An introduction to data-driven network architecture
Principal Researcher, Networks
Principal Researcher, Networks
Principal Researcher, Networks
What is data-driven?
Maybe you have heard of the term ‘data-driven’? A quick Internet search reveals that the term is used in many contexts. There is data-driven marketing, data-driven programming, there are data-driven businesses, and so on. It becomes apparent that data-driven is not just about technology; it is rather a mindset.
Data, not a functionality, is placed in the center. Data-driven simply means that decisions are made based on data. It has of course, always been the case that decisions are made on data or facts, but today this can be done to a larger extent than before.
There are a couple of underlying reasons why there is so much focus on data-driven recently. First, technology advancements in compute and networking capacity have made it possible to expose and transport data in unprecedented amounts. Second, technology advancements in Artificial Intelligence (AI) have made it possible to analyse these vast amounts of data in a way that was not possible before. These two factors enable numerous use cases where a machine can produce insights from data and do (better) decision-making based on data.
Why is data-driven useful for telecommunication networks?
Now you may wonder how this data-driven paradigm can be used in telecommunication networks. We split the telecommunications network often in administrative domains. Let me give you a couple of use case examples, one for each of the domains RAN, CN and OAM:
- In the RAN (Radio Access Network) domain, an AI algorithm could monitor the traffic of mobile devices and predict traffic patterns. This way, the system can assess when and where there will be no or very little traffic. The system can then autonomously decide to switch off (parts of) a radio base station, thereby saving energy.
- In the CN (Core Network) domain, there is a so-called paging procedure. Most of the time, mobile devices are in sleep mode to save battery. When there is an incoming call to such sleeping device, the network first needs to find the device and wake it up. This is called paging. The challenge of the paging procedure is that the network only knows where a device is approximately. If the network can predict more precisely where a sleeping device is, then the paging procedure can be done more efficiently.
- In the OAM (Operations, Administration and Maintenance) domain, data may be used as a basis for optimizing network management, customer experience analytics, service assurance, incident management, and so on. For example, an AI algorithm can predict when there will be potential loss in a service (like a throughput degradation) and take a corrective action before the predicted problems becomes reality.
There are lots of examples in literature; see for example an interesting survey of use cases such as Data-Driven Proactive 5G Network Optimisation Using Machine Learning.
The use cases above are examples of applying AI and Machine Learning (ML). The system analyzes large amounts of data and finds patterns (that is, it learns). These patterns can then be used, for example, to predict the whereabouts of a mobile device, or to foresee a coming disruption in a network service.
Another variant of AI is Machine Reasoning (MR). With MR the machine reasons with a conceptual representation of a real-world system and takes actions accordingly. Let me give you an example. Driving a car means interacting with the car: you use the steering wheel, the brake, the clutch, and so on. While driving, you observe the surroundings: the curve of the road, the brake lights of the car in front of you, pedestrians indicating to cross the road.
You also have certain skills: you know the traffic rules, you know how to accelerate and how to slow down. Finally, you carry out reasoning: If I see the car in front of me slowing down, I should get prepared to do the same. Or: I’m almost out of gas, let’s drive a bit more economically. You can easily see that reasoning can become quite complex, especially when multiple goals need to be considered simultaneously. Moreover, you also learn. You build experience each time you drive and use that experience to improve your driving.
Now let’s say we want to replace you driving the car with a machine driving the car. That’s where MR comes in. MR is simply the automated version of the car driving example. For MR to work here, a lot of data and different kinds of data are involved: the observations of the surroundings, the skills, the experience, the reasoning rules. All these are forms of data.
If you want to know more about MR in telecommunication networks, take a look at the article, Cognitive technologies in network and business automation. One example use case of MR is improving the management of the network. Today, humans oversee the running of the network and take actions when needed.
Can we use MR to automate this? What we ultimately want to achieve is a highly automated network that is managed with minimal human interaction. The system is trustworthy and can explain its action when asked for. This is the so-called zero-touch vision, and you will find more information on that in our blog post Zero touch is coming.
The zero-touch vision aims to achieve a so-called cognitive network. Curious what that means? Read more in the Future network trends article by our CTO.
What is a data-driven network architecture?
