Bringing reinforcement learning solutions to action in telecom networks
Principal Researcher, Artificial Intelligence
Research Manager, Artificial Intelligence
Senior Specialist, Artificial Intelligence for optimization
Manager, Artificial Intelligence
Principal Researcher, Artificial Intelligence
Research Manager, Artificial Intelligence
Senior Specialist, Artificial Intelligence for optimization
Manager, Artificial Intelligence
Principal Researcher, Artificial Intelligence
Research Manager, Artificial Intelligence
Senior Specialist, Artificial Intelligence for optimization
Manager, Artificial Intelligence
What is reinforcement learning?
Reinforcement learning (RL), together with supervised learning and unsupervised learning, form the three methods in the area of machine learning. All three methods learn a model from data through training, but where supervised and unsupervised learning train the model from a dataset before being brought to inference, RL makes decisions and learns by repeated interactions with a target environment.
What makes RL special is that the target environment can be a dataset of past interactions, a simulation of a system or even a real system. The RL model learns complex behaviours in the target environment even in situations when the model of the environment is unavailable and can make decisions while optimizing for a long-term goal.
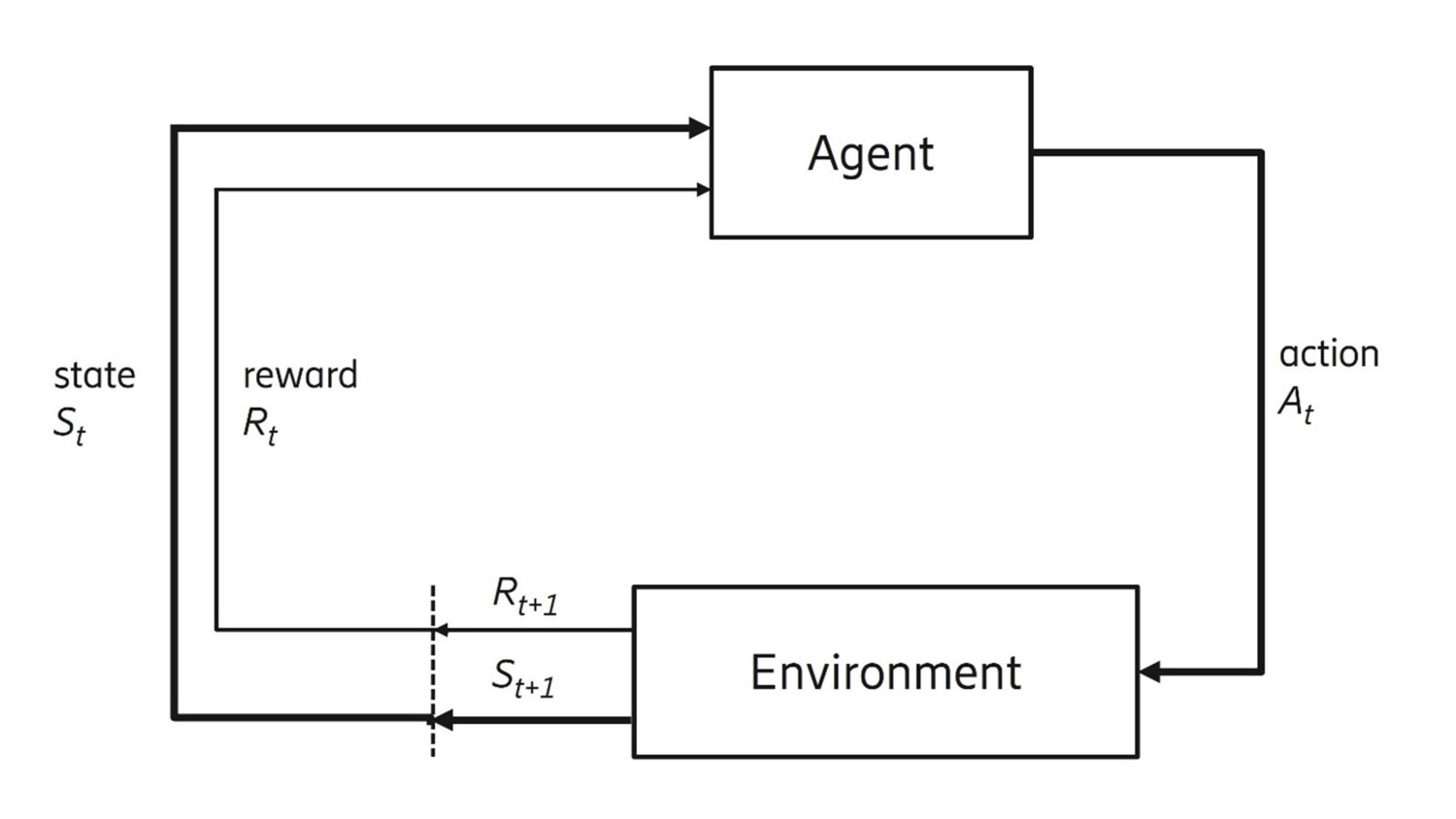
Figure 1: Reinforcement learning basic principles
The basic principles
Figure 1 shows the basic principles of RL. At each time step (t), an agent determines an action (At) based on the current state (St) using its policy. An environment executes the action and returns reward (Rt+1) and next state. Using the tuple of (state, action, reward, next state) collected over past steps, the agent updates its policy to increase the accumulated reward.
While RL was not at the forefront of the AI revolution in its initial years, it is now getting the needed attention in the industry, particularly as the need for autonomous agents becomes more and more indispensable to manage complex systems. In recent years, many different industries such as automotive, agriculture, and telecom have started to heavily invest in autonomous solutions mainly using RL with the ambition to optimize and automate their production processes.
Initial experiments to successfully apply RL were principally for playing games as the gaming environment was readily available and the agent could be trained in the game setting at a limited cost. As the techniques developed, we started to see examples from the real world. For instance, in web design and marketing RL has been used to identify what content presented to the user generates most value. It has also been used in clinical trials to efficiently evaluate alternative drugs. In the following, we give a few more examples where RL is successfully applied for real world problems.
Successful reinforcement learning use cases
In the America’s Cup sailing contest, a team used RL to teach an agent how to sail by using a sailing simulator under different conditions. Thanks to the agent, the need to involve sailors in the boat design process could be limited, which was of great value given their time constraints.
The technique is also being explored in autonomous driving, where tests have been made on a racing car to control throttle and direction through RL on a physical track. Complex Automation for Industry 4.0 is creating connected intelligent machines which can operate in a low latency environment enabled by 5G technologies. Coordination between such machines in dynamic environments is often a challenge and RL agents can help achieve the required control time-cycles over limited resources.
Still, many challenges remain to be addressed before RL can be applied to complex systems such as mobile networks. There are currently strong initiatives to address these, and the key challenges are explained in the next section.
Reinforcement learning in communication systems
5G enables low latency, ultra-reliable and high bandwidth network applications which can have diverse uses and specifications. As mobile communication systems expand, more control mechanisms need to be designed for autonomous operation. Management of a system goes from parameter setting for individual network functions to setting goals and define constraints for the mobile communication system to operate under.
