Test de régression visuelle : pourquoi l’IA visuelle peut améliorer les expériences digitales de vos utilisateurs
- English
- Français
Lead Data Scientist
Head of Data Science Chapter
Head of AI Business Enablement, Enterprise Automation & AI
VP and Head of Automation & AI
Lead Data Scientist
Head of Data Science Chapter
Head of AI Business Enablement, Enterprise Automation & AI
VP and Head of Automation & AI
Lead Data Scientist
Head of Data Science Chapter
Head of AI Business Enablement, Enterprise Automation & AI
VP and Head of Automation & AI
Chaque site web est une vitrine sur les activités de l’entreprise et a un impact important sur la façon dont le public ciblé perçoit la marque. Un site internet mal conçu avec des défauts visuels peut ruiner l’expérience utilisateur et ternir la crédibilité. L’IA et la vision par ordinateur utilisés dans le cadre des tests de régression visuelle peuvent arrêter les bugs visuels de manière constante, réduire la quantité de code et de maintenance requise, rendre l’équipe de test plus productive et augmenter considérablement la couverture des tests.
Dans cet article de blog, nous allons découvrir comment fonctionne un cadre d’automatisation des tests visuels alimenté par l’IA et ce que cela signifie pour les équipes de développement et de test web qui se lancent dans cette méthode fondamentalement nouvelle.
Qu’est-ce que le test de régression visuelle ?
Le test de régression visuelle, également appelé test de l’interface utilisateur (UI), consiste à vérifier, à la suite de modifications du code d’un site donné, l’exactitude esthétique de tout ce que les utilisateurs finaux voient et ce avec quoi ils interagissent. Il est différent des tests fonctionnels qui garantissent un bon fonctionnement des caractéristiques et des fonctions de l’application.
Les tests de régression visuelle sont conçus pour trouver des « bugs » visuels qui ne peuvent pas être découverts par les outils de test fonctionnel, tels que des boutons mal alignés, des images ou des textes qui se chevauchent, des éléments partiellement visibles, des problèmes de mise en page et de rendu réactifs, etc.
Dans l’exemple ci-dessous (cf figure 1), un œil humain sera capable de détecter que la page web du deuxième cas présente des défauts visuels. Le titre et le corps du texte se chevauchent, ce qui rend le contenu illisible. Pour ne rien arranger, le bouton « Explore now » est recouvert de texte, ce qui empêche les utilisateurs de le sélectionner. Ces défauts passeront inaperçus dans un test fonctionnel puisque le test sera en mesure de trouver tous les éléments et de cliquer sur le bouton quel que soit l’endroit où il est placé. Des scénarios comme celui-ci peuvent conduire à une expérience très désagréable pour l’utilisateur final et même affecter la facilité d’utilisation.

Figure 1 : Images de base et images modifiées montrant les différences visuelles
Approches traditionnelles des tests de régression visuels et leurs limites
Les sites web modernes sont composés de centaines de pages web avec des millions d'éléments. En théorie, les applications pourraient être passées au crible manuellement pour identifier les bugs visuels, mais les tests visuels manuels sont coûteux, faillibles et assez peu pratiques.
Prenons l'exemple d'une page web fonctionnant sur trois systèmes d'exploitation (Windows, MacOS et Android), cinq navigateurs (Chrome, Edge, Firefox, IE et Safari) et vingt résolutions (pour un affichage standard sur mobile et sur ordinateur portable/de bureau). Un testeur manuel devra inspecter :
3 X 5 X 20 = 300 configurations d'écran pour une seule page web.
Maintenant, s'il y a dix applications qui doivent être testées dans dix langues différentes et que chacune de ces applications n'a que deux pages avec des changements de code par semaine, alors le nombre augmentera rapidement :
300 X 10 X 10 X 2 = 60 000 configurations d'écran à tester chaque semaine !
60 000 tests de régression visuelle par semaine exigent une très grande équipe d'assurance qualité (QA) qui s'efforce de repérer tous les bugs visuels, bien qu'il soit réaliste de penser que c'est une "mission impossible" pour les humains de repérer chaque changement visuel, ce qui pose le risque d'envoyer des bugs visuels en production qui peuvent avoir une incidence directe sur l'expérience l'utilisateur.
