On the relationship between AI and security in mobile networks
Principal Researcher Security
Principal Researcher
Senior Researcher, security
Master Researcher, security
Principal Researcher Security
Principal Researcher
Senior Researcher, security
Master Researcher, security
Principal Researcher Security
Principal Researcher
Senior Researcher, security
Master Researcher, security
The security community is exploring AI as a tool to secure use cases including protection against fraud and other threats to telecom systems. However, while our collective understanding of threats against software systems has evolved over recent decades, the research into specific threats against AI-based systems is still in its early stages and continues intensely today.
Why is this an area of such intense research? Compared to traditional software systems where the industry already has well-established processes, tools and controls to eliminate software bugs, AI-based systems can potentially contain an entire new class of AI-specific vulnerabilities. In order to prevent or detect these vulnerabilities during the whole DevOps life cycle, novel methodologies and tools are needed to help us assess the trustworthiness of said AI systems.
How is AI used in telecom security today?
There are several domains where AI is used to solve security problems. Examples related to mobile networks include:
- detection of fraudulent usage of mobile subscriptions
- detection of misbehaving IoT devices, which is also a feature in 3GPP Network Data Analytics Function
- detecting false base stations
- detecting malicious workloads in cloud-native environments
AI and anomaly detection
A common approach to threat detection is to look for something out of the ordinary, that is, anomalies or outliers. In contrast to looking for similarities with known attacks, this approach allows us to also find unknown threats which have not been observed before. AI is effective at doing this and, today, is already commonly applied to monitor a system and detect unusual events that could indicate system failure or compromise.
In many cases, trying to predict the unknown means that there is no knowledge about which (if any) data points correspond to such anomalies. In AI terminology, such a dataset lacks labels and the application of AI to detect anomalies is limited to unsupervised learning, where no training is performed. If there is some way of obtaining data known to be free of anomalies, then this extra knowledge can be exploited to produce more precise models of the normal behavior. This is known as a case of one-class learning, where training models are developed exclusively on data corresponding to normal operation. Such models can then be used to compare new data points and thus find anomalies. This setting of anomaly detection is often called “novelty detection”.
AI anomaly detection in live operations
AI-based systems are used as the first line of defense in live operations, sending alarms for anomalies exceeding a certain anomaly score to a Security Operations Center (SOC). The “alarm budget” represents the number of anomalies that a SOC can handle and the focus of the AI algorithm is thus to maximize the fraction of anomalies caught within this constraint.
The alarm budget can be translated into a score threshold such that an acceptable number of the normal samples are flagged as anomalies. Thus, we seek an algorithm that increases the relative anomaly score on the set of anomalies with a possibility to be scored above the threshold. In contrast, when comparing algorithms, the relative scoring of anomalies that are scored below the alarm budget threshold is not of interest. Catching more true anomalies within the alarm budget can come at the expense of a lower anomaly score for anomalies below the threshold.
Test case: Isolation forest versus anomaly detection forest
We started investigating machine learning (ML) for anomaly detection in telecom use cases with a popular algorithm called “isolation forest” (IF). However, when building an IF model on network traffic from IoT devices, the results were disappointing. In particular, IF failed to flag a number of anomalies even though they showed some very distinctly deviating features. The problem was that IF is not optimally designed for the one-class learning case described above. To address this shortcoming, we developed a new algorithm called “anomaly detection forest” (ADF). Figure 1 (below) shows the results of our tests.
