Decentralized learning and intelligent automation: the key to zero-touch networks?
Senior Specialist, Artificial Intelligence
AI Researcher
AI Researcher
Senior Researcher, Artificial Intelligence
Senior AI Researcher and Project Manager
Senior Specialist, Artificial Intelligence
AI Researcher
AI Researcher
Senior Researcher, Artificial Intelligence
Senior AI Researcher and Project Manager
Senior Specialist, Artificial Intelligence
AI Researcher
AI Researcher
Senior Researcher, Artificial Intelligence
Senior AI Researcher and Project Manager
Throughout the course of history, human technological advancement has relied on collaborative intelligence. We didn’t just learn from the information around us – we communicated our learnings with others, cooperated to solve problems and even grew selective about who we would learn from or share our resources and knowledge with. These have been central factors in our learning success – and are now proving to be just as vital when it comes to machine learning (ML) for mobile networks.
Next-generation autonomous mobile networks will be complex ecosystems made up of a massive number of decentralized and intelligent network devices and nodes – network elements that may be both producing and consuming data simultaneously. If we are to realize our goal of fully automated zero-touch networks, new models of training artificial intelligence (AI) models need to be developed to accommodate these complex and diverse ecosystems.
Just like humans, all the devices and nodes with computation capabilities in a network – which we refer to as workers – will not only need to learn from local data, they will also need to communicate their learnings with each other and work together, quickly and efficiently, to make network management decisions collaboratively and autonomously.
For example, workers may collect data on the times when there are a low number of users in a network, or when there is high interference, negatively impacting communication quality. Based on this data, they may decide to switch off a cell during the times when no users are connected to it, or reduce transmission power in a particular antenna that is under-utilized for extended periods.
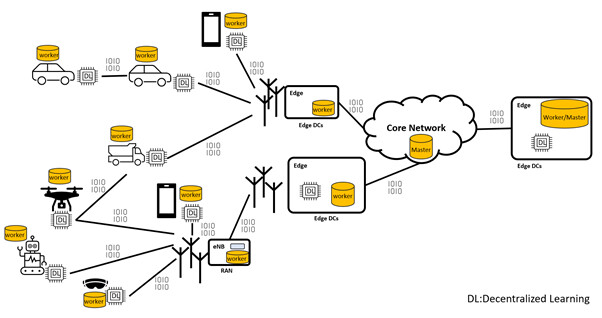
Figure 1: Decentralized future of network elements and end-devices, where workers communicate efficiently and collaboratively, learning to make accurate predictions and decisions at the right time and place for a given task.
Distributed and decentralized learning techniques
In a complex ecosystem of network elements and devices, where data are inherently distributed and can be sensitive or high-volume, distributed ML techniques are deemed the most suitable. These techniques enable collaborative model training without sharing raw data, and can be used to bring together all local learnings from inherently decentralized local datasets into one combined ML model. This jointly-trained ML model can, in turn, help the workers operate more efficiently with proactive fault-handling mechanisms – eventually improving both quality of experience and operator revenue.
Decentralized learning and collaborative artificial intelligence (AI) will allow for faster training with minimum computation and network resource allocation and enables greater efficiency – minimizing the network footprint, communication overhead and knowledge exchange as well as energy consumption. But training models for distributed learning also have complex challenges to overcome.

Addressing heterogeneity: the key challenge in distributed learning
In distributed learning settings, decentralized datasets are heterogeneous, as they are collected from different nodes and devices that are often heterogeneous themselves. They can have different properties and content, and be sampled over different distributions. For example, a base station might measure transmission power and network throughput at the cell level, while a device might measure its own position, speed, and context, as well as the presentation quality of the application it’s running – such as video freezes in an immersive multimedia streaming application. All this information is helpful and vital for accurate early predictions, optimizations, and proactive fault prevention, so all the information needs to be baked into the jointly-trained global ML model.
Some nodes or devices may also report negative contributions that reduce model performance, either intentionally, like in the case of attacks, or unintentionally, such as through data distribution shift or sensor errors. Such cases may impact the global model accuracy, while simultaneously increasing training time, energy consumption and network link utilization. The challenge of data heterogeneity can, however, be addressed with autonomous and adaptive orchestration of the learning process.