Par ailleurs, les ingénieurs en automatisation pourraient élaborer des hypothèses de test et des localisateurs pour automatiser les tests visuels. Vous aimez cette idée ? Attendez, il y a un hic. Créer et maintenir des tests complexes pour vérifier l'emplacement de chaque élément et le style d'une page Web est fastidieux et surtout impossible car vous ne pouvez pas vérifier la "correction" visuelle par le code.
Les approches traditionnelles obligent donc les organisations à réduire la couverture de leurs tests ou à ralentir leurs mises en production. L'IA visuelle appliquée aux tests de régression visuels permet de remédier aux limites des stratégies conventionnelles évoquées jusqu'à présent.
L'IA visuelle imite l'œil et le cerveau humain mais ne se fatigue pas et ne s'ennuie pas. Elle combine les forces de l'apprentissage automatique et de la vision par ordinateur pour identifier les défauts visuels d'une page web.
Avant de nous plonger dans le fonctionnement de l'IA visuelle, passons en revue quelques méthodes de tests visuels couramment utilisées.
Comparaison entre capture d’écran et pixels
Cette méthode consiste à prendre une capture d’écran et à la comparer aux pixels d'une version précédente de la page, provenant du même navigateur ou d'un autre.
Pouvez-vous repérer les différences entre les images de gauche et de droite dans la figure 2a ?

Figure 2a : Images de base et images modifiées pour la comparaison des pixels
Même après une inspection minutieuse, un "œil" humain ne parviendra pas à repérer toutes les différences. Mais la méthode des pixels les détecte toutes (comme le montre la figure 2b) et en moins d'une milliseconde !

Figure 2b : Image avec les différences mises en évidence (en rouge) générées par le modèle de comparaison de pixels
La méthode des pixels appliquée aux tests visuels pose de sérieux problèmes. Elle est confrontée à des faux positifs et signale des changements infimes dus à l'anticrénelage des polices, au redimensionnement de l'image, au rendu du navigateur et de la carte graphique, qui ne sont pas visibles à l'œil humain. En outre, il ne peut pas gérer un contenu dynamique comme un curseur clignotant ou une page dont le contenu est modifié régulièrement. Également, lorsque les pixels suivants diffèrent, les différences signalées peuvent masquer un problème réel plus loin dans la page.
Comparaison par Document Object Model (DOM)
Le Document Object Model (DOM : modèle objet de document) est une interface de programmation pour les documents web. Il représente la page sous forme de nœuds et d'objets afin que les programmes puissent modifier la structure, le style et le contenu du document.
Le DOM fait correspondre les arbres DOM des pages de base et de test et met en évidence les changements entre les nœuds des arbres. Dans l'exemple ci-dessous, le texte des pages de gauche et de droite "5G en Inde" peut sembler avoir des polices visuellement identiques, cependant, les polices ont deux différences majeures qui peuvent être identifiées à partir de leurs DOMs - le style de police à gauche est 'Helvetica' tandis que celui de droite est 'Arial', aussi la taille de la police à droite a augmenté d'un point.
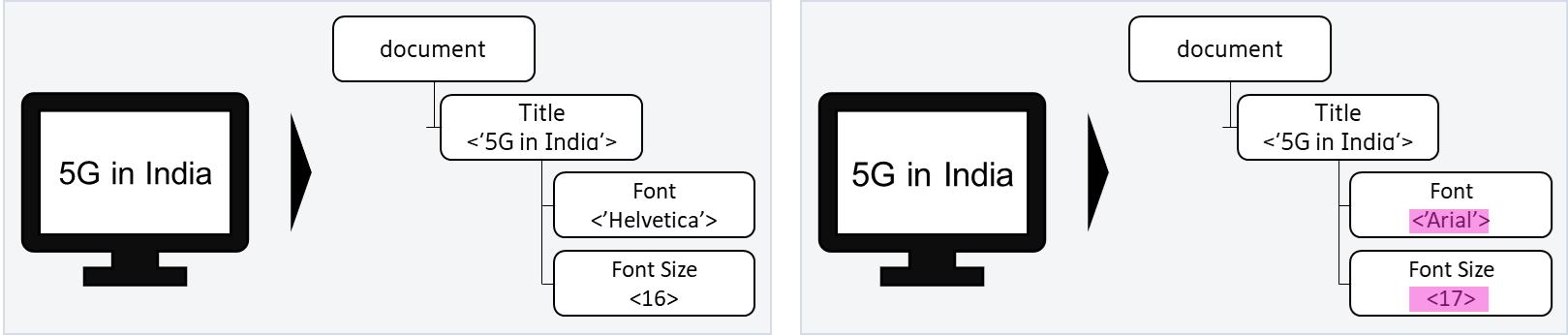
Figure 3 : Pages de base et pages modifiées avec les différences DOM mises en évidence
Bien que l'approche DOM puisse sembler être une solution simple et évidente pour l'automatisation des tests visuels, il y a plus qu'il n'y paraît.