I have presented a couple of examples on use cases above. But this is just a glimpse. All in all, there are literally hundreds of AI/ML and AI/MR use cases for telecommunication networks, and the number is constantly increasing. Some of these use cases are already implemented in our products, and we expect to implement many more in the years to come. All these use cases have one thing in common: they all need data.
Let’s make an analogy to the real world. Let’s imagine that every use case is a vehicle: there are cars, trucks, buses, motorcycles, and bikes, for example. All these vehicles serve different purposes but need one common thing: an infrastructure. They need roads, bridges, and tunnels to get to their destination. The use of the infrastructure is guided by traffic rules and traffic signs.
There may be additional electronic information like maps and notifications on traffic jams and ongoing construction work. In our telecommunication network, the use cases mentioned before also need an infrastructure. We call that infrastructure the data-driven architecture.
The data-driven architecture provides the use cases with what they need to do their work:
- Data needs to be extracted from sources. We need to extract data efficiently. For example, extract only once even if there are multiple users of the same data.
- We may need to pre-process extracted data. For example, the raw data itself might not be interesting, we need to calculate some average over time.
- Data needs to be transported to the consumer. Transportation may be across a large geographic area, and might pass through organisational borders.
- Consumers should only get data that is relevant to them, not more and not less.
- Data should be available in time, since data often has a “best-before” date (for example, knowing that your train left 5 minutes ago is of little use. You want to know when the next train leaves).
- Access to data needs to be done in a secure way; not everybody might be allowed to access everything.
- All this needs to scale even for large networks.
How to implement a data-driven architecture?
So now you know what a data-driven architecture is, and what to use it for. You can imagine that designing a data-driven architecture is not a trivial task. So what is Ericsson Research doing to implement the data-driven architecture in our telecommunication networks? Well, this basically comes down to three things:
- We need to detail the data-driven architecture, make it concrete and define what building blocks it is composed of.
- Many of the building blocks are already being worked on. This can be inside Ericsson but can also be on a broader scale in different standardization fora in the telecommunications and IT industry. We need to have a clear picture of who is doing what.
- We need to identify the building blocks that nobody else is working on yet. We need to take action to start relevant work on those missing pieces.
In the coming sections, I will explain in a bit more detail some work we are doing on the three bullet points mentioned above.
What are the building blocks of a data-driven architecture?
The fundamental components of a data-driven architecture are probing and exposure, data pipelines, network analytics modules, and AI/ML environments. There is work ongoing on all these components. Here comes a brief overview:
Exposure of data from network functions builds upon management interfaces and probes. For cloud native environments, Ericsson's software probe provides a solution that incorporates virtual taps inside network functions, probe controllers and event reporting tools. This solution can be used for both control and user plane network functions and the consumers of Ericsson Software Probe can be any network analytics function.
Data pipelines consist of moving, storing, processing, visualizing and exposing data from inside the operator networks, as well as external data sources, in a format adapted for the consumer of the pipeline. As the first steps of a data pipeline, the Ericsson Data Ingestion (DI) Architecture specifies an architecture including data collection from sources, exposure to applications and storage in virtual data lakes. The DI architecture also defines data lifecycle management.
Another pipeline, the End-to-end Software (SW) Pipeline provides a method to install or update software in a continuous delivery fashion. When Ericsson makes new software packages available, these are pushed to the operator. The current End-to-end SW Pipeline also includes a feedback loop where logs and events from software packages running at the operator are sent back to the vendor, thereby closing the continuous delivery loop.