In the study explored in this post, we focus on robustness and fault-tolerance challenges in the decentralized learning process. A central part of our method is an intelligent multi-armed bandit (MAB) agent that can learn to prevent the reception of updates from erroneous or unwanted worker nodes and can therefore be used to automate the selection of workers – an approach which, to the best of our knowledge, has not previously been studied within the scope of automated collaborator selection in decentralized learning. We experimented and compared the role of MAB agents in two different decentralized learning techniques: horizontal federated learning and split learning.
Horizontal federated learning (HFL)
HFL enables the training of a joint global model that consists of different data samples on the same observation parameters – ML features in this case. Because the workers hold both the input features (X) and the output labels (y), we can perform local model training in the workers based on their individual local datasets. All workers and the master have the same model architecture, making the complete model sharable and aggregable. The following is the training procedure:
- The trained local model parameters from all workers are collected and averaged periodically at the parameter server, referred to as the master node.
- The averaged model weights are broadcast back to the workers, who then apply the received averaged weights to their model and continue their training process.
- After the training, the workers send the weights back to the master node for another average operation.
The procedure is repeated until the model reaches a steady-state accuracy level – a level where the validation accuracy does not improve further with more iterations of training.
Split learning (SL)
SL enables the development of a global model when decentralized network elements have different ML features on the same time data instance (either the same label or the same data points aggregated over the same time interval). In this setting, for example, worker nodes can contain only the input attributes (X). The corresponding label (y) is accessible only by the master server. Therefore, the worker nodes may not have the complete neural network model, but only a part of it. In addition, the worker models do not have to have the same number of layers or neurons. The final layers of worker nodes are called cut or interface layers. For SL we use the following training procedure:
- Upon a forward pass (a cascaded chain of matrix multiplication followed by non-linear transformation) of a data batch on every worker in a neural network, the final cut layer of the workers contains so-called smashed wisdom of the input attributes. These values are then transmitted to the master server.
- Since the received encoded attributes at the master server potentially come from different neural network architectures and orthogonal input features, averaging is not an option. Instead, the received values from the workers are concatenated at the first layer of the master server.
- The master server does a forward pass on the concatenated values and computes the error between the final output of its neural network layer and the actual label for the instance.
- The master server computes the neural network gradients, then does backwards propagation and updates its weights up until its first interface layer.
- The gradients are split (inverse operation of concatenation) such that each worker receives partial gradients. The received gradients at the cut layer of every worker are then used to perform backwards propagation up until their first input layer.
- The second batch of input data is fed into each worker, and the second round of training begins.
The number of required rounds for the training depends on the model convergence point. Both training and inference must be performed in a distributed manner since the worker nodes do not have access to other observations in other workers.
|
|
HFL |
SL |
|
Aggregation |
Averaging |
SGD in Neural Network |
|
What do workers receive |
Averaged neural network weights |
Split gradients (part of gradients at the interface layer) |
|
What does the master receive |
Locally-trained neural network weights |
“Smashed wisdom” (encoded transformed input features) |
|
Loss / Error computation |
Performed at worker nodes |
Performed at master node |
|
Adaptivity to worker contributions |
None |
Via neural network weights |
|
Inference |
Performed only at local workers |
Performed collaboratively both at local workers and at master server |
Table 1: The main differences between vanilla HFL and SL architecture.
In HFL, the master server consists of an aggregator which is an arithmetic average operation. In SL, the master server has a separate (split) neural network where the learnings from workers can be combined via a continued training process, for example forward and backward propagation.
MAB agents in distributed machine learning
It can be difficult to know in advance which worker in a federation helps and which jeopardizes the global model (either intentionally or unintentionally). In the use case we studied, one of the worker nodes shared erroneous values to the master server – values which were very different compared to most worker nodes in the federation. This scenario may negatively impact the jointly-trained global model, so a detection mechanism is needed at the master server to identify the malicious (or ‘poisonous’) worker and avoid including it in the federation. This way, we aim to sustain the global model performance, where the majority of the workers continue benefiting from the federation, regardless of malicious input from particular workers.
