AI in RAN: The inference tsunami is here
- AI in RAN is becoming indispensable for delivering scalable value across the network.
- Service providers must prepare for the coming AI inference tsunami—understanding its implications and defining data and compute strategies that maximize AI value while optimizing TCO.
Head of Performance Deployment and Intelligence
Head of Performance Deployment and Intelligence
Head of Performance Deployment and Intelligence
AI is being applied widely across the telco landscape, from radio access and core networks, to service and operational domains. As part of this topic, I wanted to share a perspective on AI being embedded within the radio access network (RAN), specifically the radio and compute fabric. As AI becomes embedded across more RAN functions, it is crucial to focus on value, scalability, and the key factors for success. Let’s break this approach down into three key areas:
- Why embedded AI: Surpassing decades of optimization
- Why communications service providers should be aware of the AI inference tsunami: Optimizing TCO
- Why a deliberate data strategy matters: Closing the observability gap
In this blog post, I’ll break down each of these three areas to help communications service providers understand what’s driving the AI inference tsunami in RAN – and how to prepare for it with the right architecture and data strategy.
1. Why embedded AI: Surpassing decades of optimization
Built on decades of cellular innovation and refined through large‑scale, real‑world deployments, today’s RAN platforms already deliver performance close to theoretical boundaries in many dimensions. Yet, even in these highly optimized environments, AI is emerging as a powerful new lever, as it unlocks further gains in performance and security, and enables new capabilities and revenue opportunities for service providers.
As with any complex system, from autonomous cars to robotics, a telco system will comprise a stack of specialized AI models, rather than just a single AI model. In RAN, AI models will range from simpler, supervised learning algorithms to more complex deep reinforcement learning (RL). For instance, decision trees can improve user device location accuracy, while reinforcement learning can optimize scheduler performance.
Talking of these very different models used in RAN, brings to mind the award-winning documentary, "AlphaGo", which showcased how an AI system developed by Google DeepMind mastered the game of “Go” and competed against the world’s top human player. Initially, it was trained using supervised learning algorithms built on human game data. However, the AI system surpassed human performance once the training switched to RL. With this approach, the AI system was no longer confined to human data, allowing it to explore new strategies and reach unprecedented levels of play.
Nevertheless, while RL shows great promise, using it in RAN is far more complex than in games like ”Go”. RAN operates in real time and under strict reliability requirements, meaning AI must be carefully controlled, built on deep domain expertise, and tightly integrated into the underlying RAN architecture.
AI-native features powered by reinforcement learning – which run in commercial networks deployed by Ericsson and are exposed to bursty traffic and real end users, rather than test users, have shown extremely encouraging results. When applying the concept of RL to algorithms embedded in RAN, the RL-based algorithms now outperform RAN algorithms that have been developed over decades.
As an example, AI‑native Link Adaptation feature delivers close to 10 percent gain in spectral efficiency over existing optimized algorithms. When I speak with C‑level executives at leading CSPs, the message is clear: spectral efficiency is directly tied to the multibillion‑dollar cost of spectrum. This makes AI‑driven improvements not just attractive, but indispensable.
2. Why service providers should be aware of the AI inference tsunami: Optimizing TCO
The development life cycle of an AI algorithm undergoes multiple stages, beginning with data collection, followed by the selection of an appropriate model, training that model, and ultimately deploying it to execute predictions or decisions – commonly referred to as “inference”. In AI economics, where does the real cost sit: in the one‑time CAPEX of training or the ongoing OPEX of running inference billions of times?
Training AI models is considered a CAPEX investment since it is extremely compute‑intensive – often 1,000 to 10,000 times more FLOPS (Floating Point Operations per Second) than that of a single inference, because training involves repeated forward and backward passes over massive datasets. However, training is done occasionally, while inference runs nonstop and at scale. Over time, serving billions of inference requests can consume more compute than training itself, turning inference efficiency and energy consumption into a critical OPEX consideration.
The surge of investment in AI inference hardware marks a broader shift in the AI ecosystem. Graphics Processing Units continue to serve as the primary workhorses for AI model training, but inference is a different challenge altogether, requiring lower latency, higher efficiency, and better cost control. The industry is increasingly building for that reality.