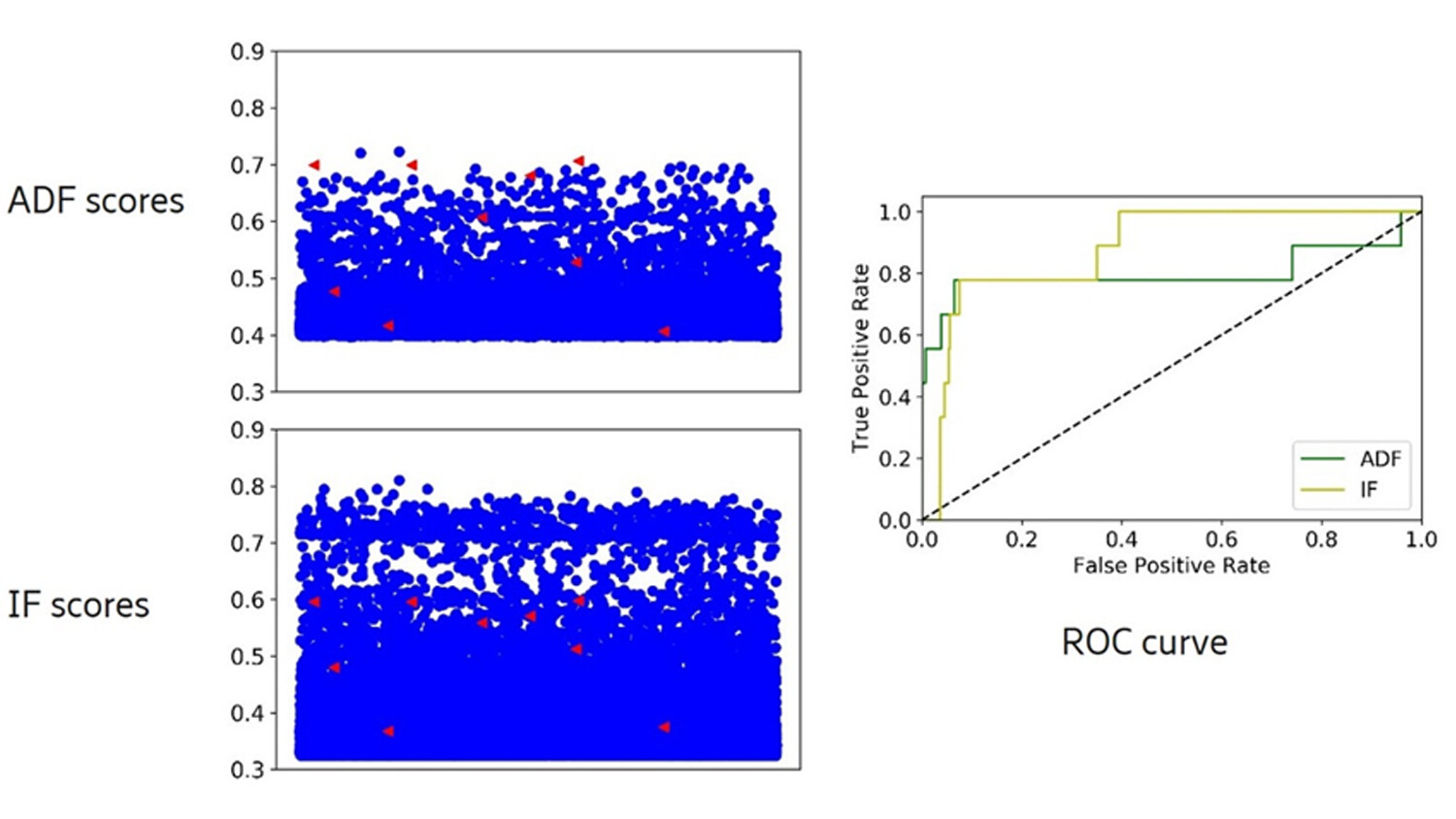
Figure 1: Anomaly scores and ROC curves for the KDDCup/smtp set. Red triangles are the true anomalies and blue dots the normal data points, both from a test set not used in training.
The new algorithm gives a relative boost in anomaly score for the highest scoring anomalies (shown in red triangles) for a popular dataset of internet traffic (KDDCup/smtp). This relative improvement compared to IF also corresponds to the curve of ADF being higher in the leftmost part of the “receiver operating characteristics” (ROC) plot. A limited alarm budget, as discussed above, corresponds to tolerating only a small fraction of false positives, which translates to focusing on the leftmost part of the ROC plot.