Tout d'abord, le DOM contient à la fois du contenu rendu et non rendu, de telle sorte qu'une simple restructuration de page peut remplir la comparaison DOM de différences "correctement identifiées" mais qui sont des faux positifs du point de vue des tests visuels.
Deuxièmement, la comparaison DOM ne peut pas détecter les changements de rendu. Un nouveau fichier image téléchargé sur une page avec l'ancien nom de fichier passera inaperçu même si l'utilisateur voit une différence sur la page rendue.
Les comparaisons DOM ne suffisent donc pas à elles seules à garantir l'intégrité visuelle.
Comment fonctionne l'IA visuelle
L'IA visuelle surmonte les problèmes des approches par pixel et DOM. Elle identifie les éléments visuels qui composent un écran ou une page. Plutôt que d'inspecter les pixels individuels, l'IA visuelle utilise la vision par ordinateur pour reconnaître les éléments comme ayant des propriétés (dimension, couleur, contenu, placement, etc.) comme un œil humain et utilise les propriétés d'un élément de contrôle pour le comparer à la ligne de base et repérer les différences visibles.
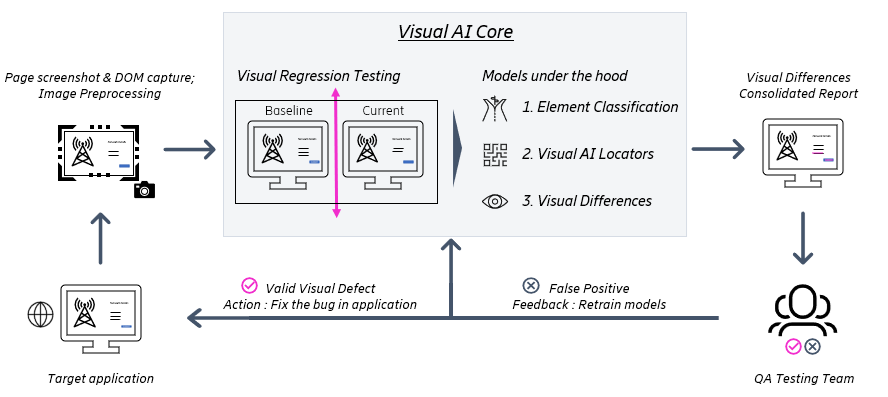
Figure 4 : Flux de travail de la solution d'IA visuelle
Étape 0 : Collecte et prétraitement des données
La solution capture l'interface utilisateur de base et le DOM après chaque version réussie et les conserve pour des tests futurs. Lorsque de nouvelles modifications sont apportées à l'environnement de test, des captures d'écran et le DOM des pages Web modifiées sont enregistrés. Avant d'être transmises aux modèles, les images sont prétraitées et corrigées en ce qui concerne la taille, l'orientation et la couleur. Cela permet de s'assurer que les images de base et les images actuelles sont comparables.
Étape 1 : Classification des éléments
Au début, le modèle inspecte les éléments du DOM de la page web qui sont pertinents du point de vue des tests visuels, en tirant des enseignements de l'historique des tests précédents. Il identifie également les éléments qui doivent être ignorés et les filtre. Le modèle parcourt les arbres DOM de référence et de test pour détecter les changements, les ajouts et les suppressions de ces éléments visuels.
Étape 2 : Localisateurs d'IA visuelle
La solution d'IA visuelle utilise ensuite la vision par ordinateur pour trouver des localisateurs visuels prédéfinis sur une page web. Les localisateurs visuels sont des composants d'une page tels que des boutons, des tableaux, etc. Le modèle apprend ces localisateurs visuels et scanne les captures d'écran modifiées pour trouver ces localisateurs sur la page. Si le modèle n'est pas en mesure de trouver un localisateur sur la capture d'écran modifiée qui apparaît sur la ligne de base, il signale la divergence comme un défaut. L'exemple ci-dessous montre que la capture d'écran de la page modifiée ne comporte pas le bouton "Support" dans le menu principal. De même, le nom du bouton "Me & My Unit" a été modifié en "My Unit". Ces défauts visuels seront détectés par le modèle d'IA visuelle et mis en évidence pour que l'équipe de test QA puisse intervenir.
