Reimagining XR audio with innovative volumetric sound rendering
- In the real world, large sound sources, like waterfalls or passing trains, don’t seem to come from a single point. You can hear that they have a certain size. And, the closer you get, the bigger they sound. Virtual reality faces challenges replicating this, but we have a solution.
- Ericsson Research has developed innovative methods for volumetric audio rendering that have been adopted into the new MPEG-I Immersive Audio standard for spatial audio in XR applications.
Master Researcher, Audio technology
Master Researcher, Audio Technology
Master Researcher, Audio technology
Master Researcher, Audio Technology
Master Researcher, Audio technology
Master Researcher, Audio Technology
Imagine walking towards a forest. Initially, you hear the distant sound of wind passing through the trees. As you get closer, you hear how the sound widens. Finally, you are inside the forest, completely immersed in the sound of rustling leaves, the creaks of swaying tree trunks, and the chirps of countless birds.
The goal for an XR audio renderer is to provide a realistic and immersive audio experience for an XR scene, such as the scenario described above. As the user explores a virtual or augmented environment, every sound should align with the direction of the associated virtual object, remaining consistent even as the listener turns their head.
With the finalization of the new MPEG-I Immersive Audio standard, there is now a cross-platform and long-term stable format available for creating highly realistic and dynamic virtual audio environments that you can freely explore and interact with.
In this blog post, we describe our novel sound source rendering concept, which has been integrated into the MPEG-I Immersive Audio standard.
Binaural 3D audio rendering
In XR, sound sources might be located anywhere in the listener’s three-dimensional (3D) virtual space. Using headphones, the technology called binaural rendering allows sounds to be rendered from any desired direction around the listener, even from below or above.
Binaural rendering uses filtering to replicate how our head and outer ears modify sound waves. These filters are called head-related transfer functions (HRTF). This technique works well for creating the illusion of sound originating from a specific point in space, commonly referred to as point-source rendering.
However, certain scenarios demand sound to come from larger objects rather than a single point. This is where volumetric audio rendering comes in.
Volumetric sound sources
Volumetric audio rendering is specifically beneficial for rendering the sound of larger objects, such as a grand piano, a waterfall, or a group of cheering people. In these examples, the sound is expected to come from the whole extent of the sound source.
For instance, if we move closer to a waterfall, we expect the sound that we hear to have the same width as the waterfall that we see. It should not appear to come from a single point in the middle of the waterfall. As we get closer to the object, not only should the sound get louder but also appear wider so that it matches the geometrical width of the object as observed from the listening position. In so-called 6 Degrees of Freedom (6DoF) XR applications, the listener can often move freely around an object, and the audio rendering should be adapted correspondingly to provide a realistic sound from any listening position.
Some real sound sources consist of a multitude of small sound sources, such as the rustling sound of wind in the forest. In this case, thousands of leaves collectively produce a big compound sound. Rendering these kinds of sounds using thousands of individual point sources would be very inconvenient and inefficient. Instead, such compound sound sources can be rendered advantageously as a single volumetric sound source.

An example of a volumetric sound source representing the sound of a forest, where the extent is defined with a mesh shape. Source: Test scene created in Unity
Special characteristics of volumetric sound sources
The main feature of volumetric sound sources is that they can provide the impression of a sound source that has a certain size and shape. Let us also look at some other characteristics that set them apart from ordinary point sources.
- The sound inside a sound source
In contrast to point sources, the listener can sometimes be positioned inside a volumetric sound source. In practice, the user might not always be able to enter the sound source, but in some cases, this may be an important feature – such as with a volumetric sound source representing the ambient sound of a forest, a large fountain, or a crowd of people the listener can step into and move through. - Distance attenuation
A key difference between volumetric and point sources is how the sound level changes with distance.
