description of the problem.
- Observation: A longer text describing the observed behavior of a problem.
- Answer: A longer text that contains the resolution given to the fault, as well as the reason for the fault.
- Faulty Product: This is a specific code of the product on which the fault is reported. In our implementation, we create an extra field from the product name, called Faulty Area, which is mapped to the Faulty Products. This way, we can reduce the hundreds of products to a few areas that provide extra valuable information to the query.
We concatenate these sections to form the query, as Figure 6 shows.
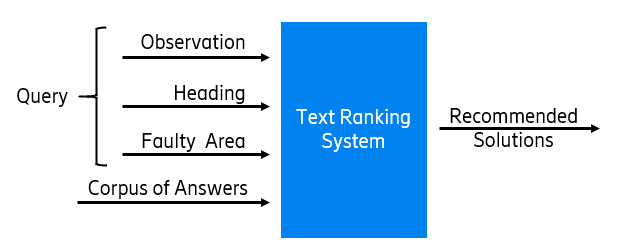
Figure 6: Sections of the TRs that form the query and the corpus of documents in BERTicsson.
Training and inference
We train the IR and the RR stages separately as each one requires different types of training. In the IR stage, we take a model pre-trained using the MSMARCO dataset which includes search queries and passages from a search engine. The model is available in the Hugging Face open-source transformers library. Then, we fine-tune it to work with telecom/company-specific data. In the RR stage, similar to the IR stage, we use a pre-trained model available in the Hugging Face library, and fine-tune it for the ranking task.
The inference phase corresponds to when the model receives a query and needs to output a ranked list of documents. When a fault is detected, a TR is submitted, and we extract the Observation, the Heading, and the Faulty Product from it. The Faulty Product is then mapped to the corresponding Faulty Area. Then, we concatenate these fields to form the query. Note that we store the representation of all the documents in the corpus after the training phase. So, during the inference time, the IR stage only needs to compute their presentation of the new query, which is a quick process. Once the representation of the new query is computed, the IR stage computes its similarity with the different documents and generates a candidate list of top-K documents for the RR stage. When the RR stage receives the top-K candidate list and the query, it processes them and creates the final ranked list, the N recommended documents to a new TR.
Evaluation
To train the model, we have used the dataset presented in the Implementation, and we have tested the model using 15 percent of all datapoints. We know the correct document (answer) for each problem (query) in the dataset, and we can check if this document is placed in a high position in the resulting recommended list. The model has been evaluated using three metrics: Recall@K, Mean Reciprocal Rank (MRR), and Normalized Discounted Cumulative Gain (nDCG).
Here are some examples of the performance of the system in the different stages.
Initial Retrieval stage results
An interesting comparison is to compare the performance of the model chosen as IR with a popular retrieval model used in many systems: BM25, which is an Exact Matching method. As we see in Table 1, Sentence-BERT outperforms BM25 by improving the Recall@1 by around 65 percent.
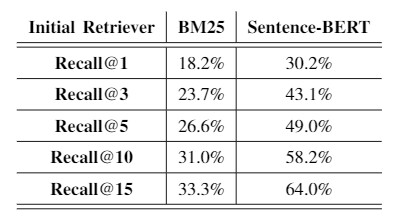
Table 1: Comparison of the results of Sentence-BERT and BM25 in the IR stage.
Other experiments have been done in this stage, like comparing two methods of forming the query and checking how the similarity scores change along the ranked list. All those experiments and more can be seen in the Learn More section below.
Re-Ranker stage results
The main experiment from the RR stage is to check if there has been an improvement from the IR stage. As we have explained, the RR stage receives a top-K candidate list from the IR stage, and then re-ranks it, such that the correct document climbs to the top of the list.
As we see in Table 2, the RR stage improves the MRR by 12 percent and nDCG by 9 percent, and increases the Recall@K (for small K); meaning that although we get the correct document from the IR stage, the RR stage improves the ranking by pushing the correct document to the top positions.