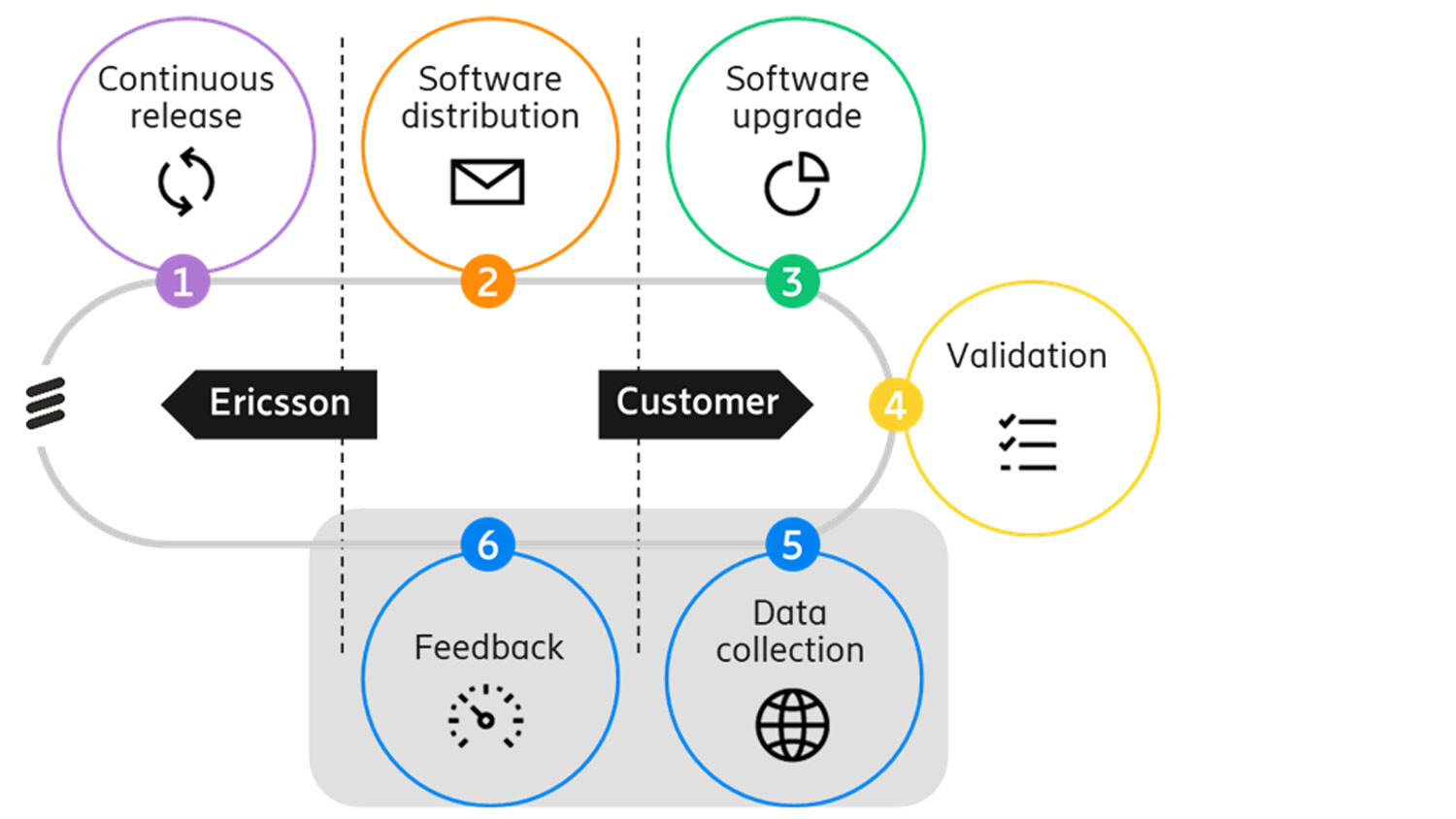
Figure 1: Ericsson's End-to-End SW Pipeline. The grey marked area is the scope of the Data Ingestion (DI) Architecture.
Network analytics functions inside the network can provide insights that enhance the network functionality. These insights can, for example, be provided for customer experience, service and application management. Network Data Analytics Function (NWDAF) and Management Data Analytics Function (MDAF) are examples of such analytics functions. Network analytics products have broad capabilities such as measuring and predicting perceived customer experience, ingesting, auditing and contextualizing data for service assurance and network operations, detecting incidents, performing root cause analysis and recommending solutions.
Future data-driven architectures will also support environments for ML. In ML, an algorithm is called a model. Contrary to traditional development where an algorithm is coded, in ML a model is trained. For model training and model execution, different learning modes are possible, such as local, central, federated, transfer, offline and online learning, depending on the requirements of the ML functionality. Model lifecycle management can be divided into two phases: 1) data preparation, modelling and validation; and 2) deployment and execution of the models.