The point source follows the 1/r distance law, where r represents the distance, meaning that the sound level is inversely proportional to the distance to the source. In contrast, when a source has a significant size, the level-vs-distance curve is non-linear. At short distances, the rate of decay is more gradual compared to a point source, while the rate is similar to a point source at relatively large distances. - Occlusion
Occlusion happens when a sound source is hidden, either completely or partly, by an object that blocks the direct path to the listener’s position. For point sources, a single line-of-sight check is sufficient to see if the sound source is occluded. For a volumetric sound source, the situation is more complex, as it can also be only partly occluded.
The occlusion can be soft, meaning that a part of the sound can pass through the occluding object. For example, a curtain may suppress the higher frequencies but allow the lower frequencies to pass through unaffected.
Heterogeneous spatially extended sound sources

In a piano, the individual strings are spatially distributed, so when you stand in front of the instrument, the lower strings are heard more to the left and the higher strings to the right. In the case of wind blowing through the trees in a forest, the sound of all the individual leaves creates a big, compound, spatially extended sound, coming from all directions.
These types of sound sources, characterized by non-uniform spatial audio characteristics, are referred to as heterogeneous spatially extended sound sources – or simply heterogeneous sound sources – a concept we developed to advance volumetric audio rendering and contributed to the new MPEG-I Immersive Audio standard.
Representation of heterogeneous sound sources
Now, let’s go into more technical details of this new concept.
The heterogeneous sound sources are defined by two elements:
- a geometric representation of their shape ("spatial extent"), for example in the form of a mesh or a basic shape such as a box
- a multi-channel source signal
Using a multi-channel source signal makes it possible to represent audio sources that have a non-uniform spatial audio characteristic with more spatial detail and dynamics compared to using just a single-channel source signal. In the example of the piano, a multi-channel recording can capture the spatial distribution of the sound of the strings. In the case of the rustling sound of wind in the trees, a multi-channel recording can capture the direction of the sound from every individual leaf.
If the listener is positioned inside the heterogeneous sound source, an interior representation of the sound source is rendered, which completely encompasses the listener. On the other hand, if the listener is outside the extent of the heterogeneous sound source, an exterior representation is rendered that reflects the position, size, and shape of the sound source as observed from the listening position.
The multi-channel source signal of a heterogeneous sound source may represent the sound field within the spatial extent of the source, for example in Higher Order Ambisonics (HOA) format. When the listener is inside the extent, the interior representation is rendered directly from the provided multi-channel source signal. For example, a multi-channel recording of the sound within a forest can be used to describe the interior representation of a sound source representing the forest. If the listener moves away from the forest, an exterior representation is derived from the interior representation to convey the impression of being at some distance from the forest.
Alternatively, the multi-channel source signal of a heterogeneous source may specify the exterior sound field of the source. For example, a heterogeneous sound source representing the sound of a cheering crowd of people may be defined using a stereo recording of the sound of the crowd captured at a position in front of it. In this scenario, the stereo source signal defines the exterior representation of the heterogeneous sound source. If the listener moves into the crowd, an interior representation is derived from the stereo signal and rendered to the listener.
Rendering of heterogeneous sound sources

The rendering of heterogeneous sound sources relies on a set of virtual loudspeakers, adaptively arranged to optimally represent the sound source at any given moment as the position of the listener changes.
When the listener is outside the spatial extent of the sound source, a simplified two-dimensional (2D) version of the spatial extent is calculated first to reflect the spatial extent as observed from the listener’s position. An adaptive setup of virtual loudspeakers is then positioned on the derived 2D extent to render the sound of the source to the listener. Depending on the angular width and height of the 2D extent as observed from the listener’s position, one out of three possible setups is used, utilizing either one, three, or five virtual loudspeakers. Smooth transitions between these setups are provided as the relative distance between the source and the listener changes, and with it, the angular width and height of the simplified extent.
