Adopting neural language models for the telecom domain
Data Scientist within GAIA
Innovation Engineer within GAIA
Data Scientist II
Data Scientist within GAIA
Senior Specialist, Language Modeling, Business area networks
Data Scientist Manager at GAIA
Data Scientist within GAIA
Innovation Engineer within GAIA
Data Scientist II
Data Scientist within GAIA
Senior Specialist, Language Modeling, Business area networks
Data Scientist Manager at GAIA
Data Scientist within GAIA
Innovation Engineer within GAIA
Data Scientist II
Data Scientist within GAIA
Senior Specialist, Language Modeling, Business area networks
Data Scientist Manager at GAIA
What are language models?
The field of NLP combines linguistics with computer science and AI. It is concerned with the question of how to process and analyze unstructured, natural language data using machines to solve useful tasks such as named entity recognition (NER), question-answering (QA), and text classification, also known as downstream tasks.
A central concept in modern NLP is that of language models (LMs). The concept can be described as a probability distribution over sequences of words. To exemplify, consider the two sequences: "I saw a dog across the street" and "saw I dog a the across street."
A language model trained on the English language ideally outputs a higher probability for the former sequence: P ("I saw a dog across the street") > P ("saw I dog a the across street"), since the former one is a valid sentence while the second one is not.
In recent years, transformer-based language models have become the go-to approach in NLP. The transformer model itself is not restricted to the NLP domain, although that is where the architecture has found its greatest use. Similar to recurrent neural network (RNN)-based architectures, the transformer is designed to deal with sequential data. Unlike RNN-based models, however, transformers do not need to process sequential data in order. This is due to non-recurrent attention mechanisms, which replace sequential processing with matrix multiplications and therefore have the benefit of inherent parallelization and greatly reduced training times.
Well known transformer-based language models include BERT and GPT. When BERT was published in 2018, not only did it achieved state-of-the-art results on eleven NLP tasks including GLUE and SQuAD1.1, it also sparked a revolution in solidifying transfer learning from pre-trained language models as the new standard in NLP. In achieving this, BERT built on the notion of pre-trained contextualized language representations as well as the fine-tuning approach with minimal task-specific parameters, as demonstrated in the original GPT paper. This fine-tuning approach means that a pre-trained language model is trained on downstream tasks simply by fine-tuning all pre-trained parameters, as opposed to cumbersome task-specific architectures requiring training from scratch.
To further clarify, to achieve a language model fit for a downstream task such as question-answering, two training steps are performed: (1) pre-training, and (2) fine-tuning. Pre-training only requires unlabeled text, which in many cases can be easily collected from, for example, the web. Pre-training is a very elaborate and tedious process, however, in that the pre-training dataset must be large. Combined with a large model size, this makes pre-training computationally expensive. After the pre-training step, fine-tuning is performed. Fine-tuning is conducted for a specific downstream task, such as question-answering. Even though fine-tuning requires labeled data, which can be expensive to gather or annotate, this step is generally not costly, as fine-tuning on only a few thousand samples is usually enough to reach good performance levels.
A language model can be used for a variety of tasks within the telecom business, such as trouble report classification, patent prior-art search, question-answering for support engineering, and test case generation. But for this to happen, the language model must learn to understand the expressions used when talking about telecommunication.