Zooming into AI inference in telco networks, two distinct factors stand out:
Hyper‑scale
A single 5G TDD cell handles around 7.2 million transmission time intervals (TTIs) per hour. In other words, the RAN scheduler can be invoked over 7 million times per hour on a single cell. Note that this is a simplified math estimation, since real-world behavior depends on other factors like average users per TTI.
At scale, the numbers become staggering. Data from just two metropolitan markets in the United States shows around 4.5 trillion transmissions per day. As networks transition toward AI‑native scheduling, an increasing share of these decisions can be supported by AI inference driving aggregate inference volumes into the trillions per day for a single service provider.
To put this into perspective, ChatGPT is reported to process around 2.5 billion user prompts per day globally. Even assuming roughly 200 internal inference steps per prompt, this amounts to about 500 billion inference operations per day, which is still an order of magnitude lower than the inference volume that could be experienced by just a few metropolitan RAN markets.
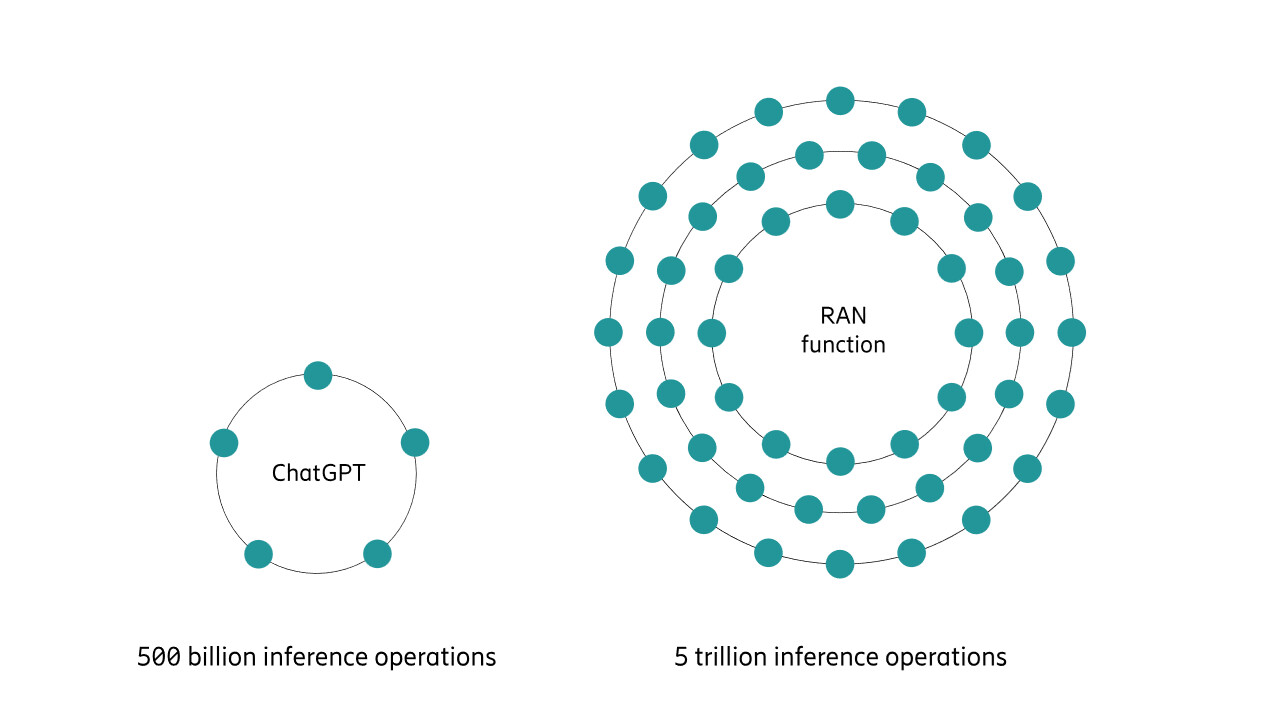
Figure 1: Example of AI inference scale in radio networks
Stringent timing
RAN operates under extremely tight time constraints, especially in the lower layers of the software stack. While upper layers can tolerate milliseconds or more, lower layers must deliver deterministic behavior within just a few tens of microseconds. This fundamentally shapes how AI can be used.
In practice, AI in time‑critical RAN layers must rely on fixed, tightly bounded models optimized for efficiency, while higher‑layer network AI can leverage deeper architectures and centralized compute. As a result, the real‑time nature of RAN significantly amplifies the challenge of AI inference compared to applications where latency is less critical and inference can be centralized.
