AI Confidential: How can machine learning on encrypted data improve privacy protection?
Principal Quantum Engineer
VP and Head of Automation & AI
System Developer
Principal Quantum Engineer
VP and Head of Automation & AI
System Developer
Principal Quantum Engineer
VP and Head of Automation & AI
System Developer
Encrypting data at rest and in transit (both structured and non-structured) is already common practice within companies, to protect confidential, secret and proprietary information. Encrypting data while in use, however, is a less common practice. Data in use is data that is stored in a non-persistent digital state and/or that is being processed, like in the lifecycle of a machine learning (ML) model.
Leveraging machine learning in Human Resources (HR)
One of the interesting use cases for any HR department is to be able to reduce the employee turn-over, and its related cost, by looking into employee satisfaction. Most of the time, employee satisfaction does not come as a plain number value – so we need to infer it. This is best done by designing a ML model that learns from past experiences. For example, it can look at which conditions, or combination of conditions, drove past employees to leave the company. It can then use these conditions to predict employee churn and give companies insights into patterns and what conditions could be improved to increase staff retention.
Another use case would be to use natural language processing to do applicant – vacancy matchmaking, based on resumés. In both cases, the machine learning model needs to process sensitive personal data that requires specific treatment while in storage, in transit and in use.
Let us consider a scenario where Company A, Ericsson for example, owns the sensitive employee data. Company B, a third party, owns the specialized ML mathematical model and knowledge in the area. To utilize ML and apply it to solve Ericsson’s business challenges, both companies would need to collaborate and share data across organizational boundaries.
Due to the sensitivity of the data, Ericsson would like Company B to run the mathematical function on our (Ericsson) data without ‘seeing’ (decrypting) the data. But traditional encryption, like Advanced Encryption Standard (AES) or Rivest-Shamir-Adleman (RSA), works in such a way that the data is not usable in its encrypted state. That would mean that Company B would need to decrypt Ericsson’s data before applying their mathematical model – exposing the sensitive information. So, what is the solution?
Emerging technologies for machine learning on encrypted data
The Automation and AI team within Group IT at Ericsson is currently looking into the latest technologies as we explore ways of addressing these challenges to preserve data privacy while in use. Two of the most promising emerging protocols used for encrypting data are secure multiparty computation (SMPC) and homomorphic encryption (HE).
Secure multiparty computation (SMPC)
SMPC is the act of jointly computing a function while keeping the inputs private. This allows data scientists and analysts to compute on distributed data without ever exposing it.
From the functionality perspective there are four main steps:
- The data analyst / scientist (external to Ericsson) determines and writes the function to be performed on the data (regression, average, etc.): . The analyst is also responsible for selecting the data sources provided by the data owner. Note that the analyst never owns the data. The data owner, Ericsson in this case, spins up a virtual machine or container within the privacy zone of Ericsson Corporate Network, to access the data. The analyst only sees headers and metadata from the remote data source. After this, the analyst triggers the computation of function onto selected data.
- The algorithm’s next step is to compile the function into binary, generate random numbers and distribute both the binary and randomness to the computation engines. This means that plaintext datasets are parsed and converted into binaries for the computing engines to understand. The random numbers are used to randomize the data that is being shared between the distributed computational engines. Note that the ML algorithm is executed where the data resides, locally.
- At this stage the computing machines execute the binary data and communicate with each other, exchanging random data.
- After the computation is performed, the results are sent to the data analyst using an encryption algorithm.
This technique can be applied in fraud management use cases, where communication service providers can learn the fraud pattern from each other while preserving privacy and avoiding disclosure of their system architecture (including their architecture strengths/weaknesses).
Homomorphic encryption (HE)
HE is a method that allows analysts and data scientist to compute analytical functions on encrypted data (ciphertext) without the need of decrypting it. HE is classified in different types according to the mathematical operation types allowed and the number of times these operators can be performed. The encryption algorithm behind HE is based on the Ring-Learning with Errors problem, a highly complex (NP-hard) problem which is, as an added benefit, considered quantum-safe.