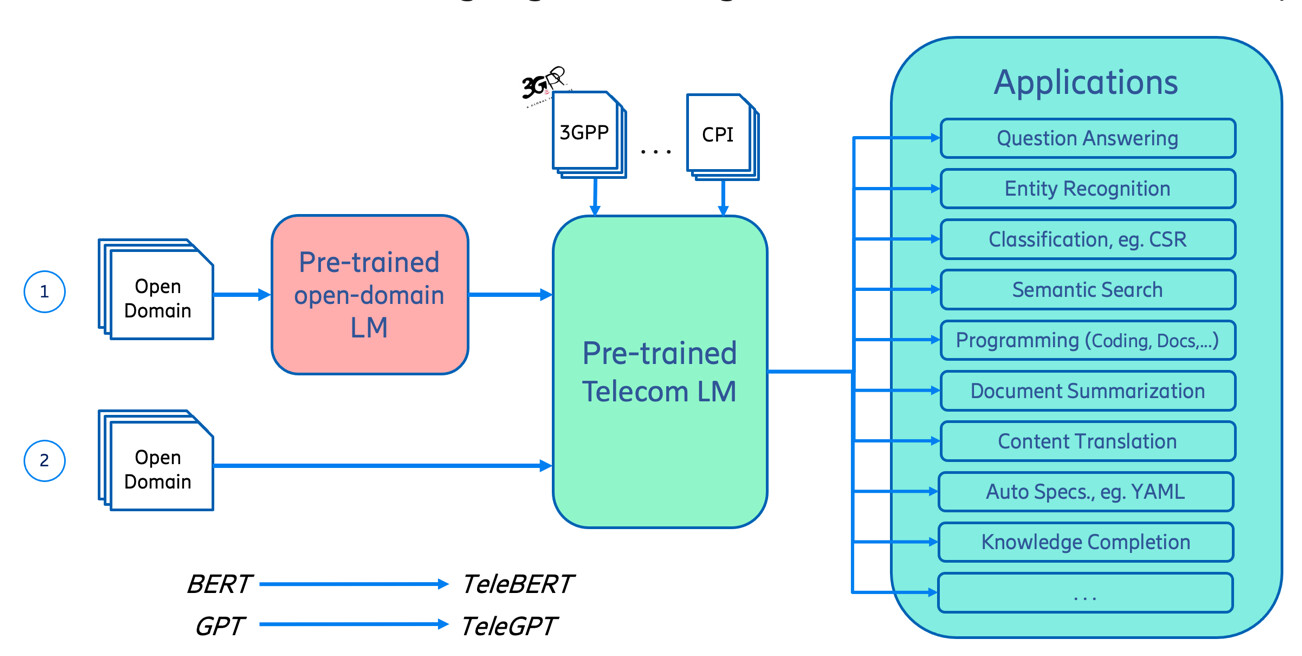
Figure 1: Overview of building language models for the telecom domain (1) adopting a general-domain model; (2) pre-training from scratch.
Telecom-specific language
In the telecom domain, there are technical terminologies, named entities, and relations among them. For example, eNB is a type of base station, user equipment (UE) is almost the same as a mobile device, and 4G and LTE refer to the same technology. Our goal has been to make a language model that can comprehend sentences where these telecom terms are used.
To train a model for telecom purposes, a large domain-specific dataset is needed. For us here at Ericsson, telecom-related information was mainly collected from specifications published by 3GPP, an organization for telecommunication standards. Additional telecom data was scraped from 3GPP and other websites, including information about mobile networks. To specifically adapt the model for Ericsson use, we also included CPIs from Ericsson and information scraped from our internal community question and answer site.
The collection of 3GPP specifications was performed using primarily Apache Tika. For content scraped from the web, the Python ‘scrapy’ library was used. The resulting unprocessed data amounted to 60GB of JSON files. The JSON files contained metadata such as data and source, as well as uncleaned contents. To clean the gathered data, heuristics for exclusion of, for example, code snippets and tabular data were developed to keep only natural language text. After cleaning, the resulting pre-training dataset amounted to roughly 21GB of text files.
With the telecom-domain data in place, it could be used to pre-train a language model. It is not necessary to pre-train from scratch, however, as there are models pre-trained on the general domain. These models possess a lot of valuable information. Even though we wanted our language model adapted to the telecom domain, the vocabulary and grammar found in general-domain data is still useful. This is the basis of transfer learning; applying gained knowledge to a new, but related, problem. Moreover, by using a transfer learning approach, we save precious time and resources, by not having to perform the whole pre-training ourselves.
To fine-tune our telecom language model on a certain downstream task, labeled data is required. This demands manual work, and the initial task that we decided on was question answering.
Evaluation benchmarks
To make the evaluation and comparison of Natural Language Understanding (NLU) systems simple and transparent, a range of benchmark datasets was developed and made publicly available. Two of the most popular are the General Language Understanding Evaluation (GLUE) benchmark and the Stanford Question Answering Dataset (SQuAD), where GLUE covers general language understanding and SQuAD focuses on question-answering specifically.
SQuAD1.1 is a collection of 100,000 question-answer pairs compiled and made publicly available in 2016. Text passages were collected from English Wikipedia. Given a passage and a question, the task is to predict the answer text span within the passage. In other words, a model should return the indices of the start and end of the answer contained within the passage.