As RAN moves toward trillions of AI inferences per day at the far edge, a critical question emerges. Is today’s RAN compute fabric ready for a world of hyper‑scale, TCO‑optimized inference?
Today’s RAN is built on compute and radio platforms that include purpose‑built Application Specific Integrated Circuits (ASICs) packed with thousands of digital signal processors (DSP) cores. These DSPs incorporate multiply-accumulate (MAC) units – the same computational “muscle” that underpins modern AI hardware, such as Graphics Processing Units and Tensor Processing Units.
Now, you must be wondering why there is such similarity between the RAN hardware and generic AI training hardware. This is because beamforming, a fundamental RAN technique which is used to focus radio signals toward individual users, has incredible structural similarity to neural network inference. Both are based on linear algebra, particularly matrix and vector operations.
Comparing early 5G Ericsson compute platforms with current‑generation units which were introduced around 2024, MAC performance has doubled, while energy consumption has been reduced by more than half. In practical terms, a single platform can support around 18–24 cells of RAN capacity per geographical radio site, while still leaving sufficient headroom for trillions of AI inference operations per second with optimal energy consumption. Beyond computing horsepower, Ericsson platforms feature on-chip memory to streamline the data path and enable deterministic, microsecond-level latency.
In addition to ASICs, both commercial off-the-shelf and purpose‑built platforms are embedding CPUs that are evolving with extremely capable AI acceleration including advanced vector extensions (AVX). While traditional CPU instructions process one value at a time, AVX can enable a single instruction to operate on multiple data elements simultaneously, making it well suited for highly vectorized workloads like AI inference.
In short, the RAN compute fabric, which is built on purpose‑designed ASICs (Ericsson Silicon) and increasingly capable, vectorized CPUs, with integrated memory already delivers the parallelism required for many AI workloads at the edge, while maximizing energy efficiency.
Ericsson´s hardware evolution, combined with optimized AI model design, enables the growing compute demands of AI inference for RAN optimization to be met within the existing network footprint without requiring fundamental changes to the underlying infrastructure.
3. Why a deliberate data strategy matters: Closing the observability gap
It is well understood that the performance of any AI model is fundamentally bound to the quality and quantity of its training data.
You may think telco networks already generate tons of metrics every day, which is true. The catch is that this telemetry is usually sampled at much coarser intervals than AI models need. While 15‑minute measurements are great for trend analysis or capacity planning, they’re far less useful for training AI models that need to react in micro‑ to millisecond timeframes in RAN.
This creates a clear gap between today’s network observability and what is required to train and run commercial‑grade embedded AI in RAN. The challenge is not just about collecting more historical data, but about capturing the right data, at the right cadence, and in the right context. Closing this gap requires a deliberate data collection strategy tailored specifically for embedded AI in RAN.
More specifically, that strategy would be driven by the following factors:
- Sampling frequency: The required data sampling frequency would vary depending on the RAN task. Some use cases demand per-transmission telemetry, while others can effectively be trained using millisecond-to-seconds level data.
- Topology: The geographical and topological scope of data collection would be closely tied to how ‘environment dependent’ the given model is. This is due to the fact that for some tasks, the behavior may vary from one cell to the next, while others may be largely agnostic to the local environment.
- High-quality data: Domain expertise will be critical to collect and curate data to ensure the data accurately reflects real-world conditions, especially ”corner-cases”. Incorrect, biased, or insufficient data that fails to represent the full range of real-world scenarios will severely impact commercial performance.
- Tailored to the AI model: Embedded AI in RAN will comprise a stack of AI models, each requiring distinct data collection strategies. While supervised models depend on large volumes of labeled historical input/output pairs, reinforcement learning relies on interaction data and feedback from the environment, shaping how data must be collected.