Therefore, when there is at least one worker in the federation that negatively impacts the federation, it is important to exclude that one in the updates of the global model. The methods described in existing literature are based on pre-hoc clustering, which does not allow near-real-time adaptation. In this case, we introduce MAB-based assistance to help the master server deselect any malicious worker node.
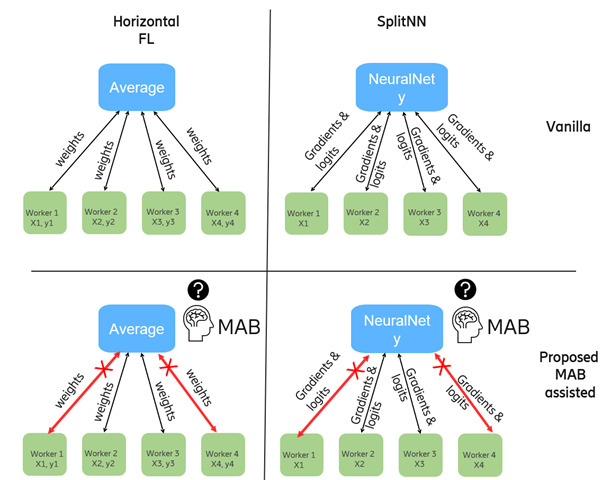
Figure 2: The four different federated learning architectures addressed in this study.
MAB is often studied in the scope of reinforcement learning. In a federated learning (FL) setting, we consider the different aggregation combinations of workers as ‘arms’. The MAB agent is located within the master server and aims to select the best combination of workers to maximize the total reward, or in other words, to model accuracy. The MAB agent is updated based on the reward obtained from each combination selection and learns to improve its selection each round.
We do not distinguish between intended and unintended non-contributing model parameter reporting, since the MAB’s worker selection is fully data-driven and based on the goal of maximizing the average model performance values of the workers in the selection, regardless of worker intention.
Empirical results: the impact of MAB agents
For both the HFL and SL experiments, a set of evaluation metrics were used including accuracy and percentage of selection. The percentage of selection metric represents the number of rounds where worker A is selected, as a percentage of the total number of training rounds.
Horizontal federated learning results
|
Scenario |
Worker 0 |
Worker 1 |
Worker 2 |
Poisonous worker |
|
All selected |
100% |
100% |
100% |
100% |
|
MAB |
56% |
61% |
62% |
10% |
Table 2: The percentage of selection of all workers in the HFL case for the two scenarios.
It is evident that in the MAB scenarios, the poisonous worker is selected less than the other workers. The impact is even more clear to see when the average frequency of selected workers is shown as a function of the round.
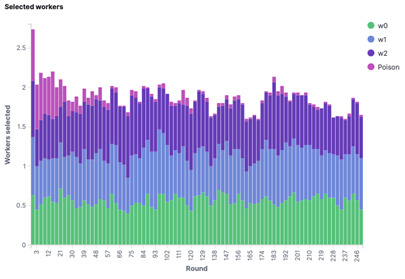
Figure 3: The average frequency of selected workers as a function of the round in the HFL case.
The poisonous worker (shown in pink) is selected more in the early rounds than in the later rounds, simply because the MAB agent doesn’t have any knowledge about the level of contribution of workers at the beginning of the training.
Without the need to send model weights to all workers every round, both evaluated MAB agents led to an estimated reduction in overhead of over 50%, both in terms of energy and communication.
|
|
FedAvg |
Epsilon Greedy |
UCB |
|
Overhead |
100% |
48% |
46% |
Table 3: Overhead in terms of energy use in workers and communication between master and worker nodes for the different evaluated methods in the HFL case.
When we visualize the model performance evaluation accuracy metric, or more specifically, the average area under the receiving operator characteristic curve (ROC AUC), of a test set throughout training, the model trained via vanilla HFL (FedAvg) quickly reaches a fairly good level of performance, which then drops due to the poisonous worker. This effect is mitigated by our proposed MAB approach in the master via both the upper confidence bound (UCB) and the epsilon greedy (eps_greedy) methods. UCB favors previously learned beneficial experiences, and it performed better than the epsilon greedy approach and sustained the model accuracy (AUC) at a higher level.