The ultimate vision is a zero-touch system that allows humans to stay in control and monitor the automated operation with minimum need for interference. Hence in the telecom world the engineers aim to employ intelligent agents across all parts of the network, each of which can learn from data and coordinate with other agents. Autonomous coordination of agents across domains of the network, in conjunction with other relevant AI techniques can bring us closer to the vision of zero-touch management. Such agents in 5G networks may be heterogenous with respect to their skill and could even participate in dynamic settings where new agents may join the system, and existing ones may leave.
When designing for these highly sophisticated agents, the RL paradigm is a promising AI technique to explore. There is the potential to automate and optimize performance in local functions as well as higher layers of orchestration and management, operating in a dynamic environment. In the list below we give examples of areas where RL could play a significant role:
- Design of next-generation radio systems including implementation of a dynamic system for coordinated radio resource partitioning and scheduling across antennas in a MIMO system.
- Dynamic configuration of radio systems per operational requirements. An example could be autonomous configuration of tilt and power of antennas in a business district to achieve the best possible coverage or quality as per the mobility patterns at that point in time.
- Closed loop operations in 5G environments with dynamic orchestration across the different sub-network domains and orchestration layers of the network, through the deployment of interacting closed loops (more details in section 4).
- Traffic optimization over a radio link by adapting the use of scarce radio resources to meet the service level set for each user’s traffic.
At Ericsson, we are currently engaged in the research and development of systems and applications which leverage RL for implementing intelligent autonomous agents in networks. Research techniques like sim2real, latent space representations, safe RL, multi-agent RL and offline RL enable the development of RL systems, which can be trained using offline data or a digital twin and still be implemented in real-world systems with reasonable confidence. In parallel, the implementation of interacting closed loops, enabled by the techniques mentioned above, will help service providers realize significant benefits by automating complex systems and still drive significant cost efficiency. With many such RL techniques being adopted in products, the telecom world may soon be ready to experience an autonomous network driven by intelligent agents.
Development in the area moves fast. Examples that demonstrate this are the recent deployments of RL based solutions that have increased downlink user throughput by 12 percent in one operator’s network and decreased cell downlink transmission power by 20 percent in another operator’s network. In both cases, simulators and emulators were used to train the agents to obtain optimal policies before transferring them to a live network. Read more in this Ericsson mobility report article.
Closed control loops in telecom
In this section, we dive a bit deeper into the telecom architecture and describe some of the closed control loops that exist in the different network domains. Each of these control loops represents a functionality with individual cycle time constraints and may be executed in isolation or in collaboration with other control loops. Figure 2 illustrates the telecom system that comprises the three domains: Operations, Administration and Maintenance (OAM); Radio Access Network (RAN); and Core network (Core).
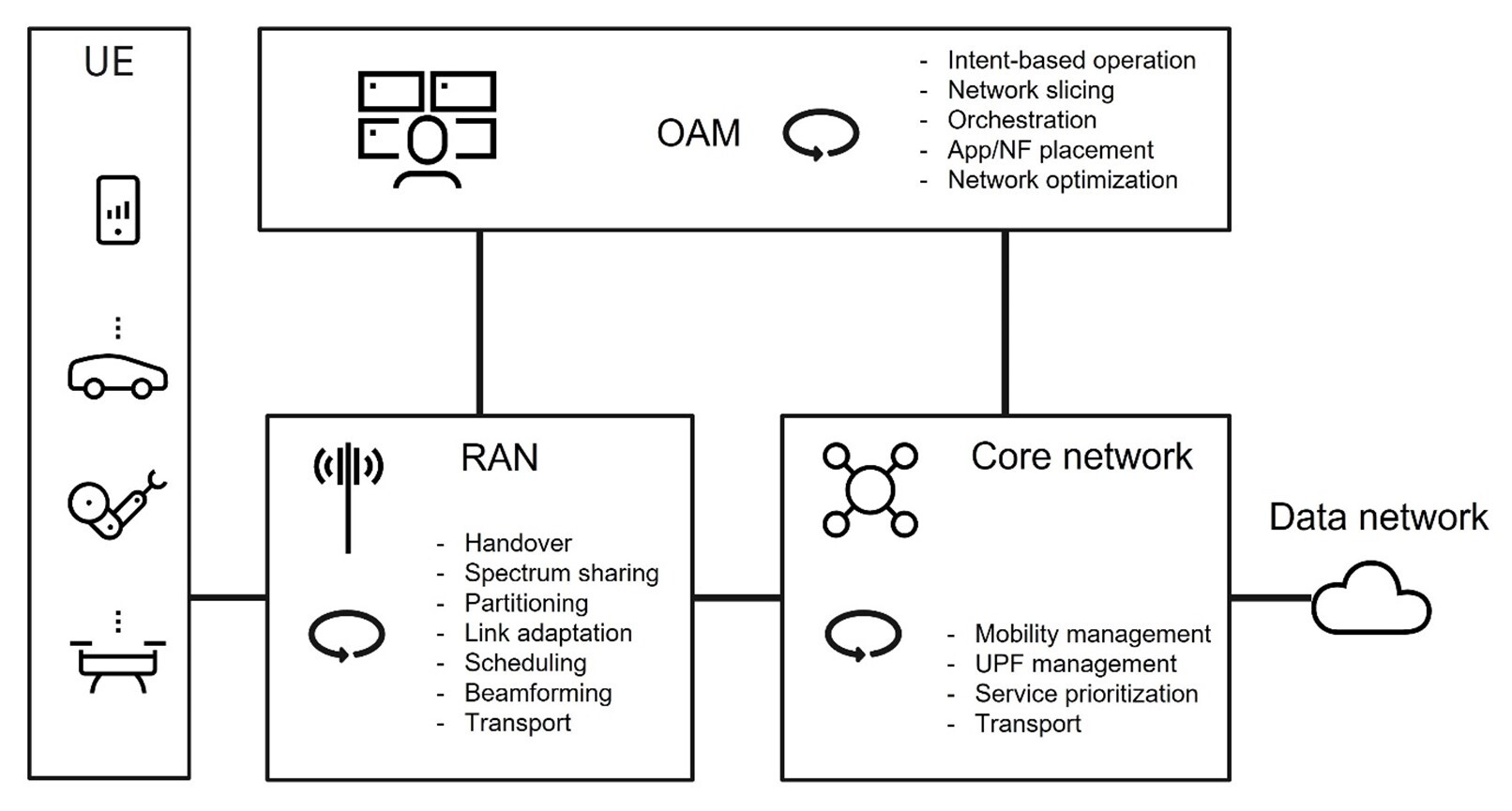
Figure 2: Examples of closed loops in a telecom network system
The OAM domain at the top controls the network’s physical and virtual resources. Resource usage is optimized towards set targets for service or business goals defined by the network operator.
The role of the Core is to establish reliable and secure connectivity to the network for users. The Core holds functionality for connectivity, mobility management, authentication and authorization, subscriber data management and policy management.