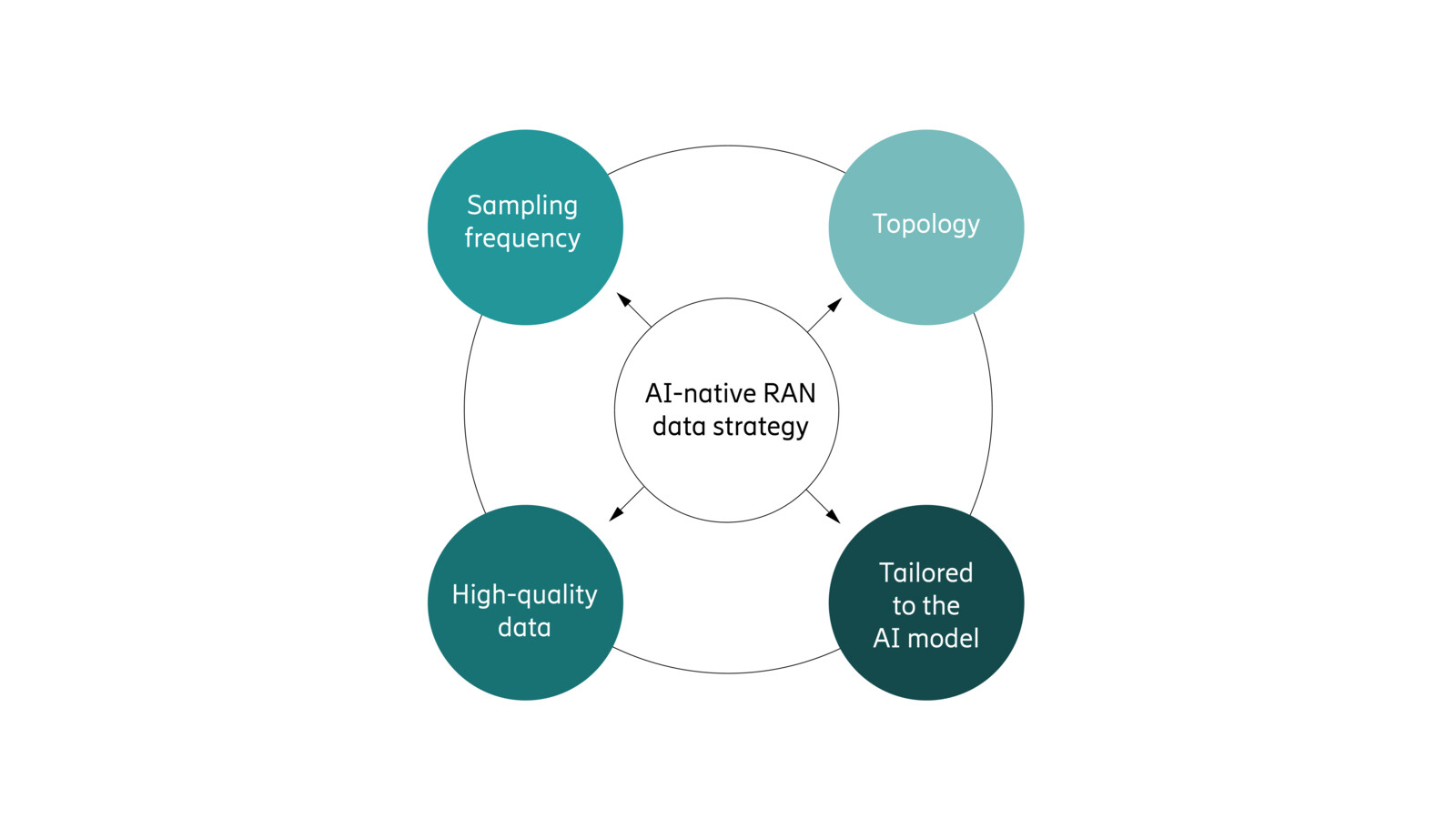
Figure 2: The four elements of a successful AI-native RAN data strategy
Closing the observability gap – from minute‑level telemetry to real‑time, AI‑grade data – is essential. Without the right tools and trusted datasets, embedded AI in RAN cannot deliver reliable, commercial‑grade performance.
The three key takeaways for service providers
- Embedded AI in RAN will comprise specialized models to meet micro to millisecond latency needs, with reinforcement learning features already outperforming long optimized traditional algorithms, making AI in RAN indispensable.
- At scale, these features will drive trillions of daily inferences, making inference OPEX the dominant cost driver. The good news is that existing RAN hardware, with purpose-built ASICs and vectorized CPUs, optimized for energy efficiency can support these workloads without major new CAPEX investments.
- Achieving commercial grade performance, however, requires far more detailed observability. This demands a deliberate data strategy with higher frequency sampling, appropriate spatial scope, and carefully curated, use case-aligned datasets.