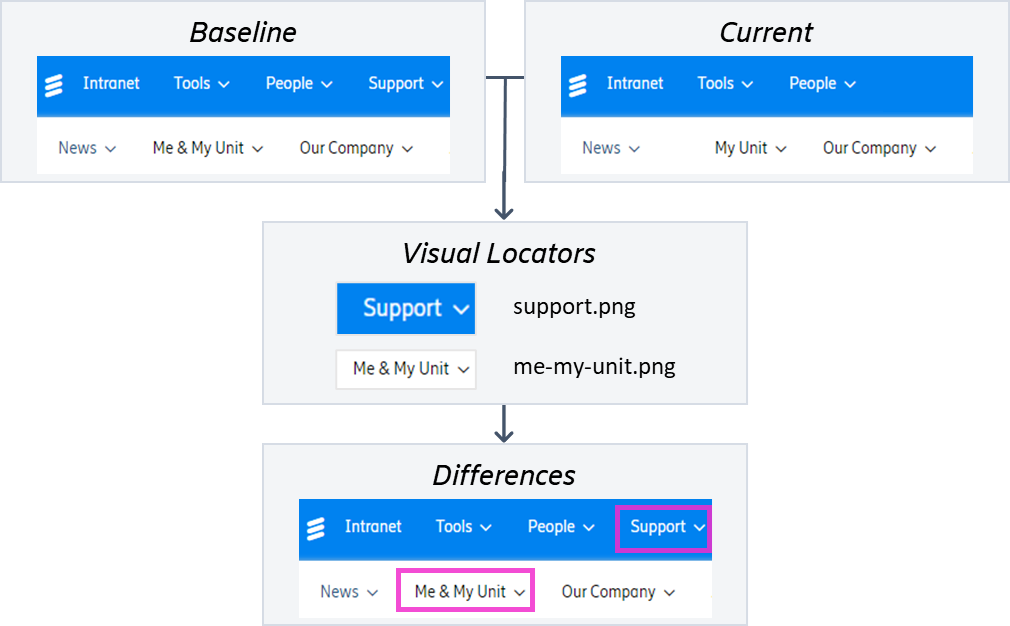
Figure 5 : Le modèle d'IA visuelle utilise des localisateurs visuels pour signaler les défauts sur une page Web modifiée
Étape 3 : Différences visuelles
Enfin, le modèle compare les localisateurs et les éléments des pages de base et des pages modifiées pour trouver des différences visuelles. La figure 6 ci-dessous montre les captures d'écran initiale et actuelle d'une page internet et les différences mises en évidence par la solution Visual AI. Le modèle peut détecter le chevauchement des textes ainsi que l'absence du bouton "Explore the report".
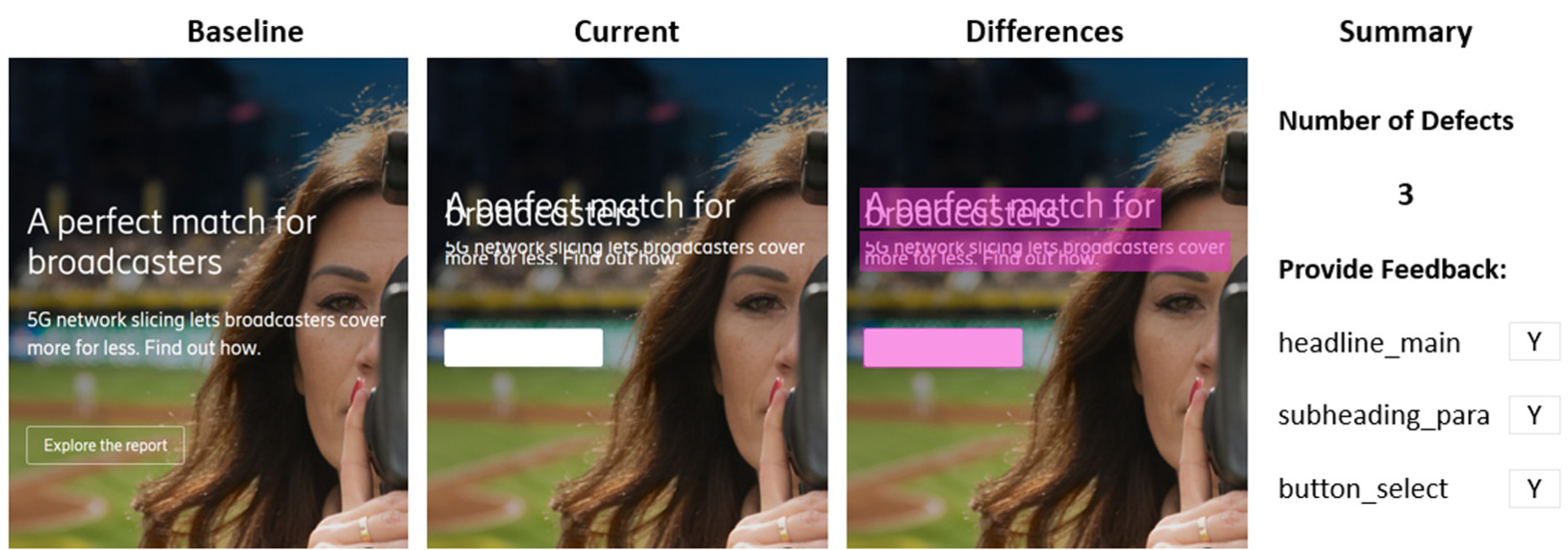
Figure 6 : La solution d'IA visuelle met en évidence les différences
La solution d'IA visuelle prépare un rapport consolidé pour tous les tests qu'elle a effectués, qui comprend des captures d'écran de pages avec des différences visuelles clairement marquées.
Le modèle peut être exécuté en mode batch pour prendre en charge les tests de plusieurs pages web sur différents navigateurs, écrans et systèmes d'exploitation.
Les défauts détectés par le modèle peuvent être transmis à l'équipe de développement pour être résolus. En outre, les commentaires de l'équipe de test sur la précision des tests sont intégrés au modèle pour un réentraînement continu et une amélioration du modèle.
L'approche de l'IA visuelle surpasse les tests visuels basés sur les pixels ou DOM, car elle a l'intelligence :
-
D’ignorer les différences visuelles mineures causées par le décalage de quelques pixels lors du rendu sur différents navigateurs.
-
De reconnaître les éléments qui sont visuels et ceux qui ne le sont pas, tout comme un humain peut le faire, et
-
D’évaluer quels éléments visuels sont autorisés à se déplacer sur une page et les ignorer sur tous les écrans.
Quel est l'avenir des tests de régression visuelle ?