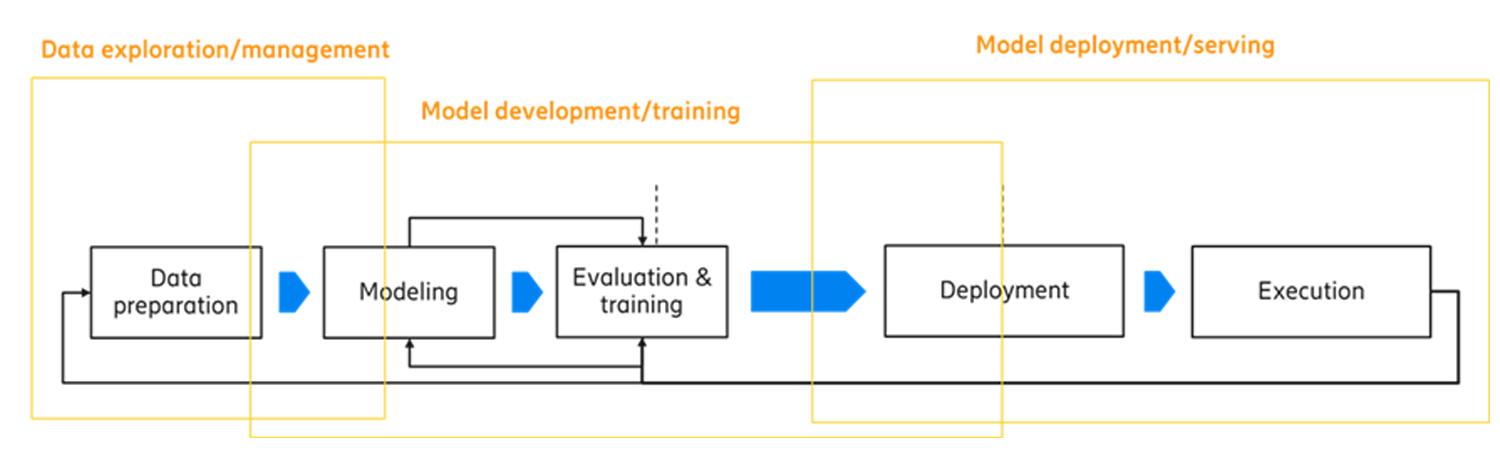
Figure 2: Model lifecycle management.
How can we combine the building blocks?
Combining the building blocks above, we can envision the picture below showing an end-to-end data-driven architecture.

Figure 3: Ericsson’s data-driven architecture.
At the lower part of the picture we see the network’s domains OAM, RAN, CN. There may be additional domains like transport or cloud infrastructure, but these are not shown here. Note that we define OAM in a broad sense. OAM includes not only domain/element management, but also orchestration on various levels, all OSS (Operational Support System) functions including end-to-end user/service/slice management, and so on.
Components in the different domains may expose data to a distributed bus/database. For example, the network functions in the CN domain may use the Ericsson Software Probe to do exposure. There may also be external sources at the Data network (DN) exposing data. The DI architecture defines how to collect, route and distribute data. In the picture above, the data may be used at three different levels.
The first level where data may be used is indicated by arc number 1. This arc is based on the End-to-end SW Pipeline (see Figure 1). The current End-to-end SW Pipeline feedback step (step 5 in Figure 1) provides a means to send logs and events back to the vendor. The End-to-end SW Pipeline incorporates the DI architecture in the feedback step. This would allow the vendor to train models at the vendor’s premise, and then install trained models as a software package at the operator. In other words, the End-to-end SW Pipeline can use DI such that the combination gives a rudimentary model lifecycle management for central learning. The current DevOps environment at the vendor evolves to also include DSE, making it a DataOps environment.
The vendor’s environment not only includes a DataOps part. The vendor may also use the data for managed services. Also note that parts of the vendor’s environment may be provided by a third party. For example, some of the compute facility may be hosted at a third party.
The second level where data may be used is indicated by arc number 2. The operator itself may have a DataOps environment as well. Just like the vendor’s DataOps, data may be used to produce new insights, to train models and install them, or to optimize the configuration of the system.