In homomorphic encryption, we define a trusted zone where the plaintext data is stored. Again, the data is within the privacy zone of Ericsson Corporate Network. In this trusted zone, data is encrypted using a homomorphic encryption scheme such as Cheon-Kim-Kim-Song (CKKS).
New technology in action
Let us return to the use case where a third party would perform resumé-job matchmaking via a cloud microservice. As the matchmaking computation is in the public cloud, we do not want the sensitive data to be unencrypted, even if we trust the third-party service provider. The public cloud would be our untrusted zone. Data between the trusted zone and the untrusted zone is moved in an homomorphically encrypted fashion, retaining the same confidentiality and security benefits as traditional encryption, with AES for example.
In the untrusted zone, the data analyst determines and writes the function to be performed on the data (regression, average, etc.): . Function is performed on the encrypted data, with no need to decrypt the data to perform the function, as is the case with other methods of encryption. The result of executing the function is encrypted by default (thus giving the entity performing the function no visibility) and sent back to the trusted zone for decryption and interpretation of the results. An illustration of this flow can be seen in Figure 1.
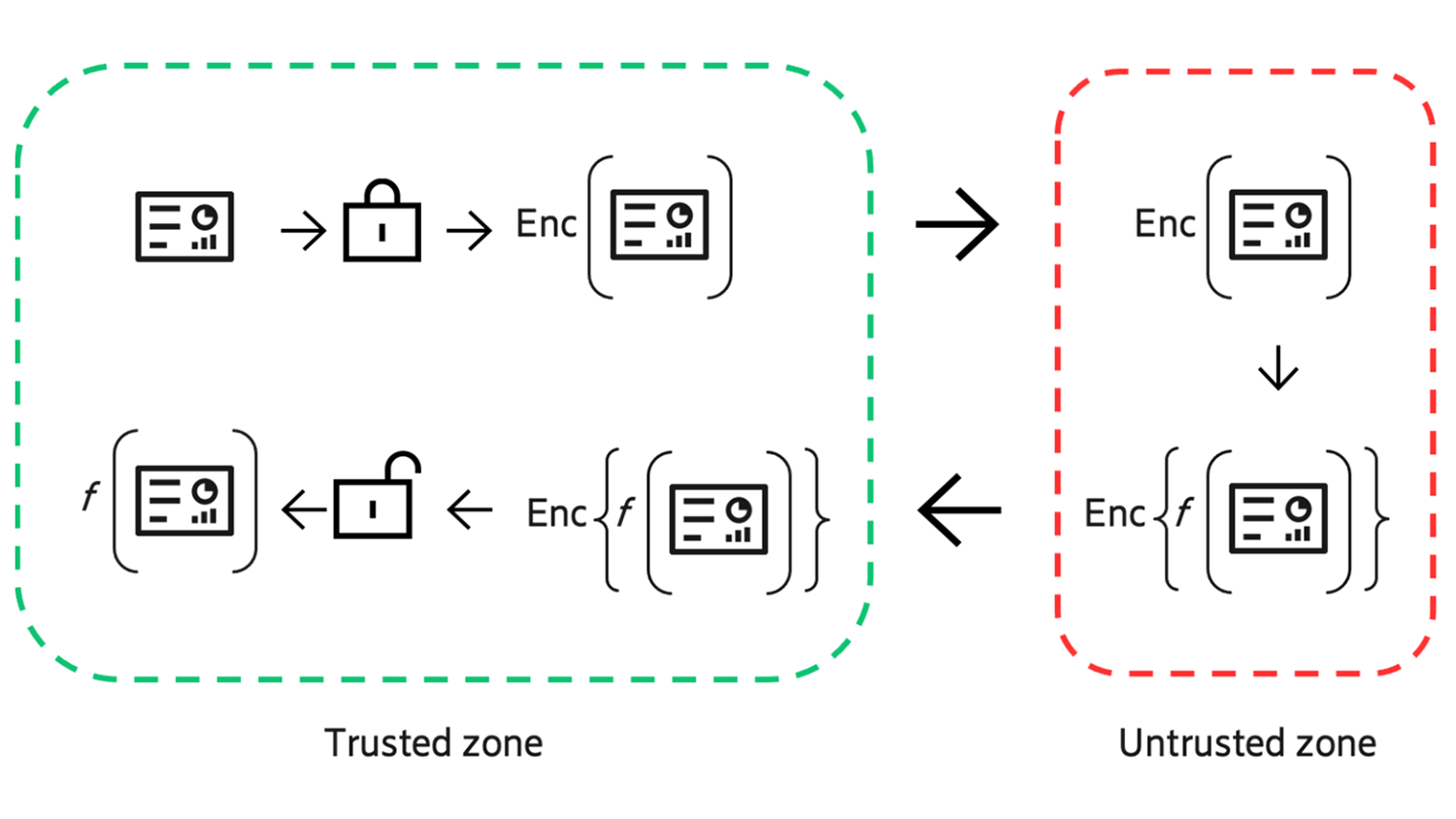
Figure 1. High level design of the homomorphic encryption execution flow. The trusted zone is the Ericsson private network. The untrusted zone represents the public cloud.
