Packet reordering: The key to efficient high-speed packet processing
Senior Researcher, Cloud systems and platforms
Doctoral student KTH Royal Institute of Technology
Senior Researcher, Cloud systems and platforms
Doctoral student KTH Royal Institute of Technology
Senior Researcher, Cloud systems and platforms
Doctoral student KTH Royal Institute of Technology
Network data rates are expected to increase tremendously thanks to capabilities opened up by 5G networks, the evolution to 5G Advanced and later 6G and the availability of multi-hundred-gigabit network equipment. This transformation toward faster network speeds will make realizing low-latency Internet services more challenging. Web servers, data storage and network functions virtualization (NFV) servers demand the performance of many hardware and software optimizations to be able to keep up with the higher request and packet rates.
Tackling these challenges requires paying more attention to fast cache memories available on commodity hardware and exploiting them better. Previous blog posts showed that performing careful cache-aware memory management and whole-stack software optimizations could significantly improve the performance of high-speed NFV service chains, one of the fundamental building blocks of the Internet.
In continued joint research, Ericsson and KTH Royal Institute of Technology further investigated the correlation between the network traffic order and the benefits of cache memories.
Optimal utilization of cache memories happens when packets requiring the same type of processing (for example packets belonging to the same flow) arrive as close as possible in time and space to each other. That way, those packets access the same set of instructions and data before they get evicted from the cache memories.
Real-world traffic, however, typically causes packets requiring the same type of processing to be interleaved by other packets.
- For instance, packets belonging to a client’s flow often get spaced apart due to multiplexing of different traffic flows on the Internet.
- Additionally, recent congestion control mechanisms also favor spreading per-flow packets to minimize network congestion.
Therefore, real-world traffic often lacks the preferred traffic locality, which is desirable for maximizing the benefits of cache memories. In fact, our analysis of a KTH campus trace demonstrates that more than 60 percent of the packets belonging to the same flow are interleaved with packets belonging to other flows, which is far from ideal conditions for cache-optimized packet processing.
To overcome this issue, we built a system that reorders packets within a small time frame to increase traffic locality. In more detail, it deinterleaves per-flow packets and builds batches of packets belonging to the same flow. Our research collaboration resulted in the conference publication Packet Order Matters! Improving Application Performance by Deliberately Delaying Packets, which received the community award at the NSDI ‘22 for sharing software and reproducible results.
Let’s briefly summarize this work aiming to reorder the network traffic.
Impact of packet order
We studied the impact of traffic locality on a set of networking applications deployed on Linux and kernel-bypass frameworks, including iperf, Open vSwitch, and various network functions. Our study indicates that traffic locality (or packet ordering) significantly affects the performance of networking applications. More specifically, traffic with poor locality cannot benefit from cache memories to any great extent, which results in suboptimal performance (for example throughput, latency, and CPU utilization). Figure 1 shows the correlation between the throughput of two stateful network functions when traffic locality increases. The spatial locality factor specifies the average number of packets, in the same flow, that arrive back-to-back at the server running the network functions. These results illustrate that slightly increasing traffic locality can significantly improve throughput.