An ADF model consists of a chosen number of binary trees, and each tree is built from a random subset of the training set. The training steps shown in Figure 2 (below) are split into two phases: the subdivision phase, and the anomaly catcher phase.
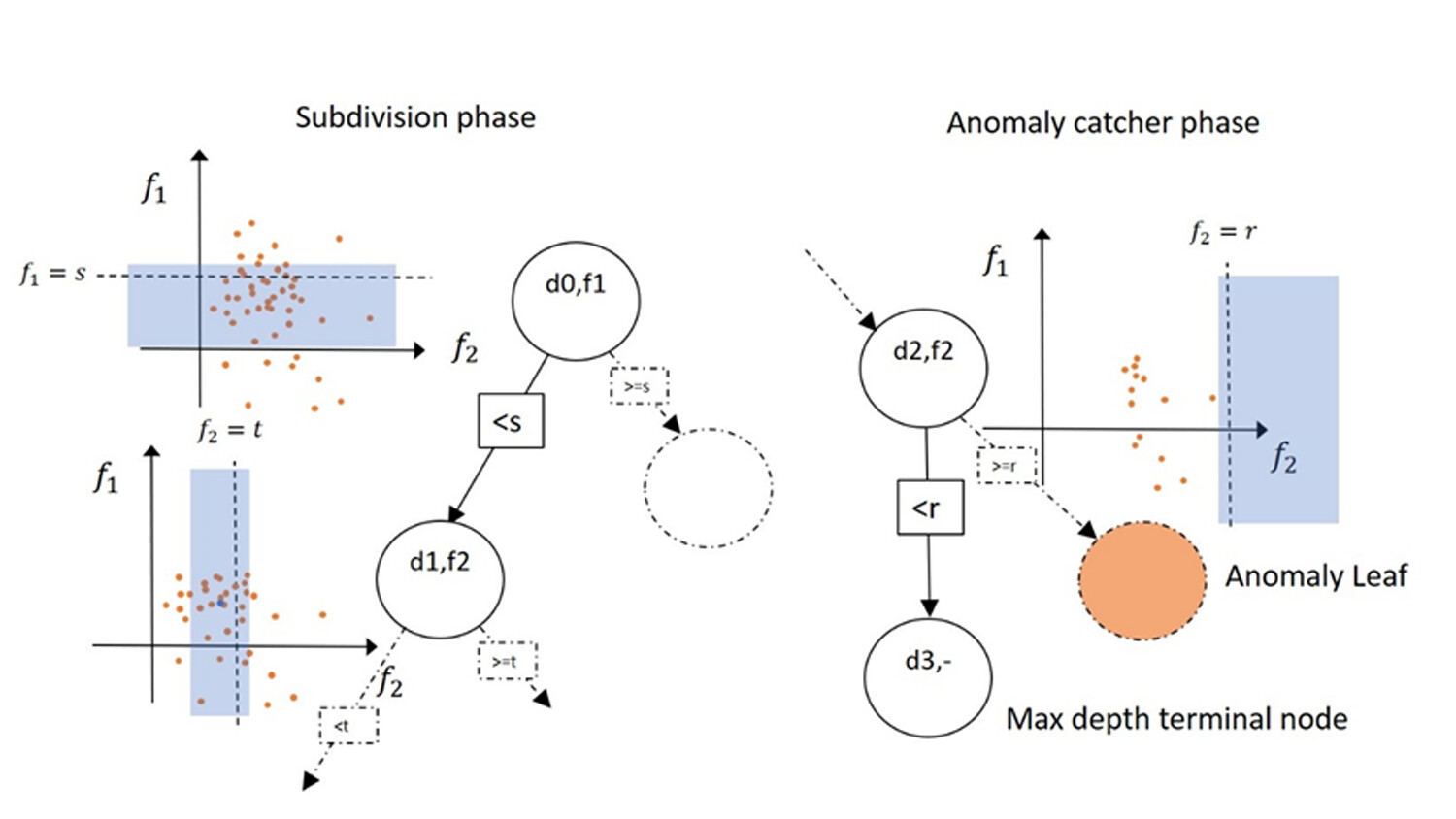
Figure 2: An illustration of how to build an ADF tree with a simple dataset with two features. A feature is picked at random in each node and a split value chosen from within the interval in blue. A comparison operator and the split-value for the node feature decides the edge to each child.