By building on data from several operators’ networks, a vendor can create more powerful data-driven design than the individual operator. It should be noted however, that even though it is technically possible, there can be both legal and business limitations that hinder data from leaving the operators network. These limitations can be addressed with new ML technologies, such as secure collaborative learning (a secure variant of federated learning), allowing the learning of a global model without sharing data used for the local training.
The third level where data may be used is within the domains as indicated by the arcs with number 3. This could be within a network function, or between network functions within the domain. An example of the latter is a NWDAF analytics service using data from the Access and Mobility Management Function (AMF).
What is already ongoing in standardization?
Initiatives are taken in different standardization organizations and alliances, which will affect the evolution towards a data-driven architecture. The more influential alliances we have identified are the following:
3GPP SA2 defines the NWDAF, a network function which is part of the CN which provides insights that enhance the CN functionality. NWDAF services include statistics/predictions of user mobility patterns, user communication patterns, user service experience, slice or network function load, and so on (3GPP TS 23.288). There are proposals to add additional services that span towards the RAN and the application domain.
3GPP SA5 defines the MDAF as part of OAM. MDAF can be deployed at different levels, including at domain level (for example, RAN or CN) and at end-to-end level (for end-to-end assurance as part of the overall OAM, for example).
O-RAN is an operator-led alliance for the evolution of the RAN and disaggregating the RAN architecture focusing on data-driven architecture functions. O-RAN has specified the logical functions called non-real-time RAN Intelligent Controller (RIC) and near-real-time RIC. The purpose of both RICs is to optimize the RAN performance using AI/ML agents running in the RICs.
ONAP (Open Network Automation Platform) provides a reference architecture as well as a technology source. The ONAP subsystem Data Collection, Analytics, and Events (DCAE) provide a framework for development of analytics. For example, the DCAE can implement the 3GPP NWDAF. DCAE is designed for scalability and to be deployed hierarchically which may support distributed machine learning principles like federated learning.
ETSI ZSM (Zero Touch Network and Service Management) specifies an architecture for zero-touch operations at the end-to-end level by connecting different domains (for example, RAN, CN, transport, edge cloud, etc.). The group focuses on artefacts that allow data exposure and governance and the outcome is an overall framework for multi-domain management that re-uses specifications from other organizations such as 3GPP SA2/SA5.