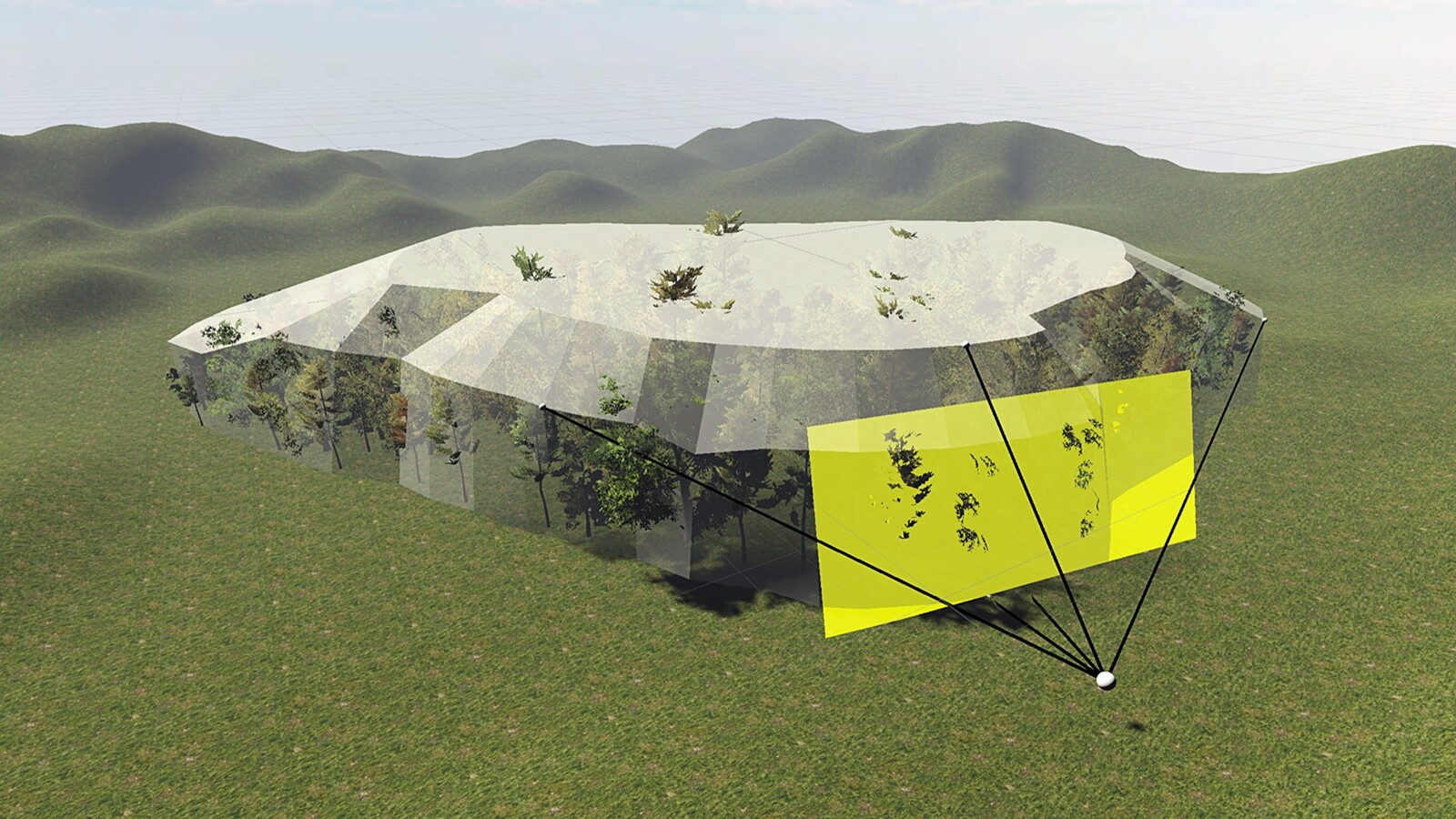

The 3D extent of the sound source is simplified into a 2D plane. Source: Test scenes created in Unity.
If the listener is positioned inside the spatial extent of the source, the interior representation is rendered using 12 virtual loudspeakers arranged in a sphere around the listener to create an immersive audio experience.