SQuAD2.0 extends the original dataset by introducing 50,000 questions to which no answer exists in the corresponding passage. This way, the task is brought closer to a real-world setting, as systems must not only answer questions when possible, but also determine when no answer exists in the given passage.
GLUE is a collection of a variety of natural language understanding tasks. The different tasks test grammaticality judgment, sentiment analysis and semantic equivalence, among other things. To address the perceived shortcomings of GLUE, which include a lack in difficulty and low diversity in task formats, the SuperGLUE Benchmark was released, adding co-reference resolution and question-answering tasks, as well as more comprehensive human baselines.
Public benchmarks make it easy to evaluate and transparently compare the performance of NLU systems. An excess of public benchmarks also exists for niche tasks, such as the GENIA benchmark dataset for NER in text passages extracted from the realm of molecular biology. Regrettably, no such benchmarks exist for telecom-domain human language (at least not to our knowledge). Therefore, an important contribution of this project was the creation of a high-quality question-answering dataset for the telecom domain.
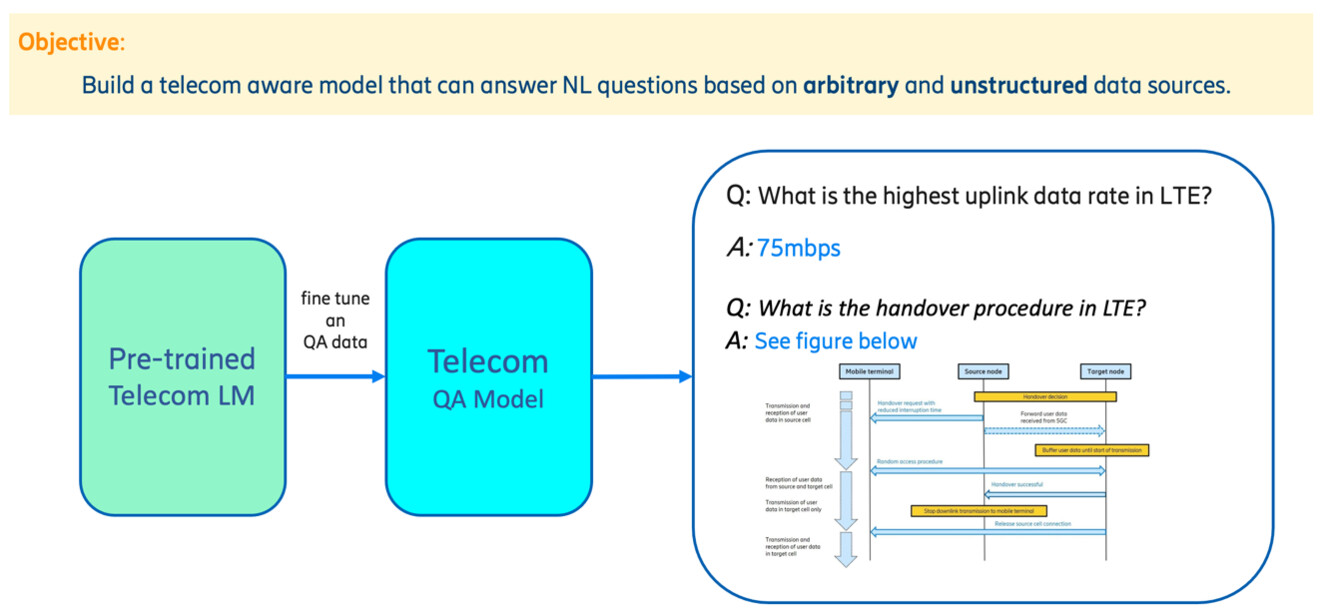
Figure 2: Using a telecom language model for question answering.
Telecom Question Answering Dataset (TeleQuAD)
We discussed the necessity of task-specific benchmarks as a way to evaluate the quality of machine learning models for a given task – without reliable and representative benchmarks it would be hard to track the progress our models. However, benchmark datasets of a given task are not necessarily generalizable across multiple domains. For example, a model that does well on the biomedical domain may not necessarily do well in telecom. Therefore, it was important to ensure that the target domain is reflected in a benchmark. To the best of our knowledge, there is no question-answering dataset that focuses on the telecom domain. Therefore, to fine-tune and evaluate for question-answering models within the telecom domain, we created a question-answering dataset from relevant content. A web-based annotation tool was developed for this purpose, and the annotations were performed by a team of ten. As data sources, we selected a few hundred high-quality documents from 3GPP specifications and other relevant articles from the web.