In this proposed scenario, Company B owns both the function and the compute resources, so Company A must trust Company B to operate honestly. Such trust can be built through the business and responsibility agreements such as non-disclosure agreements, where B has a commercial incentive to use the homomorphic schemes on their functions in a proper manner and fulfilling Company A’s expectations.
To validate the potential of this technique to address the business challenge of doing computations on privacy and sensitive data, a use case proof-of-concept (PoC) was implemented.
Validating proof-of-concept
The unencrypted version of this PoC is a simple Python script that trains a logistic regression model on synthetic HR data for the purpose of predicting employee churn. The trained model is then applied to a test data set in a very traditional unencrypted way, yielding an accuracy of roughly 73% churn (see Figure 2).

Figure 2. The result of unencrypted evaluation of logistic regression on HR test data
That same trained model is then hosted on an encrypted evaluation microservice, which listens for evaluation requests from clients. The client then provides an encrypted version of the data set they want to evaluate, and what model on the server they would like to use for evaluation. The server evaluates the data in a completely encrypted manner, and returns an encrypted prediction to the client, which the client can then decrypt and, among other things, calculate the accuracy for. In the case of the PoC highlighted previously, the accuracy for the encrypted evaluation was 73% (see Figure 3).
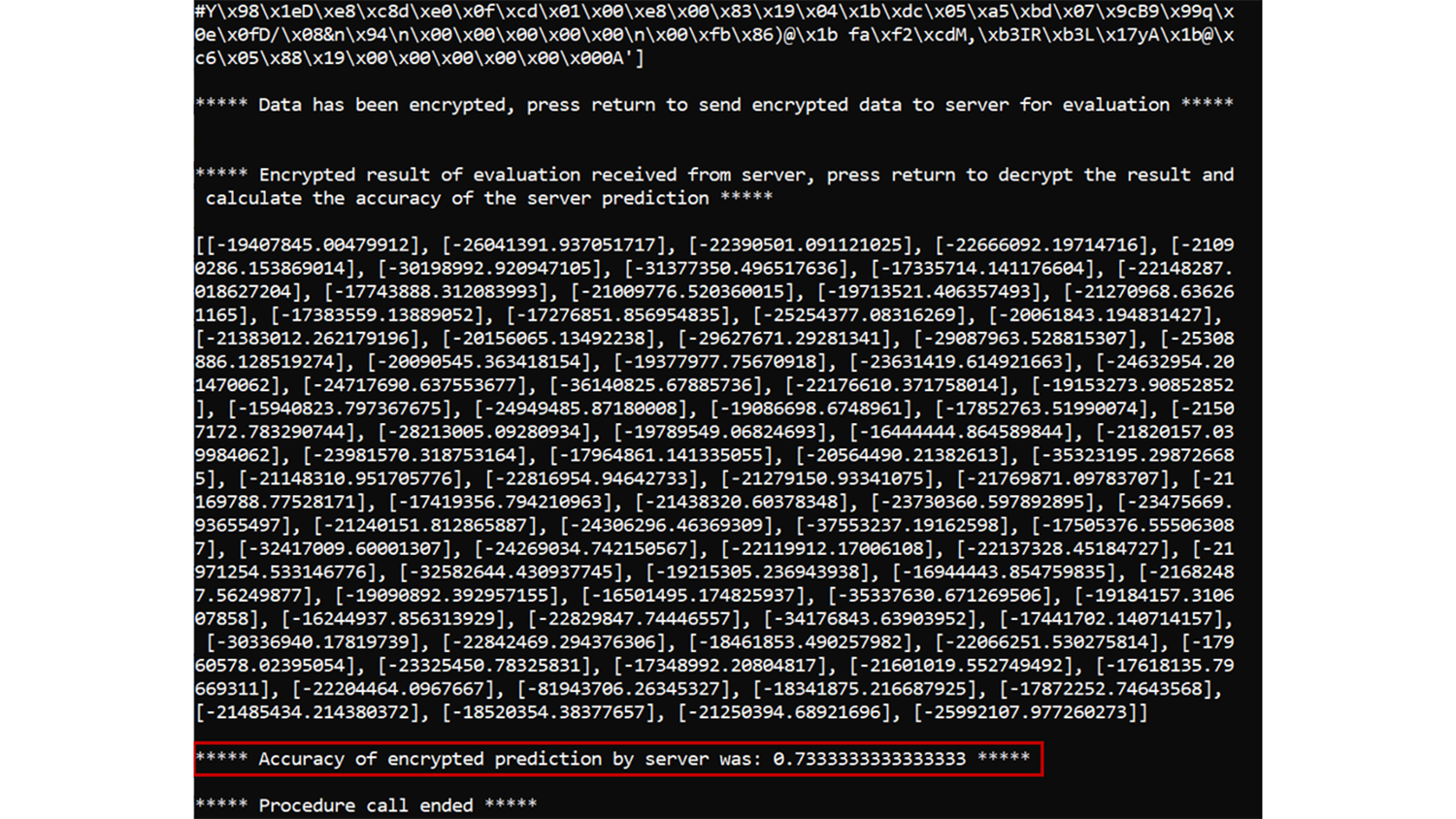
Figure 3: The result of encrypted evaluation of logistic regression on HR test data