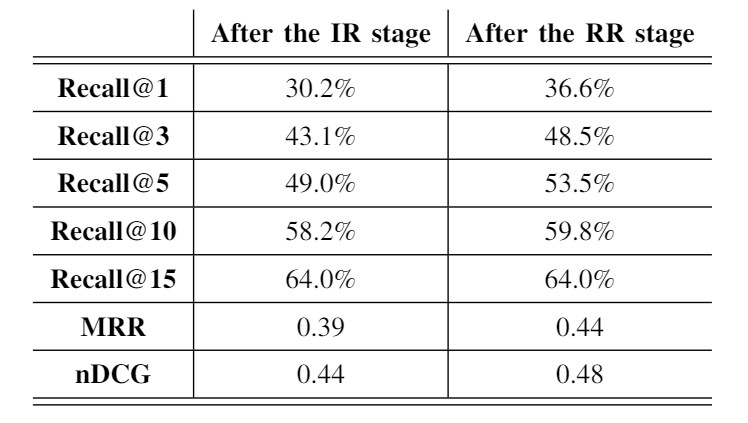
Table 2: Results of the experiment of adding the RR stage.
Latency results
Latency analysis is crucial to make sure that our system can recommend the related TRs as fast as possible to the users. Latency can be defined as the time it takes for the system to output a list of recommended answers for each query. Our proposed solution takes only 578ms on average to get the final list of ranked documents. While, if we just use the RR stage without the IR stage, then the RR stage needs to process all documents instead of just the top K, thus the latency of the model would increase to minutes just for one query.
We have compared the model latency versus the model accuracy by increasing the candidate list length from 15 documents to 50 or 100. These results can be seen in Table 3 which shows that for larger K, the increase in accuracy is minor compared to the increase in latency. Therefore, the top-15 is a reasonable size that provides a good accuracy while keeping the latency low.
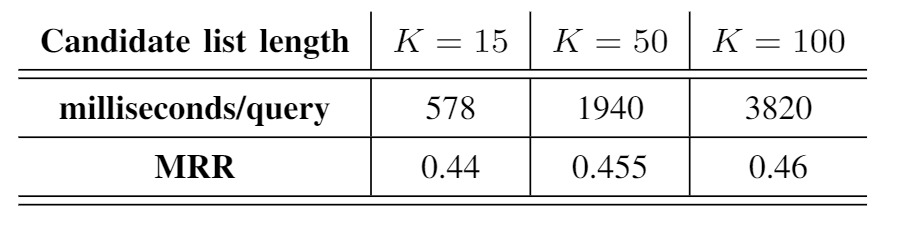
Table 3: Accuracy vs. Latency of BERTicsson.
Consistency of similar TRs
Finally, we have also evaluated whether BERTicsson can produce similar ranking lists for similar TRs expressed differently. There is a high probability that different customers individually raise different TRs for the same underlying problem. The problems are written in different words and lengths but point to a similar or equal problem. By analyzing the ranked list of our proposed model for the cases where it performs well, we see that the correct answer for similar TRs is ranked at a similar position in 70 percent of the cases.
Concluding remarks
As opposed to the manual TR solving, our proposed BERTicsson model can quickly scan and analyze thousands of previous answers and suggest the most relevant solved tickets to the requested new problem. This can provide human experts with a better opportunity to detect the root cause of the problem much faster. Moreover, our BERTicsson model in comparison with other popular NLP-based models such Exact Matching (BM25, for example) shows a better semantic understanding of the problem and can recommend the best possible solution to a new trouble report from Ericsson with higher accuracy and a much lower latency in the number of seconds.
It’s worth mentioning that the model is consistent as it recommends the same solutions to the similar trouble reports expressed differently.
Learn more
Deep dive more into the model by checking the master thesis.
Read more about AI in networks.
Connect with Serveh, Forough and Nuria on LinkedIn.
Explore 5G