During annotation, a document is shown from which one needs to formulate a question where the answer is given by a text span. The text span is marked as the answer to the concerned question. As shown in Figure 3 multiple question-answer pairs were created based on the presented paragraph, in which the answer for every question was highlighted in context. For example, the annotator had asked the question “What is OFDMA?” Then they highlighted the corresponding answer in the paragraph, “Orthogonal Frequency Division Multiple Access.” This action would make up one sample in the dataset. This way of building a question-answering dataset was inspired by SQuAD, and it made our dataset compatible with existing models.

Figure 3: Examples of annotated questions and answers in TeleQuAD.
We have named the dataset TeleQuAD, short for Telecom Question Answering Dataset. It currently contains over 4,000 question-answer pairs and the number is growing due to voluntary contributions of internal employees. Our evaluation results show that significant improvements can be achieved with a dataset of this size.
To get a sense of the domain difference between TeleQuAD compared to SQuAD, see Figure 4 where the word clouds of the most frequent terms in the annotated questions and answers of each dataset are displayed with a size proportional to the rate of occurrence of the word. We see prominent in-domain terms in TeleQuAD compared to SQuAD.

Figure 4: Word clouds for SQuAD respectively TeleQuAD.
Experimental setup
Three of the language models that we have adapted to the telecom domain are RoBERTa-Base, DistilRoBERTa-Base and ELECTRA-Small. We call the resulting telecom-domain models, TeleRoBERTa, TeleDistilRoBERTa and TELECTRA, respectively.
- RoBERTa-Base is a 12-layer transformer-based model based on the RoBERTa training approach, which is more robust than the original BERT model.
- DistilRoBERTa-Base is a distilled version of RoBERTa-Base.
- ELECTRA-Small is an ELECTRA-Small model but trained with a longer maximum sequence length. Its maximum sequence length is 512 (instead of 128), which is equal to most larger models.
Pre-trained checkpoints of RoBERTa-Base, DistilRoBERTa-Base and ELECTRA-Small are available for download in the Hugging Face hub.
Due to DistilRoBERTa-Base being a distilled version of RoBERTa-Base, its memory footprint is considerably smaller than that of RoBERTa-Base. The smaller size also allows for an inference speed that’s almost twice as fast as the non-distilled parent model. Perhaps more interestingly, even though the distilled model is smaller than the RoBERTa-Base model it stems from, it comes only at a minor downgrade in downstream task performance. In other words, the distilled model is still able to leverage on the expensive training of its larger parent model.
ELECTRA-Small is even smaller than DistilRoBERTa-Base, yet shows impressive performance on downstream tasks such as question-answering. The small size combined with the ELECTRA pre-training approach makes ELECTRA-Small a good choice for both domain adaption investigations and deployment.
The telecom models introduced above were adapted to the telecom domain through continued pre-training on our 21GB of telecom-domain text data. Continued pre-training means that a pre-trained checkpoint (trained externally on general-domain data) was loaded, and then pre-trained further internally on our telecom-domain text data.
The training was performed using the PyTorch interface of the Hugging Face Transformers library. For the TELECTRA and TeleRoBERTa models, the continued pre-training ran for 100,000 steps with a batch size of eight. For the DistilRoBERTa model, the corresponding numbers are 40,000 and 32, respectively.
In the case of the question-answering downstream task, further domain adaption of the telecom models was achieved by first fine-tuning on the general-domain SQuAD2.0 dataset for two epochs, followed by additional fine-tuning on the telecom-domain TeleQuAD dev set for two epochs.
In conclusion, by leveraging already pre-trained models, we save time and money, while ensuring high performance.
Results
The evaluation metrics used in our results are the exact match (EM) and F1 score, which are the most used metrics in extractive question-answering. An EM point is given only when the predicted answer completely matches the annotated one. The F1 score for a predicted answer lies between 0 and 1, depending on how close the answer is to the annotated ground truth answer on a token level. The results are given in percentages of the EM respectively F1 score over the TeleQuAD test set.