The RAN balances the available radio resources in the operator’s allocated spectrum against the user equipment’s (UE) requested services and geographical position. To manage this efficiently, RAN includes functionality for medium access control, radio link control, radio resource control and mobility management.
The figure above provides an overall structure of the main network domains and their essential functions but does not reflect how these are realized. The design is based on a layered architecture, where functions are deployed over a distributed cloud infrastructure, which also includes dedicated support for AI-based control functions such as hardware accelerators. Network operations therefore also include support for orchestration of workloads and the transfer of data for efficient training and inference.
In the following, we elaborate on a subset of the control loops to provide a better understanding.
1. End-to-end network automation control loops in the OAM domain
Network automation control loops are primarily to ensure the end-to-end service provided by the network. These loops are driven by a broad set of goals under specific constraints defined by the network operator rather than specific policy specifications on a detailed level. However, each goal is often realized only by achieving more than one KPI goal. Therefore, in this domain we often need to have multiple control loops which sometimes will have conflicting KPI targets aiming to achieve the overall goal. Here, the principles for collaborating and competing multi-agent RL can play a role in balancing the targets and target parameters against each other. Scalability of multi-agent RL architecture is also a challenge in this domain, given the number of goals (and associated KPIs) which a network is expected to manage.
Given that control loops in the OAM domain operate on an aggregated level, in comparison to control loops in RAN and many of the CN functions, the OAM control loop cycle times are longer. Typical OAM control loop cycles times are on a level of tenths of a second and above.
2. RAN parameter optimization control loops
RAN consists of several cells, each of which can have numerous parameters that determine the network performance for coverage, quality and capacity. To optimize performance, the parameters that control functions such as antenna tilt, sector shapes, transmit power and so on, need to be adaptively tuned, which OAM usually takes charge of.
The control of those parameters, however, is non-trivial due to 1) lack of optimization models that sufficiently reflect mobility and traffic demand, propagation in urban area, etc., 2) complexity from large-scale combinatorial nature in that all cells’ parameters need to be optimized considering their dependency to the neighboring sites. To address these challenges, a data-driven approach with RL is a promising solution. By exchanging actions of the parameter tuning and observations over the control loop between OAM and RAN, an RL agent can update its policy from the feedback for better parameter tuning.
3. RAN resource control loops
The control of spectrum usage and RBS (Radio Base Station) resources is on very short cycle times below 100ms. As the generation of wireless networks increases, more complex control mechanisms have been required in the system. The 5G RAN includes several resource control loops that observe the current status, for example, channel information and control the radio resource, such as link adaptation, MIMO beamforming, scheduling and spectrum sharing.
Also, many interdependencies are caused by dynamic UE environments and sites with overlapping coverage. Consequently, there is a need to optimize multiple KPIs but the episodes need to be short enough to account for stringent cycle times. Along with it, as the environment dynamics often change, there is a need to continuously learn and adapt in a cost-effective manner. Data-driven control, such as from RL, opens for using more complex and real-time dynamic data compared to what is possible with traditional domain expert design.
4. Core network control loops
Examples of control mechanisms with RL potential in the control plane are access and mobility management functions (AMF) and session management functions (SMF). These functions manage: sessions of user plane functions (UPF), resources for subscribed services and connections under mobility across geographical network boundaries. Data available in the CN can also be used for RL mechanisms to assure service levels and to protect against security threats. Control loop cycles are typically a magnitude longer than the RAN resource control loops.
RL research and activities at Ericsson
RL is expected to be an important part of 5G and future 6G networks, especially when it comes to efficiently managing KPIs and expectations across RAN, Core, and Orchestration/OAM domains. At Ericsson, we are engaged in exploring and evolving RL techniques, which may help us solve complex and challenging problems autonomously.
Below, we describe some evolving techniques and how they can apply to future networks.
Multi-agent RL
Multi-Agent RL refers to a technique where multiple agents learn to coordinate and act simultaneously on the environment and collaborate towards achieving a joint goal and/or individual targets.
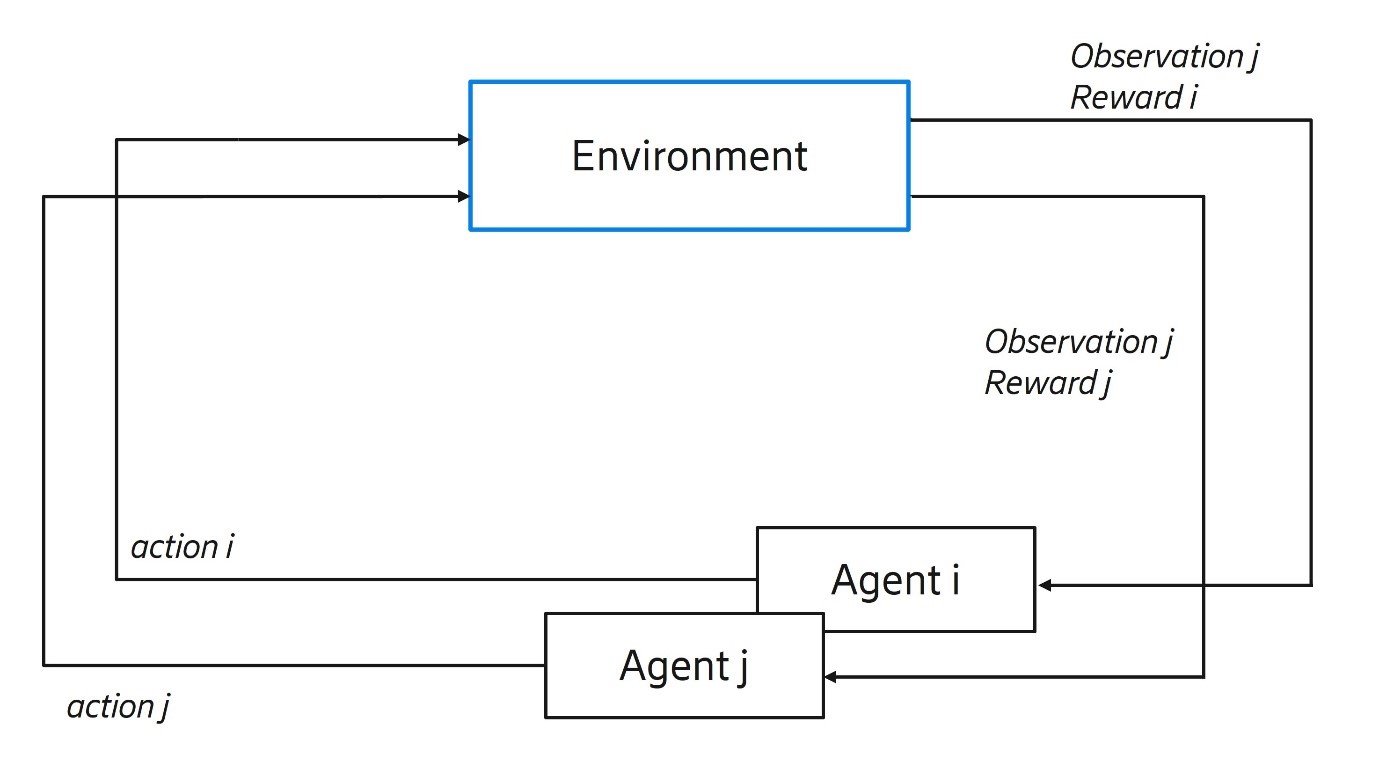
Figue 3: Multi-agent reinforcement learning
We are exploring this technique to resolve conflicts and promote cooperation among multiple agents in a telecom network, thereby optimizing system performance and efficiency.