Starting at the root node, in the subdivision phase, the subset of a given node is split further by successively choosing a feature and a split value for that feature at random. This generates two new children nodes with smaller training sets. When the size of the set in a node is below a predefined limit, the training process for the corresponding branch changes into the anomaly catcher phase.
In this second phase, a feature is still chosen at random, but now the corresponding random split value is limited to being in a range outside the value range in the node subset. The altered training process of ADF ensures that all training samples of a tree will now be given low anomaly scores for that tree. Perhaps more importantly, the ADF training process also ensures that any sample showing deviations with respect to the training subset of a specific tree is given a higher anomaly score. For more details about ADF, see the full paper presented at ECAI 2020.
Overview of ML-specific attack threats
ML-assisted applications can be targets of attacks as any other ICT-system, but there are some ML-specific attacks called Adversarial ML (AML) that can be launched during training and inference.
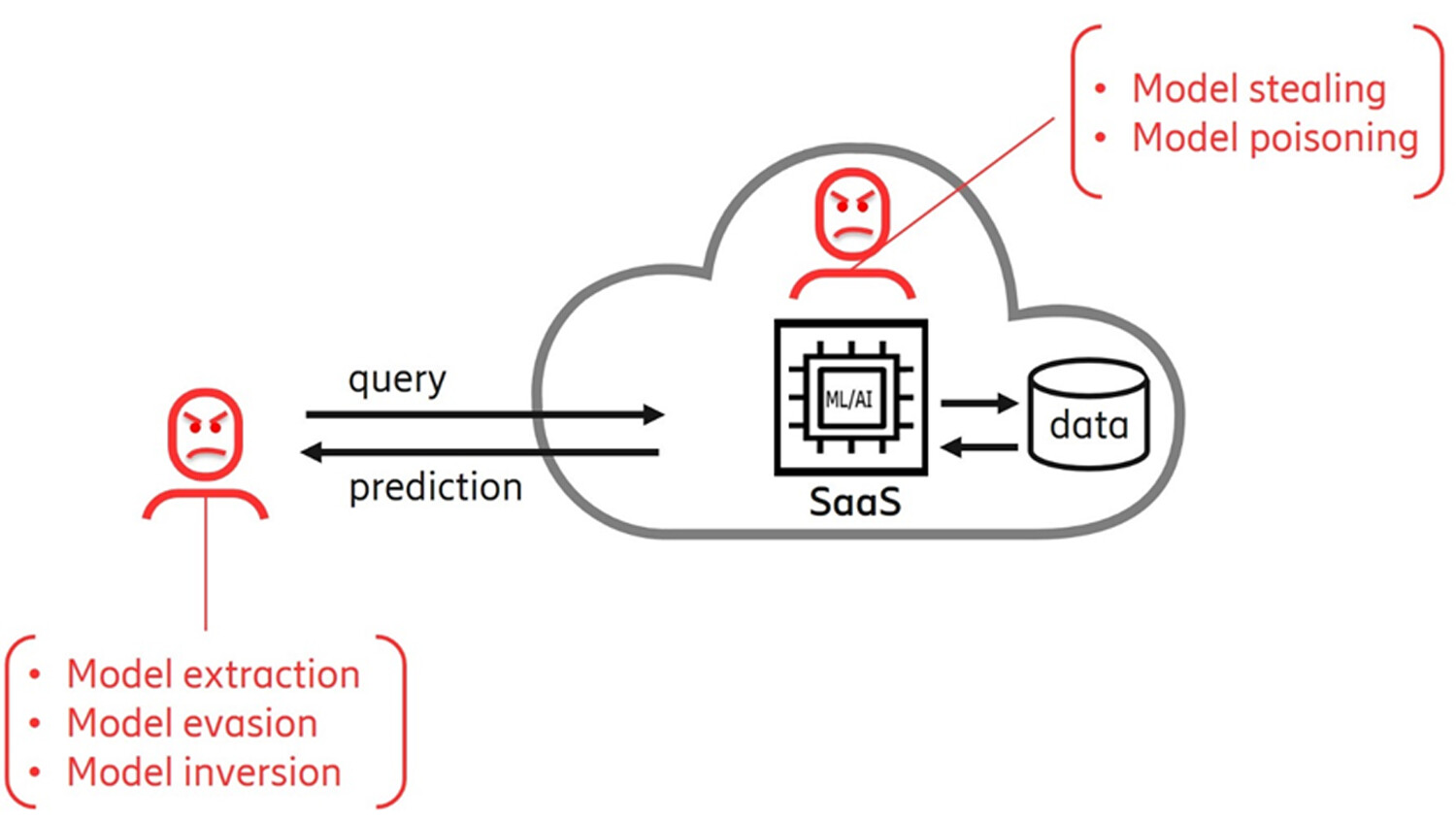
Figure 3. External adversaries abuse the API sending handcrafted queries to conduct attacks. Internal adversaries can directly attack the model and confidential datasets.
To illustrate how, let us take a typical ML-assisted Solution-as-a-Service, deployed in the cloud, as an example (depicted in Figure 3 above).
Normally, users have authorized access to the solution via an application programming interface (API) in order to send queries and get predictions. But external adversaries may also get authorized API access to attack the AI model. Internal adversaries, commonly called “insiders”, may manipulate the model and/or training data.
Some of the most relevant attacks are:
- Poisoning attacks whereby the insider adversary alters the data or the model with the purpose of introducing bias in the model performance so that the adversary can benefit from the biased outcome.