If the user moves from the inside to the outside of the spatial extent of the sound source, or vice versa, there is a smooth transition between the interior and exterior representations to maintain the audio continuity.
Occlusion of heterogeneous sound sources is detected using ray tracing, where a grid of rays is sent from the listening position toward the simplified 2D extent to determine which parts of the sound source are occluded. The simplified extent is then modified to reflect any occlusion.
Our rendering model can handle situations where different kinds of occlusion, whether hard or soft, affect different parts of the same volumetric sound source. Soft occlusion is rendered by adding filtering that corresponds to the occluding material to the signals for the virtual loudspeakers. For instance, if parts of the sound source are behind a thick curtain, the higher frequencies are filtered out.
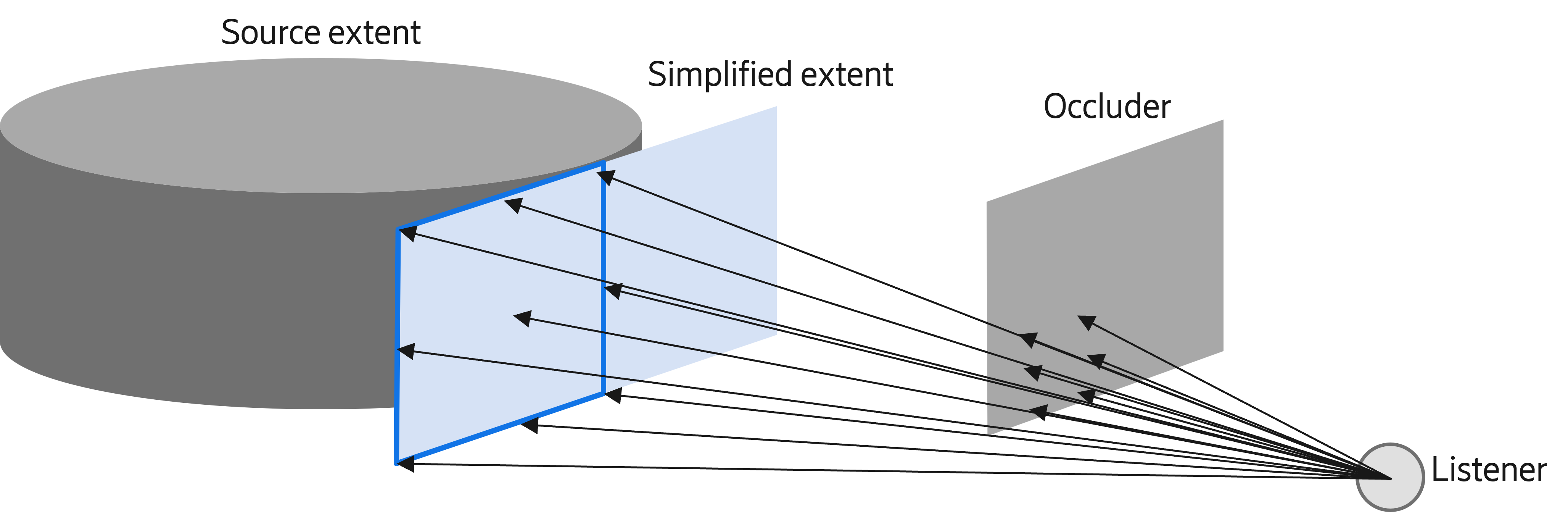
The detection of occlusion uses ray tracing to find out what parts of the extent are occluded.
For enhanced realism, the rendering model of heterogeneous sound sources incorporates a distance attenuation model that considers the size of the sound source. This model provides a simple yet accurate approximation of the real-world attenuation behavior of volumetric sound sources.
Read more
More details about the new concept can be found in our paper:
- de Bruijn, W. and Falk, T., “Representation and rendering of heterogeneous spatially extended sound sources,” in AES 5th international conference on Audio for Virtual and Augmented Reality (AVAR), 2024