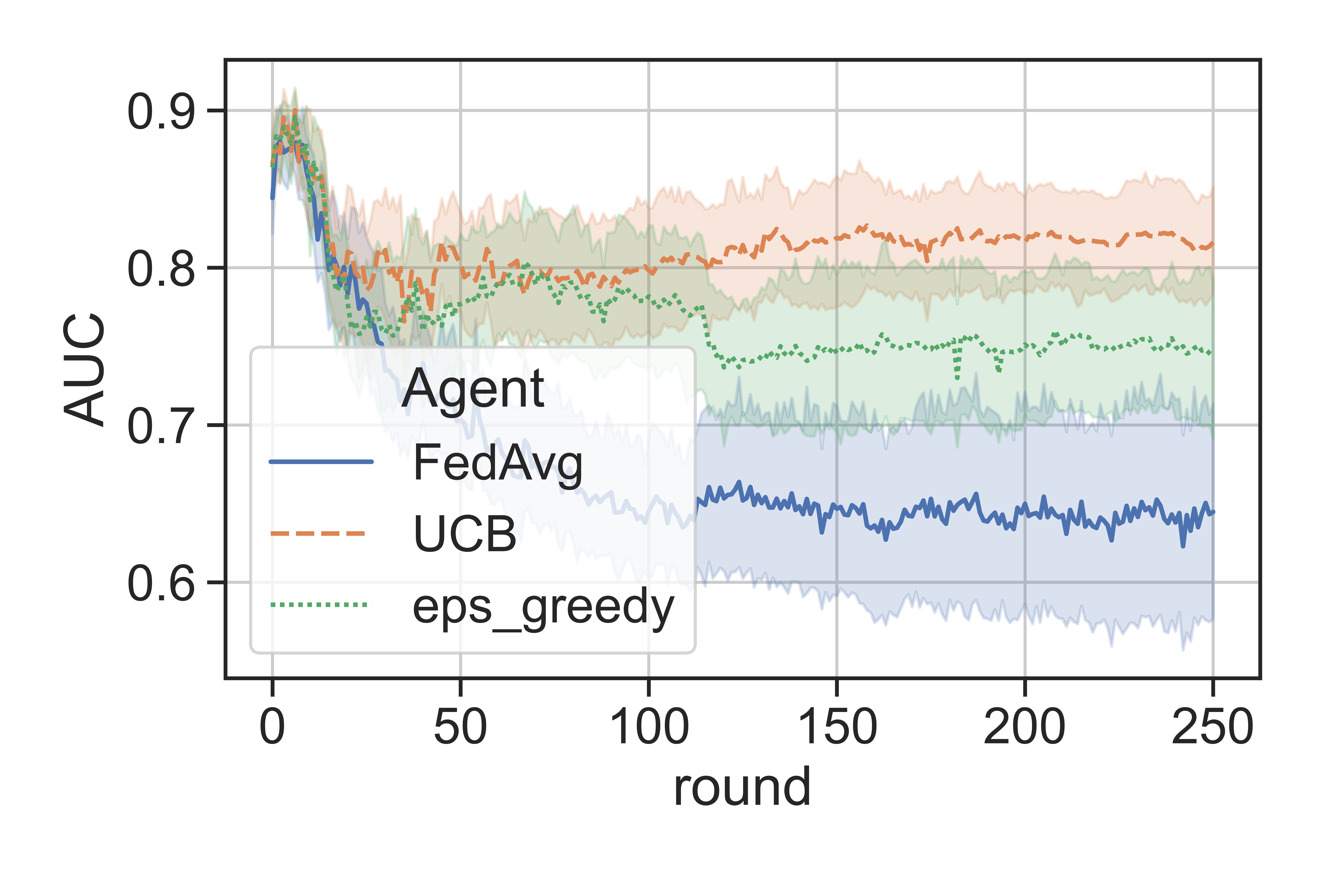
Figure 4: Average test AUC in the non-poisonous workers as a function of the round in the HFL case.