One challenge for multi-agent RL is non-stationarity. It means that the next state seen by an agent is not dependent on the action and state of one agent but on the joint action of all agents in the system. The objective is to find the very narrow region of joint action space where cooperation and coordination are most effective. Some promising research in this area has been done, for example, by the WHIRL lab at Oxford, the Google Brain, and the DeepMind teams in Google.
In telecom networks, there is a need to run multiple control loops concurrently. There are two reasons. First, several users with different service requests must be served in parallel. One group of users might have a service level set for latency or throughput, while another one might need Quality of Experience optimization for conversational video. Second, the fulfillment of one service may need more than one control loop. A conversational video might need antenna tilt for RAN, bit rate optimization, and quality of service (5QI) changes in the core network.
All these control loops may need to coordinate with each other in a hierarchical setting to realize the service for the user. What happens if they conflict? Resolving such conflicts is one of the key challenges. Network efficiency will, in parts, depend on how efficiently multiple competing control loops can be orchestrated with optimal resource allocation.
Agents in telecom networks are heterogeneous in nature. This leads to a set of challenges we and others are actively researching, and where more work is welcome:
- The aspect of credit assignment is important – which agent is responsible to what degree for the outcome.
- Joint action may need to be asynchronously applied because agents have different time periods between their respective actions.
- Rewards are in different scales and sometimes the time window for reward attribution is different across agents, making it challenging to normalize the rewards.
In light of the challenges above, we are exploring state-of-the-art techniques such as QMIX, COMA, TD3 and extending/modifying them specifically for challenges in OAM, Service Prioritization and RAN.
Multi-Task/Goal Generalization
Multi-Task/Goal Generalization in RL refers to learning multiple tasks through one single training cycle, where the training data contains samples for all the different tasks. The result is an approach that mimics the human ability to learn from a task and use the acquired knowledge to learn another task faster.