It is important to highlight here that our server implementation managed to a) execute an ML model on the homomorphically encrypted data and b) achieve an accuracy level for the encrypted evaluation of 73%, the same as in the unencrypted (traditional ML) case. In this PoC, there is no loss in accuracy when applying homomorphic encryption on ML models with sensitive data.
Enabling a more secure, intelligent future
These two upcoming technologies both address the fast-growing need for enhanced privacy protection in business. An important distinction to make, however, is that SMPC is a large architectural framework for designing computations that can retain the privacy of the parties involved. This contrasts with HE, which is a technology that exists on a comparatively smaller scale, being used as the method of encryption in the context of larger systems or use-cases, including SMPC.
HE has the potential to complement SMPC by enhancing its privacy preserving and security properties to better withstand scenarios where more than half of the parties involved in a multiparty computation are compromised or otherwise malicious, a situation which traditional SMPC solutions struggle with.
These technologies are both expected to play an important role in Ericsson’s digitalization journey, contributing to the building of an intelligent automation engine that delivers business value every day.
Learn more
Find out more about machine learning use cases, and how to design ML architectures for today’s telecom systems.
Read our blog about managing the machine learning lifecycle.
Discover how AI and ML algorithms are transforming customer experience in telecoms.
Read more about AI in telecom networks.