- Evasion attacks that search for small input perturbation that leads to output misclassification with the purpose of finding datasets where the model performs incorrectly. The adversary can then cause damage by misleading the system that relies on the model or benefits from it.
- Inversion attacks that attempt to extract or infer the data that was used to train the model. Depending on the application, this can be a privacy attack that can compromise personal data used to train the model. It can also be an attack to corporate data that was used.
- Extraction attacks that attempt to extract the parameters of the structure of the model. The adversary can then clone the model. If the model is a pay-as-you-go, then the adversary can use it for free or sell it as a service. Adversaries can also use the cloned model as a stepping-stone to discover evasion or inversion attacks on the cloned model and then use them to attack the original model.
The latter, model extraction attacks, are considered one of the most important class of attacks. Below, we take a closer look at why that is.
A closer look: The model extraction attack
The model extraction attack is a threat to ML intellectual property and can also be used as a stepping-stone for other adversarial ML attacks. The main motivation for such attacks can be, for example, to steal the model and then sell it, or simply just to use it without paying. Moreover, the replicated model can also be used for data reconstruction or in a testbed for attack evasion.
Unlike other threats, this attack does not aim to exploit a software vulnerability. But rather, with ML techniques, external adversaries send carefully crafted queries so as to get enough information to replicate the attacked model.
This approach is effective. Previous work shows that it is possible to replicate a widely used ML model just by sending 1485 queries to exposed API for 149 seconds, which costs only $0.15. Any ML service can be a victim, ranging from Machine-Learning-as-a-Service platforms operated by cloud vendors to small software modules providing predictions via API. They may keep replicated models in private and/or collaborate in a team to attack services.