Split learning results
In the SL case, the selection percentage of the poisoned worker is statistically significantly lower than that of other workers, demonstrating that the deployed MAB agent learned to deselect the poisonous worker. Model parameters received from Worker 0 were included in the averaging 39% of the rounds, where the inclusion rate was 66%, 82%, and 83% in workers 1-3, respectively. This allowed automated feature group selection using MAB, where the feature groups that do not contribute much are selected relatively less during training.
|
Scenario |
Worker 0 (poisoned) |
Worker 1 |
Worker 2 |
Worker 3 |
Overall |
|
All selected |
100% |
100% |
100% |
100% |
100% |
|
Random |
53% |
54% |
54% |
54% |
54% |
|
MAB |
39% |
66% |
82% |
83% |
68% |
Table 4: The percentage of selection of all workers for the three scenarios – all selected, random selection, and MAB-assisted selection.
The learning curves during training and validation for the three scenarios were also visualized, with random selection (shown in green) included to depict a baseline scenario with 0.8 accuracy. The SL technique has the fastest convergence, potentially due to the existence of a trainable neural network at the master server. Eventually, with MAB-assisted Split Learning, the validation set scores converge to the same accuracy value of around 0.88, although the MAB-assisted scenario has a very slow convergence curve. Avoiding the worker computation and parameter transfer with the MAB at every round of the federation slowed down convergence. This increased convergence time neutralized the gain received from the reduced network footprint and computation. The test set accuracy values for vanilla SL (without MAB) and MAB-assisted SL were 0.94 and 0.92, respectively.
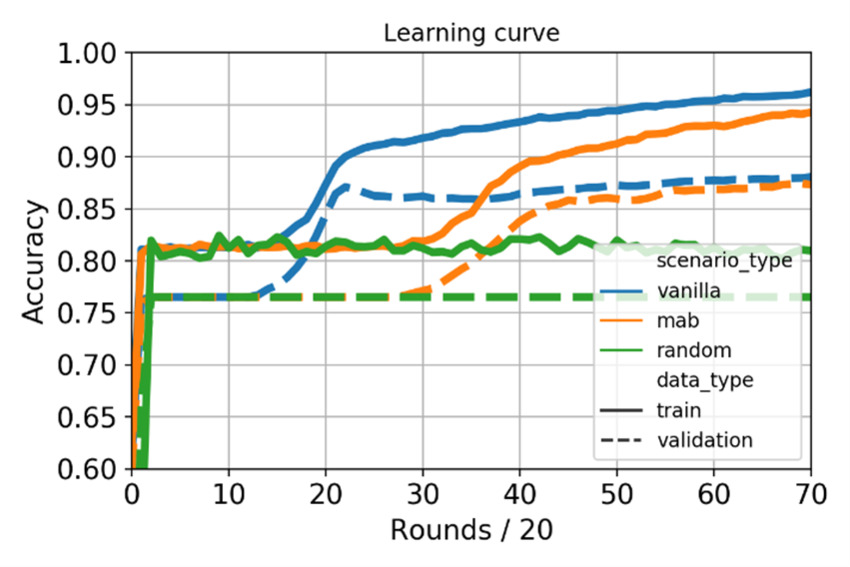
Figure 5: Learning curve on different Split Learning scenarios.
Conclusions and key takeaways
Although in HFL techniques, a master server performs an average operation on the worker model weights and has no learning capability on the level of worker contribution, our research demostrates that the overhead on the network and computation at the worker nodes can be reduced with the additional proposed MAB deployment in the master server. Efficiency can therefore be improved using this combined ML model approach.
In a SL setting, however, the master server already has a neural network that adapts its weights based on the level of input contribution received from the worker nodes to the model accuracy. Therefore, an additional MAB-based worker selector agent at the master server did not help. In fact, training time was increased due to the potential conflict between the selection of MAB and the neural network at the master server.
MAB is one of many different techniques to automate the worker selection in a distributed learning setting. While the applicability and use of MAB agents in distributed learning does depend on the choice of distributed learning model architecture and use case requirements, we believe it can be a crucial stepping-stone and enabler in the training of a distributed ML model for the next generation of decentralized mobile networks.
Acknowledgment:
Turkcell contributed to this research by providing radio network performance data and sharing experience about the model.
Further Reading:
Explore the fully-automated future of the cognitive network – no humans required.
Learn more about AI in networks