Figure 4: Multi-Task in RL – learning multiple tasks
For example, figure 5 shows we can learn different kinds of sports simultaneously, i.e., transferring the knowledge of walking to learn how to trek or the act of balancing on skis to maintaining balance on skates. So the key question is: how can we transfer this human ability to algorithms and thereby enable models to learn and solve multiple tasks?
In the context of networks, task/goal generalization is important, because future networks will deal with a huge variety of users and services and, as a consequence, myriad fulfillment objectives. Therefore, training tasks independently may not be feasible or cost-effective. Agents will also need to continuously adapt to new goals, since operating conditions for the network will change along with users' mobility patterns and service consumption.
We have done experiments with service prioritization and core network loops. Our results show that applying the RL techniques, explained below, improve training efficiency, aids in task generalization and thereby makes it possible to generalize RL agents for being implemented in real-world applications.
It is preferred that tasks come from a common distribution to ensure that they have a reasonable degree of commonality.
Let’s take a look at a couple of challenges and the potential techniques to handle them.
As the single model is trained to learn multiple tasks, it needs more data to handle task dimensions, which means exploration may become expensive.
One strategy to handle this challenge is for the model to learn as much from an undesirable experience as from a desirable one, a technique referred to as Hindsight Experience Replay.
Another way – learning from latent state representations – has proven to be very beneficial as it enables the model to learn the inherent structure of the problem. A simple illustration of the problem: an agent learns to travel from any coordinate of a maze to any other coordinate. The starting point and the destination are not fixed.
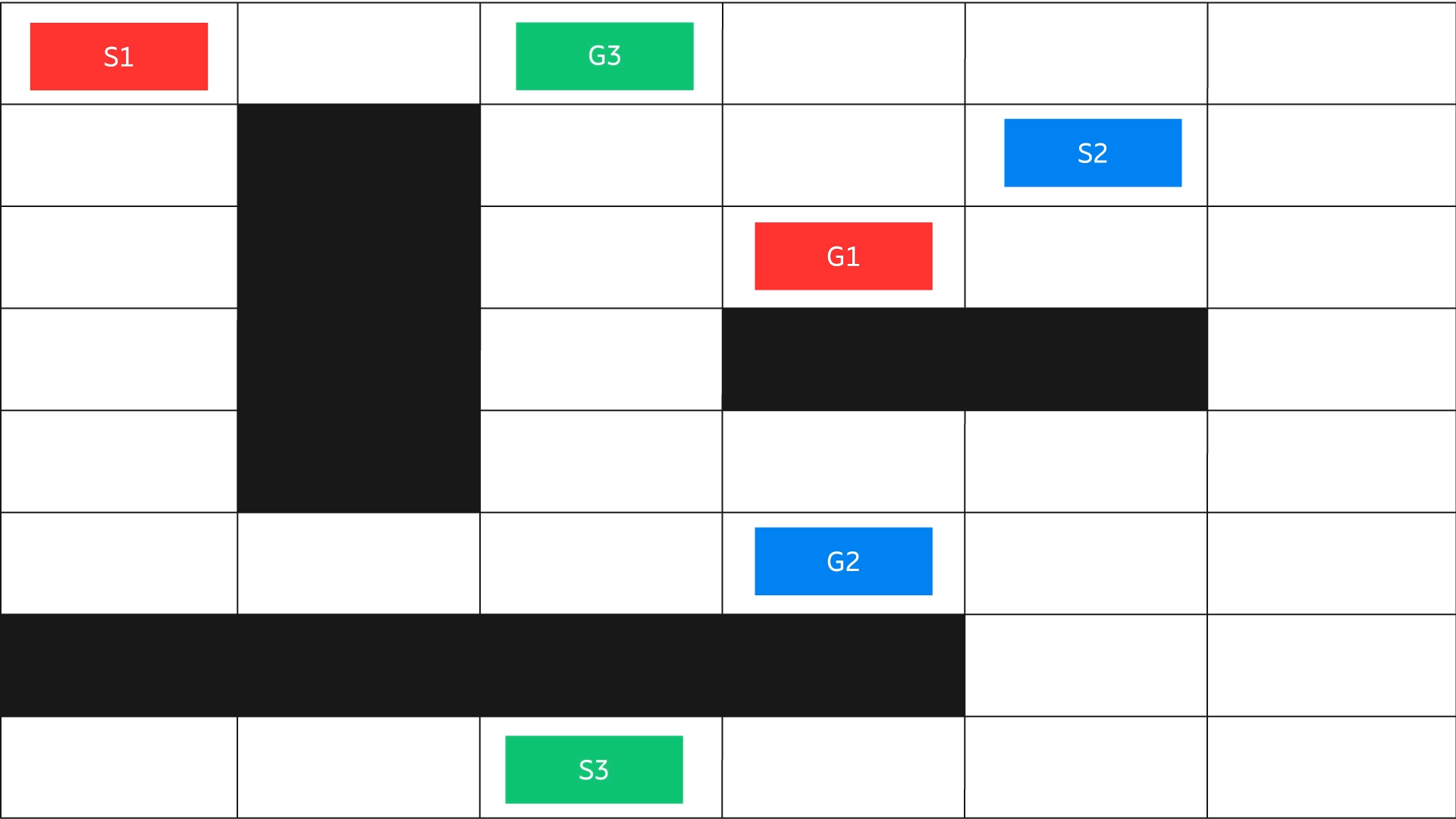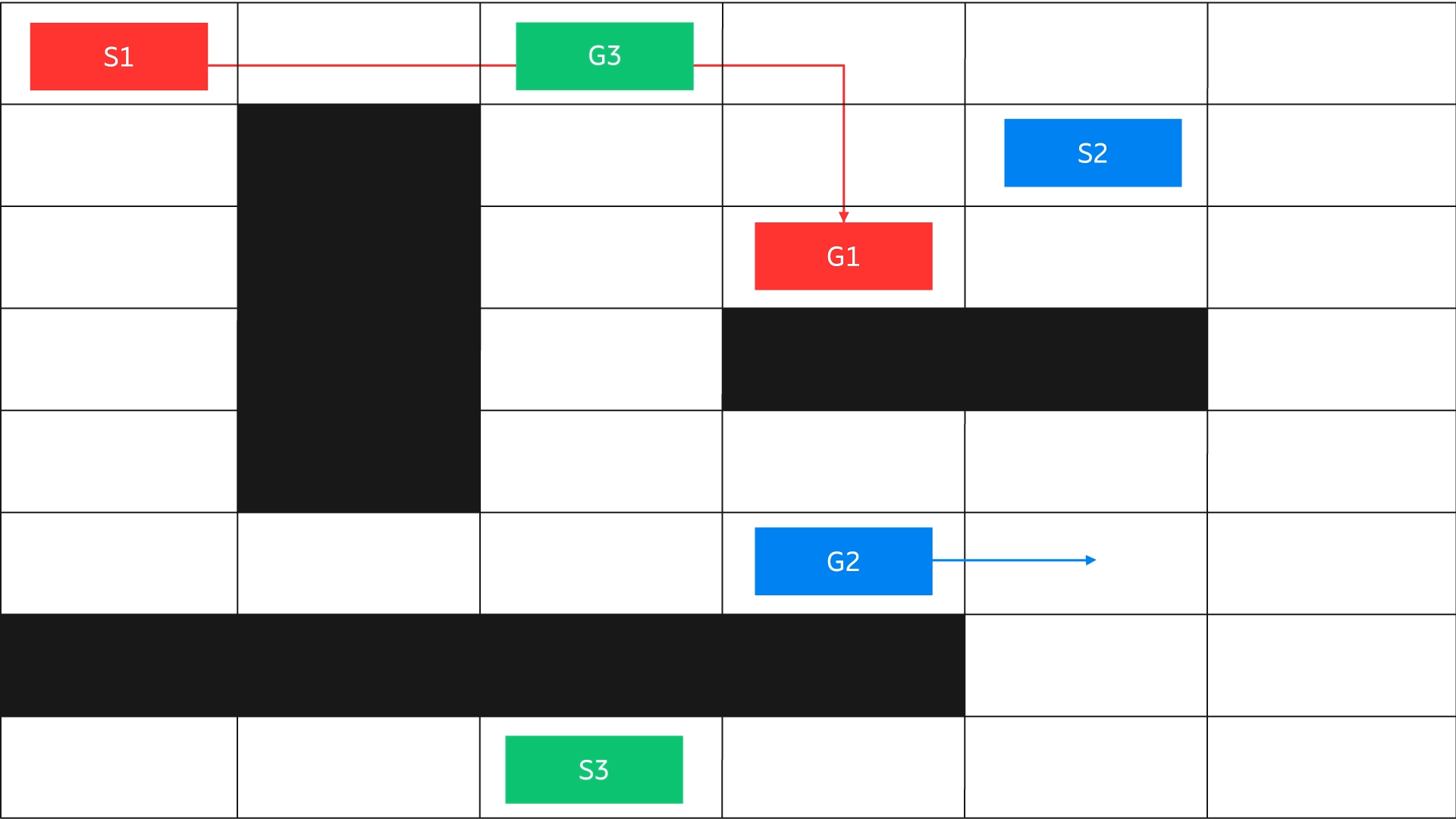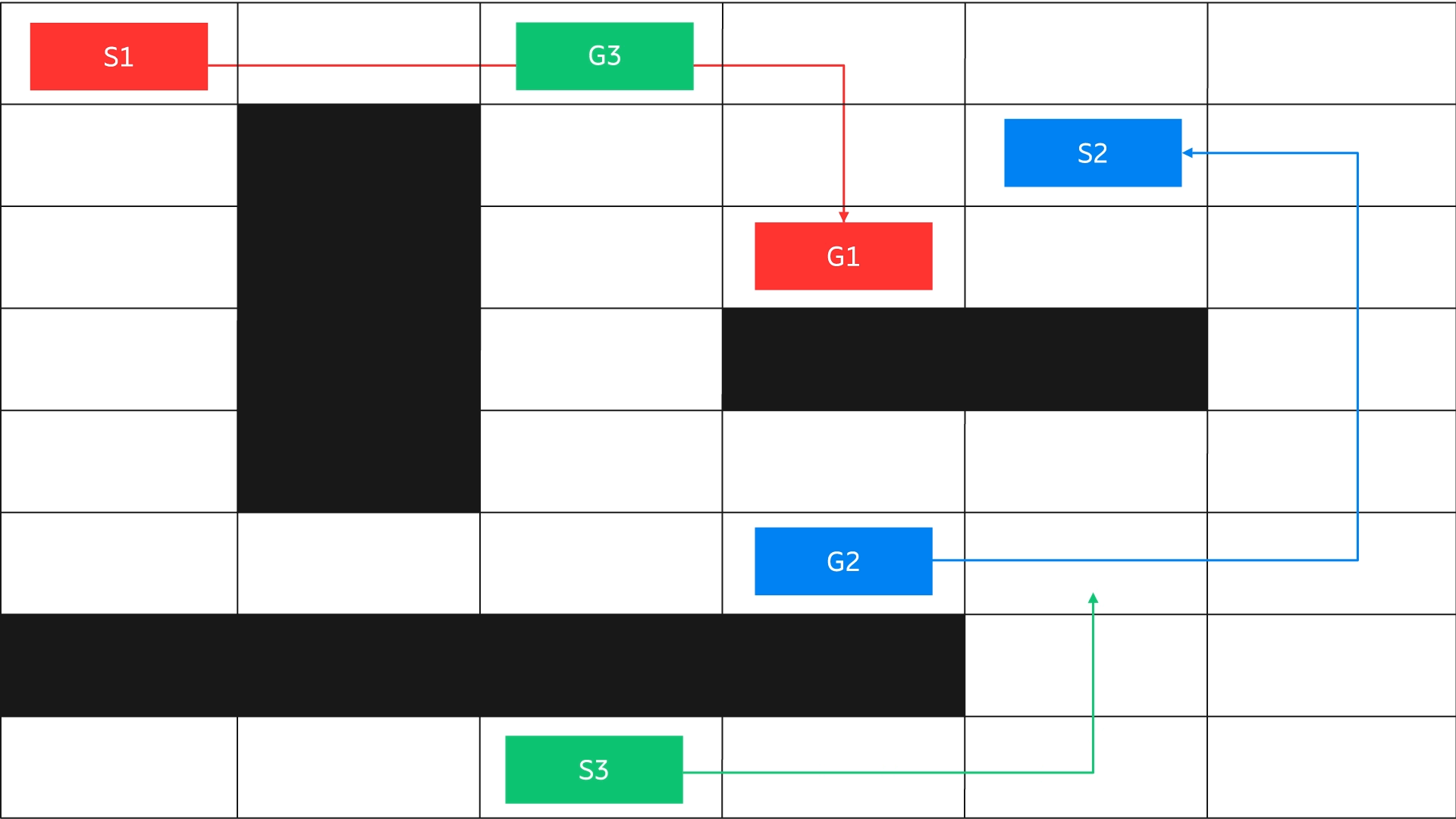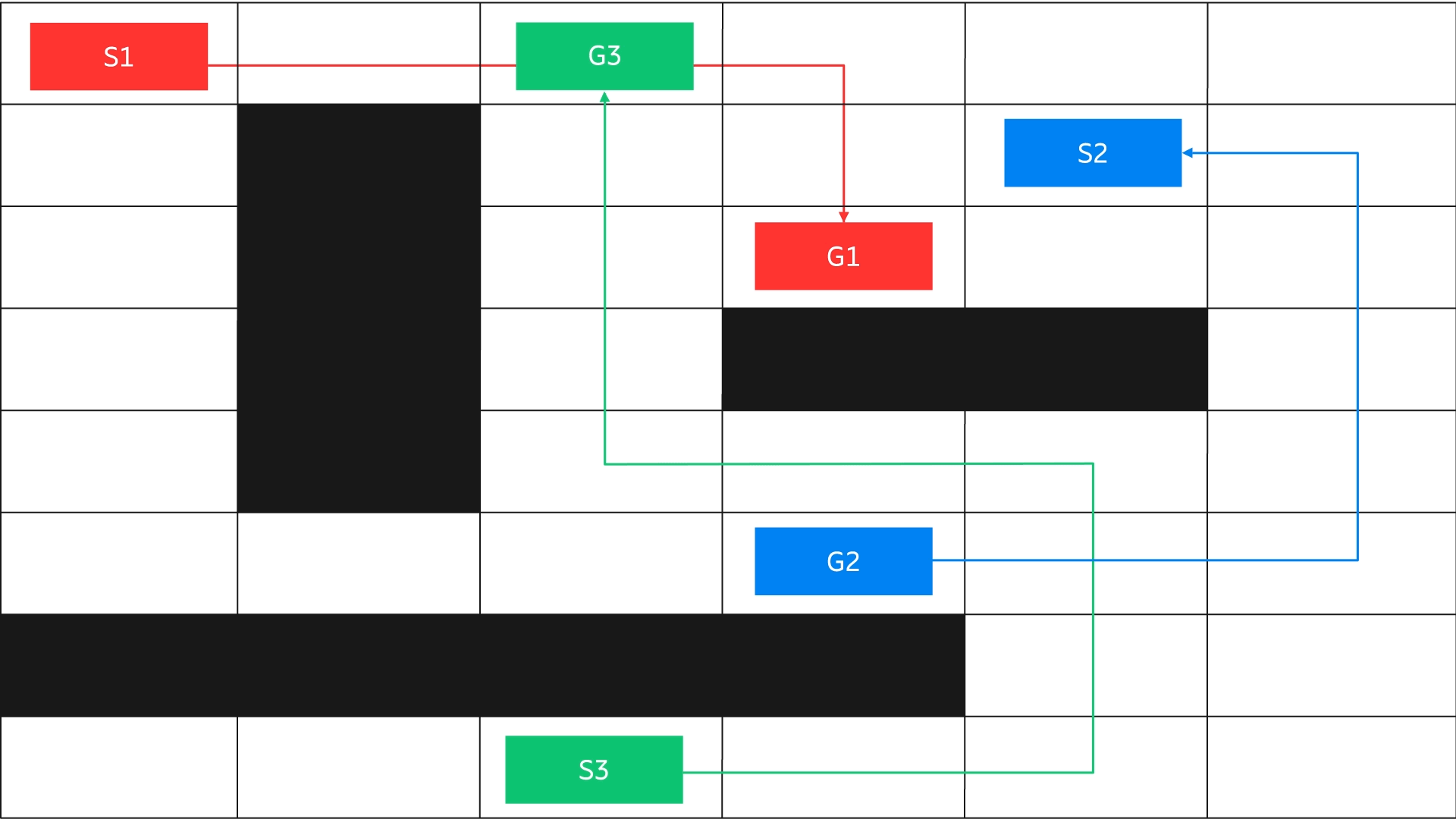