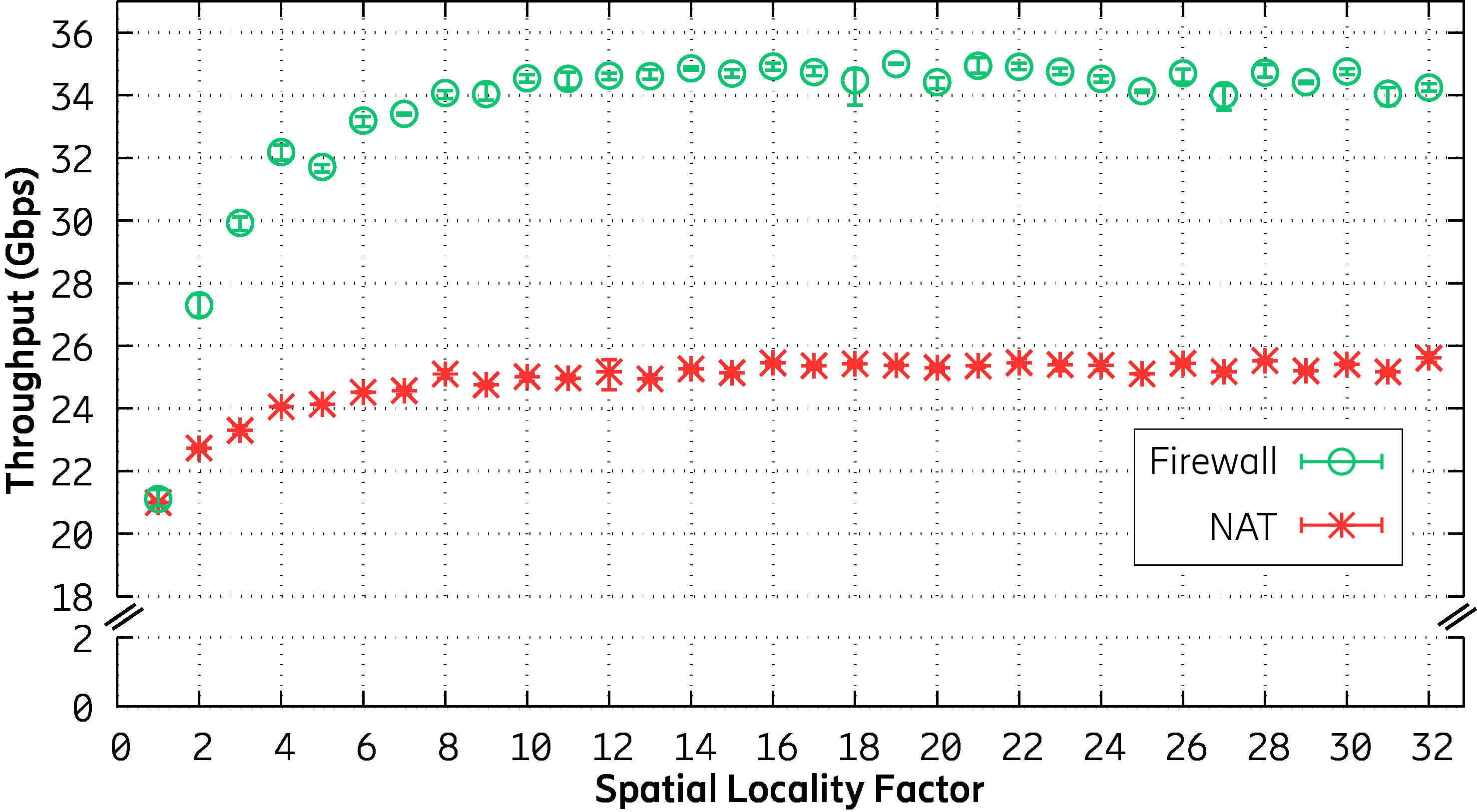
Figure 1. Increasing the traffic locality improves the throughput.
Improving application performance by deliberately delaying packets
Our analysis of the KTH campus trace showed the possibility of reordering/sorting the packets within a small microsecond-scale time frame. We explored the counter-intuitive idea of improving performance by deliberately delaying and reordering packets before they reach the application servers, thus rebuilding a high-traffic locality. To do so, we built a system called Reframer, which leverages the idea of classifying, briefly delaying and reordering the incoming packets to increase traffic locality. Figure 2 shows an example of packet reordering, done by Reframer, applied to traffic destined to a data center.
Figure 2. Reframer leverages the idea of classifying, briefly delaying, and reordering the incoming packets to increase traffic locality.
Reframer performs the following primary tasks:
- Classifies the input traffic in a small flow table in order to keep track of per-flow traffic
- Flushes the classified per-flow packets in the right order based on a pre-selected timeout or burst size
- Performs protocol optimizations (for example ACK coalescing) before transmitting the ordered traffic.
We evaluated the effectiveness of Reframer for a different set of applications, such as HTTP servers and network functions. Figure 3 demonstrates one example result, where Reframer can improve the throughput of a stateful network function by 60 percent by only delaying the input traffic for 64 microseconds.