ITU-T SG 13 ML5G (Machine Learning for Future Networks including 5G) proposes a standardized ML pipeline. This includes model lifecycle management, how to treat the different characteristics models have, monitoring model performance and triggering re-training, transferring models, etc. The work of ITU-T SG 13 is meant to be an overlay to the 3GPP architecture.
Another significant organization that may influence forming of a data-driven architecture is TM Forum.
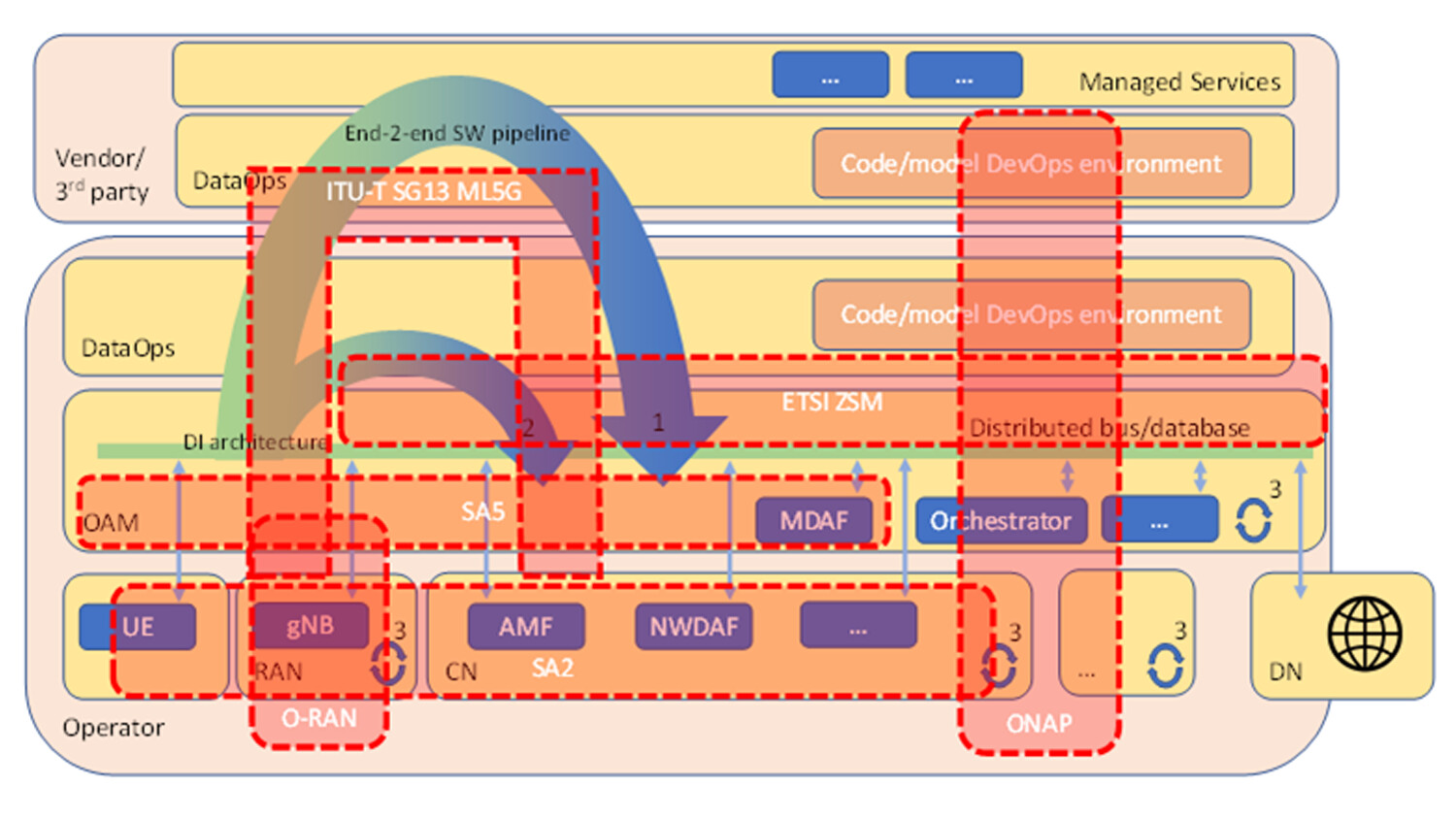
Figure 4: The scope of each standardization organization mapped to the data-driven architecture. Note that this is a rough mapping to get an idea; it is not 100 percent correct. For example, ONAP spans multiple domains including RAN.
What are the next steps?
As I’ve tried to show above, the evolution towards a data-driven architecture is ongoing and has already come quite far. What are the next steps? At Ericsson Research we try to focus on challenges that lie a little further ahead. Simply put, we assume that the architecture described above is already there and try to assess what the consequences of such architecture will be in the long run. Example research questions include: How will data-driven architecture evolve the current 3GPP architecture? How do we do model lifecycle management? How would new AI technologies like reinforcement learning work in data-driven architecture? How will distribution in learning and decision-making impact the architecture? How do we scale when the architecture is deployed over a large geographic area? What are the trade-offs when it comes to the cost of running data-driven infrastructure versus the gains that the AI use cases using the infrastructure offer?
To summarize, data-driven means that decisions are made based on data. This has always been the case, but it can now be done to a larger extent than before. The difference today is that data from different parts of the distributed telecommunications network is reachable and can be combined, processed at large scale, allowing near real-time operations.
In the context of networking, data allows AI algorithms to make better decisions, thereby optimizing the performance and management of the network. There are hundreds of data-driven use cases defined, and we expect many more to come. All these use cases require an infrastructure, and this is what a data-driven architecture is about. It provides an inevitable infrastructure to enable AI/ML and AI/MR. Such infrastructure will be needed to achieve the vision of a zero-touch cognitive network.
Want to know more?
Read Ericsson’s full Technology Trends 2020 report.
Here are 3 ways to train a secure machine learning model.
Learn more about Ericsson’s work with AI and automation.
Read Network Automation
Read more about Core network
Explore 5G
Explore the fundamentals of modern network architecture and how it is driving a new era of agile, cloud-native network operations.
Explore modern network management approaches that give you greater visibility and control across today's increasingly complex networks.