One of the key questions for the attacker to carry out model extraction is which data points should be used to query the victim model. Since the adversary will typically not have access to the original datasets used to create the victim model, the adversary must instead obtain and use a similar input dataset. However, obtaining such data, even in small quantities, could be very difficult and expensive. An alternative can be to synthesize it either by data augmentation, assuming access to similar input dataset, or by data generation if the adversary has a good understanding of the domain.
Another challenge for the attackers is to query as efficiently as possible. There are strategies, such as K-center algorithm, for them to select the most promising set of inputs to be queried next.
The model extraction attack is a technique that has been rapidly evolving and published attack methods have been shown it to have a real-world impact. We also see that recent approaches use today’s state-of-the-art techniques, such as transfer learning, knowledge distillation and active learning.
How can we defend against model extraction attacks?
Model extraction defense is a relatively new area and is among the most popular research topics today. It also has its challenges. In the absence of information on the model extraction attacks, understanding adversary tactics and techniques in the real world, along with searching for reliable methods of verifying defenses from those attacks can be identified as two main challenges. New defense techniques should work both on tiny models and complex models, as well as needing to have less computational overhead.
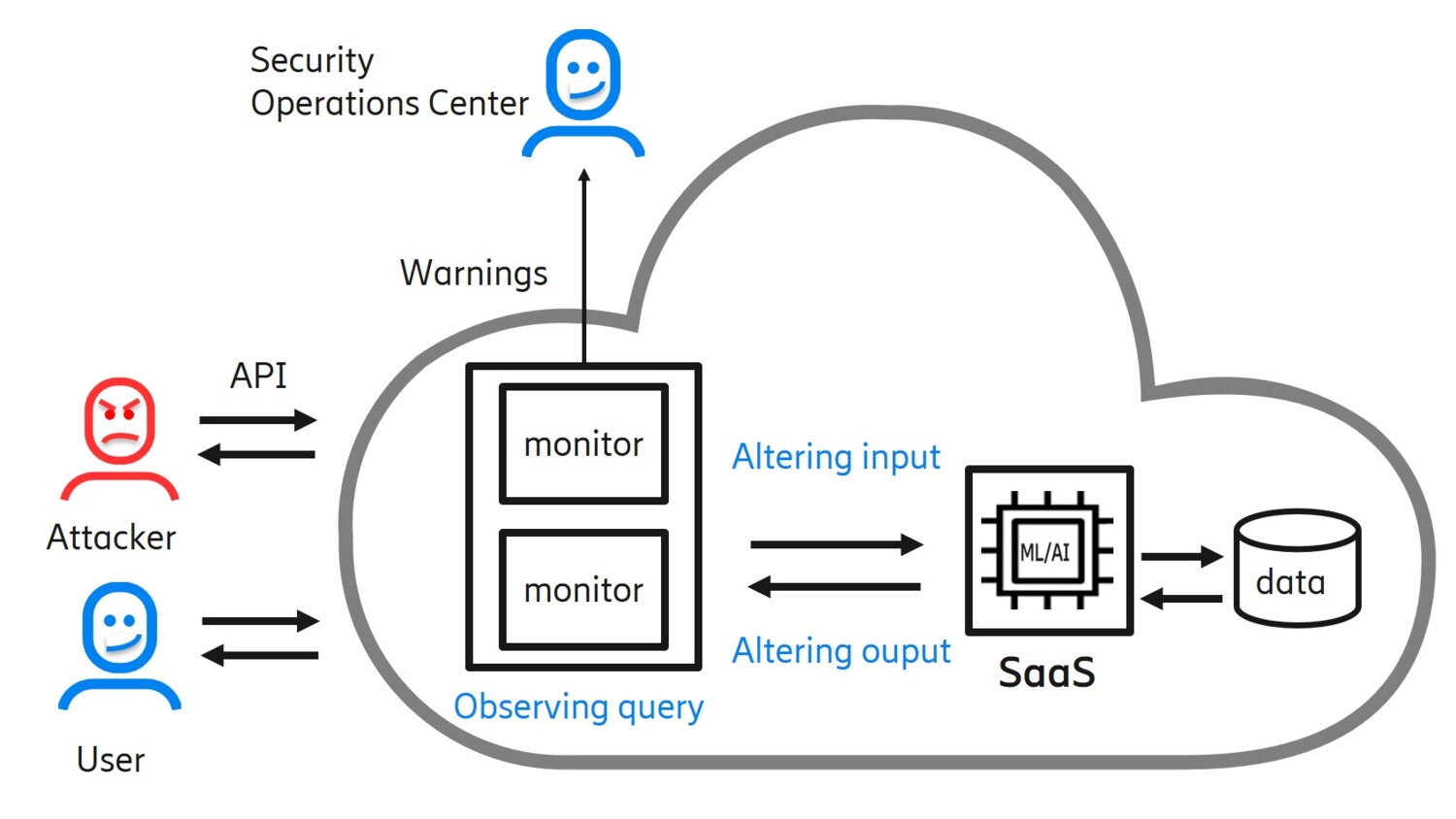
Figure 4: Overview of model extraction defense techniques
So what would be a solution to future model extraction threats? Attackers send queries in intelligent ways in order to extract the information. Therefore, we need to handle queries intelligently as well.
Altering inputs or outputs is one approach to prevent attackers from gaining too much information. The challenge is to give meaningful outputs while not providing unnecessary details that attackers can use. For example, we can send predictions at lower granularity or, in the case of a recommender system, we can be more abstract, for example by sending “top ten recommendations” instead of all the information.
Other ways of altering outputs include watermarking, which alters responses with slight changes that will be embedded into a model in case the outputs are used to replicate. Later, an owner can demonstrate ownership of the model by checking watermarks.