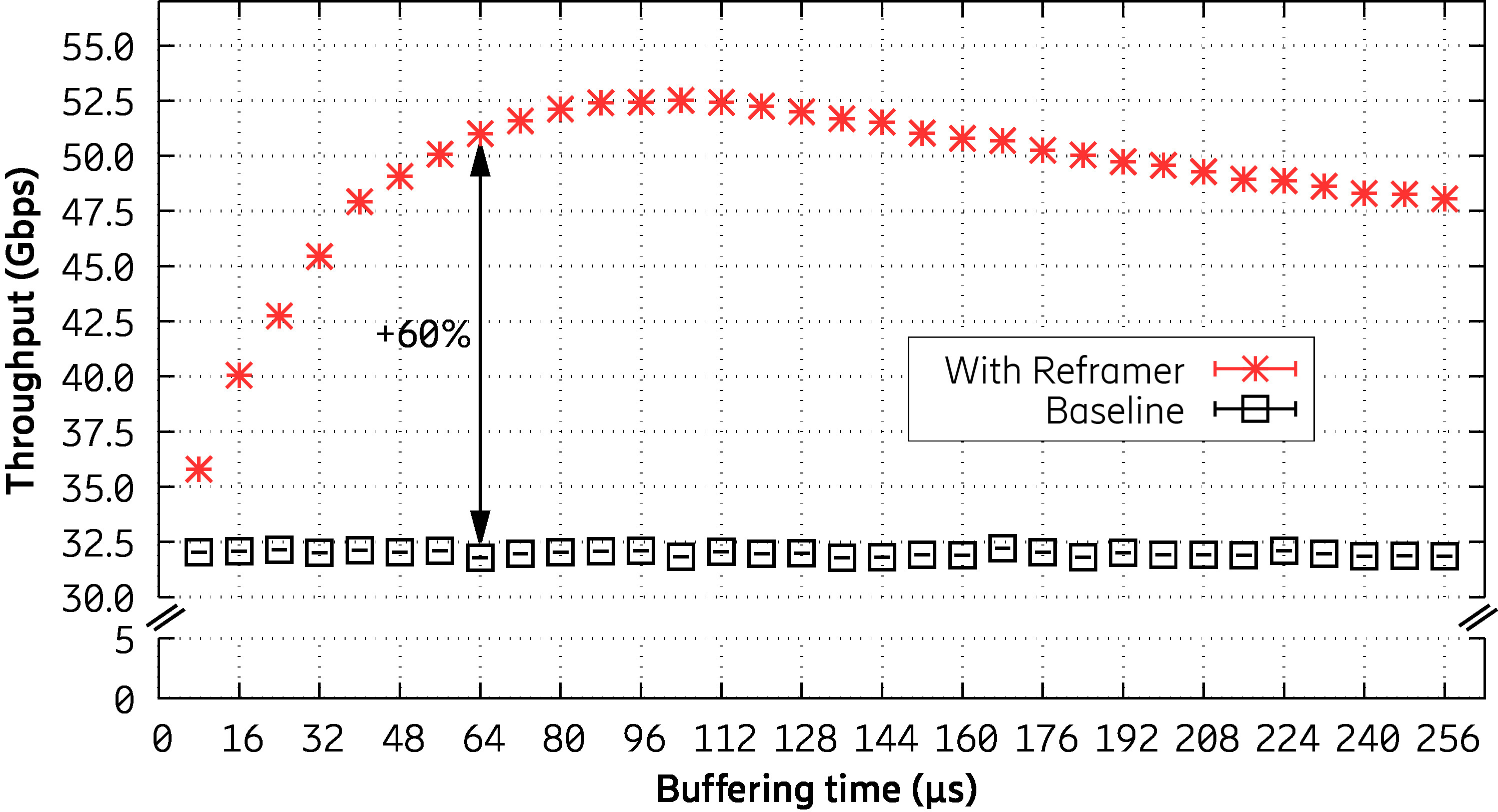
Figure 3. Reframer improves throughput by up to 60 percent by deliberately delaying packets for a short amount of time in order to reorder them.
For more information, please refer to the full paper and check out this video presentation.

Conclusion
This blog post detailed the importance of network traffic order on the performance of networking applications deployed on top of commodity hardware. We demonstrated the possibility of improving the performance of a network server by up to 3x by deliberately delaying packets and enforcing order to the traffic order. Our work further highlights the importance of performing low-level and cache-based optimizations.
Learn more:
Read the article on Energy-efficient packet processing in 5G mobile systems.
Read more about our research on the future of cloud and networking: Network compute fabric.
More about NFV.