Figure 5: Multi-task / goal generalization
The agent needs to learn the inherent structure of the grid through a latent representation of the state space and goal rather than observing only the start and end points. Such a latent representation could be created using a simple function with the current state and goal state as arguments, or using variational autoencoders for complex environments involving visual representation.
Applying multi-task RL also has challenges associated with the transfer of experiences from one task to another. We only want positive transfer. If the tasks are very different it can result in conflicting gradients, which can affect learning negatively – such negative transfer of knowledge must be avoided. Additionally, as the algorithms learn multiple tasks and from each other, there is a risk of ‘catastrophic forgetting’ which means that an agent forgets what was learnt in previous tasks as it learns a new one.
There are several methods in scientific literature that address both challenges mentioned above in the articles, ‘Robust Multitask Reinforcement Learning’ and ‘Gradient Normalization for Adaptive Loss Balancing’, but still, this remains an open area of research.
Meta RL
In meta learning, the initial algorithm is trained on a base environment setting. The meta parameters of the problem are learned and then, as the dynamics change, the algorithm’s meta parameters are fine-tuned using limited examples to adapt to changed specifics. Meta-learning approaches use one or more techniques like the Black-box, Metric-based or Optimization-based model. Notably, the application of meta learning along with latent space representation (for example, using variational autoencoders) provide a powerful tool for RL algorithms to generalize across related tasks even in situations where dynamics of the environment have changed.
Figure 6 demonstrates the use of principles similar to Meta RL in human brains.
Figure 6: Meta RL – learning new tasks quickly
Human beings can learn the capabilities of many activities. Often, learning a new activity does not mean learning from scratch, but essentially adopting many learned techniques and channeling them into the new activity. Meta RL similarly can help a model adapt to a new task, with very few samples of data, by leveraging the learned knowledge from similar tasks.