Another approach is to apply AI to observe incoming queries. This works by adding a new security monitoring AI-based layer, solely trained to detect abnormal queries, on the system in order to monitor API usage. Those monitors also maintain user contexts and then estimate extraction status for each user. If a monitored user has progress on model extraction exceeding a certain threshold, a warning will be sent to the SOC for further analysis and action. One way of doing this is that the monitor observes the query-response pairs made by each user and learns a local decision tree based on those pairs. An extraction status can be estimated by calculating a ratio of a local decision tree's information gain to that of a confidential model with respect to a validation set. Information gain, in the context of decision trees, can be measured by calculating the sum of individual entropies computed at each leaf node of the tree.
We also need to be prepared for such cases where adversaries collude to extract models. The monitoring algorithm described here can be adapted to detect such cases by estimating the extraction status for groups of colluding users instead of individual ones.
The importance of explainable AI for trustworthiness
We have described how AI and security rely on each other to address challenges in mobile networks. A related aspect that also deserves mentioning is AI explainability, as evidenced by the seemingly counterintuitive effect of so-called adversarial examples explored in numerous recent academic papers. An accompanying explanation of why the system reached the result could help understand such counterintuitive situations and aid in constructing protection against such manipulation.
AI explainability plays an important role in providing robustness and achieving trustworthy AI systems. Explainable AI is, of course, also very important to help interpret and investigate output for many applications of AI. But, in the context of AI-based threat detection, the target audience is the security community such as SOC personnel, security officers, and security developers among others. Here, AI explainability requires different tools and approaches compared to other application domains.
In addition to the topics addressed so far, Ericsson Research is advancing in other areas of trustworthy AI such as federated learning, machine reasoning, hardware-support for AI, thereby contributing to building trustworthiness in 5G and future mobile networks.
Read more
Learn more about our research on future network security.
Explore the latest trending security content on our telecom security page.
Find out more about intelligent security management.
Explore telecom AI
Explore AI in networks