Comparing the resulting telecom-domain models with their general-domain counterparts, the benefits of domain adaption are evident. On the telecom-domain TeleQuAD test set, EM and F1 scores increased for all telecom models compared to their general-domain baselines. For example, in the case of TeleDistilRoBERTa, the EM score saw an increase of more than 10 points. The GPU time in the table refers to the time required to run inference on the TeleQuAD test set with slightly over 2,000 samples.
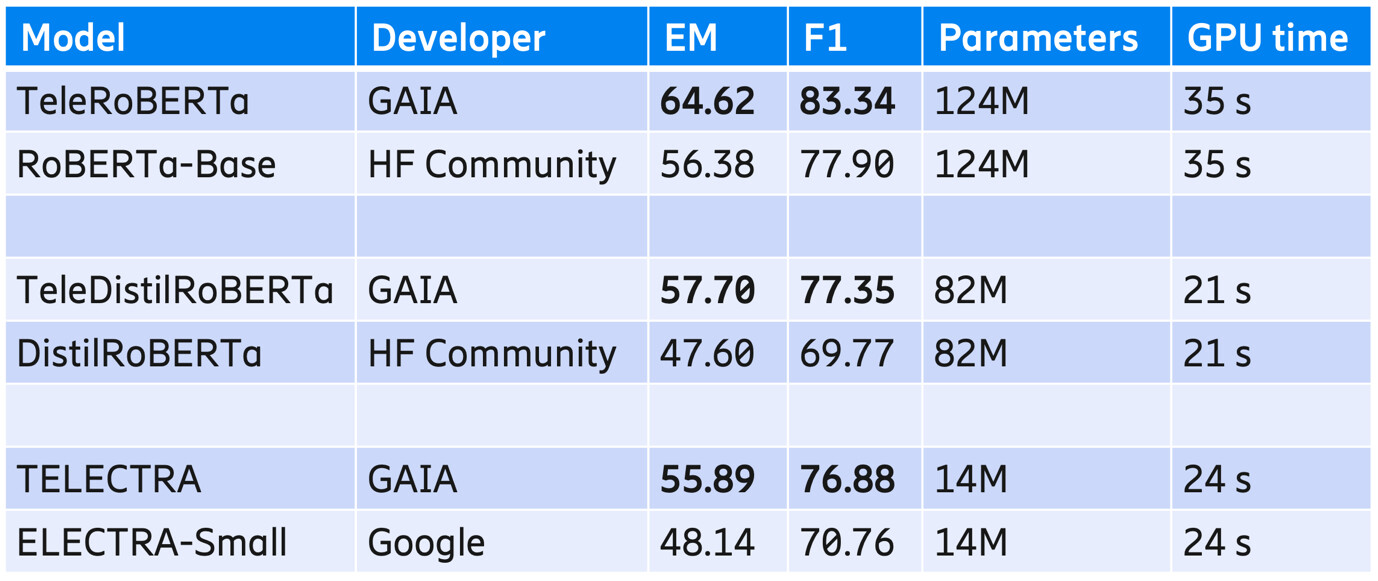
Table 1: Evaluation results for the TeleQuAD test set, model size and inference time for the respective models.
Conclusion
Language models are powerful tools that have the capacity to showcase impressive results across several downstream NLP tasks, while their application is already making significant impact in many industries.
The potential use cases for language models within the telecom industry will grow in number if the models possess knowledge about the domain. To this end, our new benchmark, TeleQuAD, makes it possible to both adapt and evaluate models for the question answering task within the telecom domain. In future work, such benchmarks could also be developed for other downstream tasks, such as entity recognition, log-analysis, classification, and summarization. Furthermore, a telecom language model could be applied to tasks as diverse as software development and infrastructure configuration, for example, code generation, debugging, and automated documentation.
Want to know more?
Read this research paper that introduced the transformer model architecture: Pdf
Read more about AI in networks.
Here’s how to automatically resolve trouble tickets with machine learning.
Read about Persona Based Search: How to perform search contextualized to a user’s persona.
Learn more about machine learning use cases: How to design ML architectures for today’s telecom systems.