The radio environment is dynamic and may change every few seconds due to physical and mobility factors. An RL model learned may soon become obsolete unless it is able to continuously learn and refine the model. Complete retraining is often not an option given the huge number of radio units deployed in a network and the limited resources available in edge nodes.
Ideally, in this dynamic environment re-training should be fast, efficient, and performed on limited data. Meta learning applied to RL has shown great potential as a solution.
Designing solutions for the RAN domain and particularly related to distributed MIMO (D-MIMO) radio systems often have challenges of changing dynamics, and hence a Meta RL model may provide significant benefit.
In D-MIMO, large groups of neighboring nodes strategically group together and co-operate for both transmission and reception. For the group to achieve system goals, they would need to address several issues including distributed beam-formation, distributed reception, synchronizing oscillators, applications processor (AP) selection, and channel state estimation and prediction. A Meta RL model applied here would also need to adapt to the changing dynamics of the radio environment to be practically usable, changes that are complex and are difficult to represent analytically.
So, connecting the dots, while meta-learning provides a solution to quickly adapt to a new task, the D-MIMO solution would require us to address several issues dealing with changing environments, mobility and so on.
Many of the D-MIMO challenges, such as AP selection and beam formation, can be approached as a meta-reinforcement learning problem. By quickly handling environment-to-task mappings, meta-learning algorithms can learn meta-models/parameters and quickly learn to solve problems associated with a new environment by observing a small snippet of that new environment.
Scaled RL training
To achieve robust agents, RL requires a large amount of data. Data can be obtained by an agent’s interaction with the control loop in the network, or simulators, or both. Like many other real systems, an agent’s constant interaction with the network for learning is not fully possible. To eliminate this big limitation, simulators can be used for training. Simulators are generally the main source of data for future RL solutions, for instance, in digital-twin like applications or other cases where real data is hard to access.
We have been developing and using several types of sophisticated simulators for diverse types of network functionalities. These simulators are currently being used, not just to obtain data, but also to test the performance of RL algorithms and optimize model parameters. When training using simulators, training procedures should be smartly scaled to collect vast amounts of data in a reasonable time and to get generalized models. Ways to scale training for successful RL:
- Parallelizing data collection for faster convergence.
- Hyperparameter optimization to obtain better and more robust policies.
- Domain randomization to close the sim2real gap.
We are developing a cloud-native, simulator-agnostic, cross-platform framework for flexible and extensible large-scale distributed RL training. The main challenge lies in the fact that simulators/emulators are written in different programming languages and have different messaging requirements. To overcome this challenge, scaled RL framework development activities aim to provide a unified API – one that is cross-platform supported and flexible enough for future extensions, has cloud-native log collection, backend forwarding and aggregation mechanisms, and finally provides end users (the RL practitioners) an easy-to-use frontend.
SIM2REAL transfer learning
SIM2REAL transfer learning aims to reduce the need for expensive training in a real environment by first training with a simulated safe environment at a low cost, then in a next step, transfer to a real environment. The flow is illustrated in figure 8.
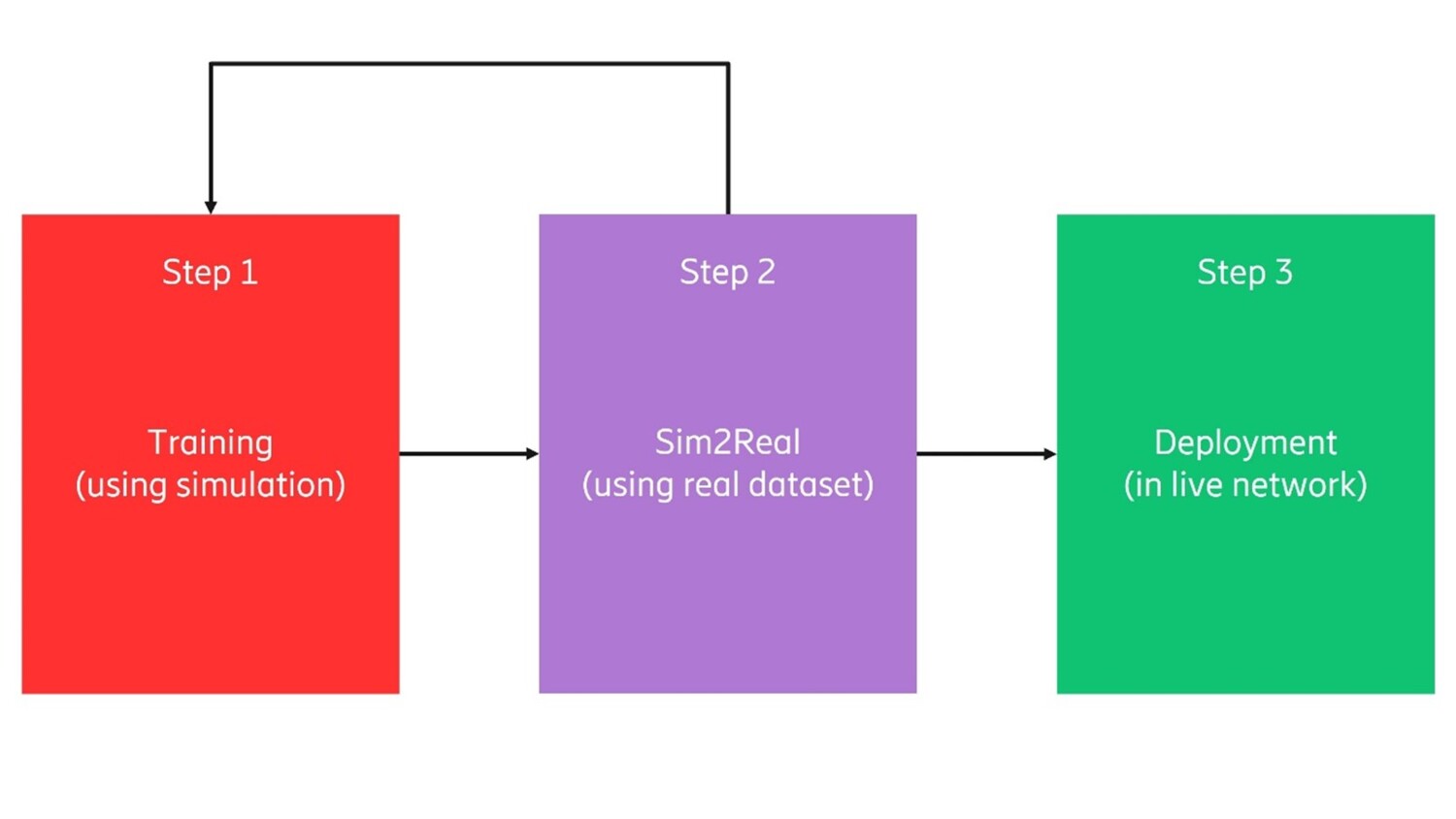
Figure 7: Bringing RL to live deployment in steps.