Le monde évolue vers une société axée sur les applications, où les êtres humains en utilisent de plus en plus dans tous les aspects de leur vie, qu'il s'agisse de divertissement, de loisirs, de travail ou de passe-temps. Le nombre d'applications a explosé et le besoin d'une expérience utilisateur transparente et omnicanale est devenu une nécessité, et non un luxe.
Les entreprises doivent offrir la même expérience, peu importe si l'utilisateur se sert de Microsoft Edge sur son ordinateur portable ou de Chrome sur son téléphone mobile. Au-delà des choix traditionnels, l’accès aux applications se fait de plus par le biais de consoles, de tablettes et de wearables. En outre, l’expérience utilisateur devient le principal levier d'engagement au détriment des fonctionnalités. Il est impossible de rester fidèle à l'approche traditionnelle des tests visuels, centrée sur les personnes. L'automatisation des tests basée sur l'IA est la nécessité de demain. L'introduction de l'IA au cœur des tests visuels résout de nombreux problèmes auxquels les organisations sont actuellement confrontées. Nous avons démontré dans ce cas d'usage que l'automatisation des tests basée sur l'IA n'est pas un concept, mais une solution pratique qui répond aux besoins essentiels des entreprises, tout en étant capable d'évoluer et de créer une base pour la prochaine génération d'automatisation des tests.
En savoir plus
En savoir plus sur l'IA dans les réseaux.
Lisez notre article de blog sur la vérification des signatures par apprentissage automatique : Comment améliorer l'approvisionnement responsable avec une conformité automatisée.
En savoir plus sur la prévision de la demande alimentée par l'apprentissage automatique.
Découvrez comment l'IA peut être utilisée dans le domaine de la durabilité environnementale.