In telecom, various simulators have been developed to evaluate control loop solutions for different parts of the system. In light of RL training, those simulators are important assets that constitute virtualized environments where RL agents explore actions. The main obstacle so far has been the reality gap in sim2real transfer. Due to that gap, an agent trained by simulation data needs further adaptation before transfer to the real environment.
We have investigated two sim2real technologies: domain randomization and domain adaptation.
Domain randomization injects random noise into the simulation environment to make a simulation-trained policy sufficiently generalized for the real environment.
Domain adaptation applies a domain shift to either the simulation data or a simulation-trained model in order to make them realistic.
In our study, we’ve observed that both technologies can jointly contribute to improving the training steps towards the deployment.
Safe RL Safety
Safe RL Safety is key for deploying RL agents in real-world telecom use cases. To achieve safety during RL training and execution, we need to address many questions: How do we define safety? How can we provide or guarantee safety? What kind of architecture is required? To this aim, we have conducted extensive research to develop safety metrics, safe RL algorithms and the corresponding architecture. In particular, we introduced the notion of a safety shield located in between real environment and RL agents, illustrated in figure 9.
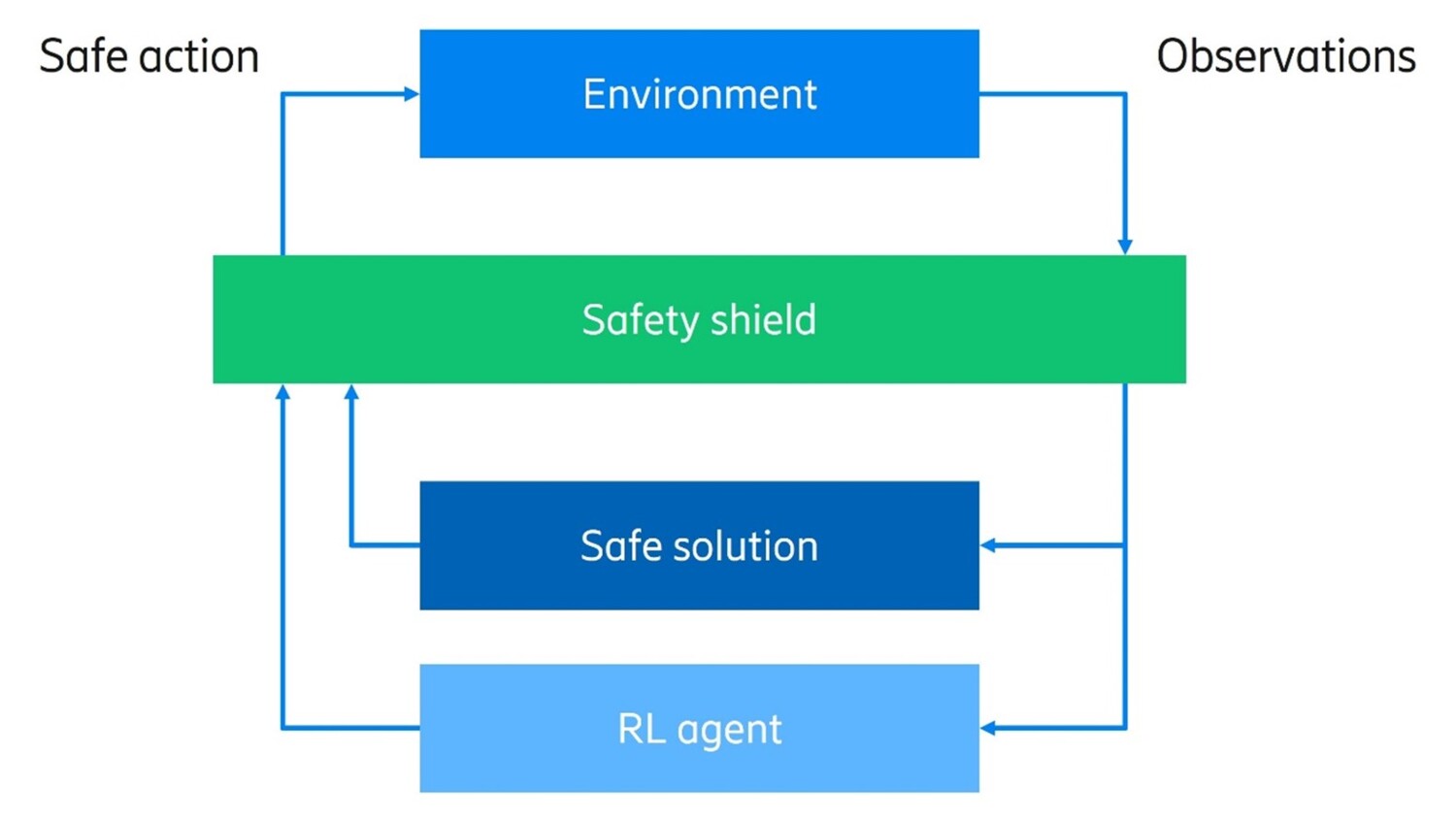
Figure 8: Safety shield mechanism to control actions proposed by an RL agent.
The safety shield decides whether to execute the action proposed by an RL agent after evaluating the safety of the action based on safety shield logics. We have created two different safety shield logics: one using symbolic logics extracted from domain knowledge, the other utilizing an existing rule-based solution, the safety of which is already verified in the field. Using those logics, a safety shield shapes an unsafe region in an action space, where the corresponding actions are prohibited in the real world.
Sample efficiency
Sample efficiency seeks to maximize RL performance when availability of real-world data is limited. This situation is common in the telecom domain where random exploration is usually not allowed. Various techniques can be used:
- Latent space training that compresses the spatial and temporal representation of the environment.
- Experience transfer whereby a model can jumpstart by looking at a few samples of trajectories from a base model’s earlier learnings.
- Recent techniques like few-shot learning, leveraging meta-learning or neuromorphic computing also hold promises for sample efficiency in RL training.
Conclusion
The future network platform is bound to include autonomous intelligence which controls resources to optimize performance. Reinforcement learning has shown to be a promising technology and has already found its way into games and less complex industry environments. By addressing the challenges described in this post, we see the potential to also bring the technology to more demanding cases in the future network platform.
At Ericsson Research, we are exploring new methods and techniques to address the challenges associated with implementing reinforcement learning at scale in future networks. Collaboration with academia and open industry forums are key components of such an exploration. Our journey towards future networks pushes the boundaries in fundamental RL research and adapting the developed concepts to large scale practical applications is another key step.
While the AI community, at least in parts, believes that the evolution of reinforcement learning may lead us towards generalized intelligence whereby Reward is Enough to motivate actions of intelligent agents, we are still far from achieving it. Until then, the journey continues and it promises to be an exciting one.
We would like to thank Maxime Bouton, Paul Smith, Dhiraj Nagaraja Hegde, and many other colleagues who have contributed and given feedback to this blog post.
Want to learn more?
Read more about cognitive networks – an introduction and outlook for the future.
Read our 6G white paper on ever-present intelligent communication.
Explore 5G
Explore Industry 4.0