Cognitive networks – towards an end-to-end 6G architecture
Principal Researcher, Networks
Master Researcher, Artificial Intelligence
Principal Researcher, Artificial Intelligence
Principal Researcher, network automation
Research Leader, Network automation
Principal Researcher, Networks
Master Researcher, Artificial Intelligence
Principal Researcher, Artificial Intelligence
Principal Researcher, network automation
Research Leader, Network automation
Principal Researcher, Networks
Master Researcher, Artificial Intelligence
Principal Researcher, Artificial Intelligence
Principal Researcher, network automation
Research Leader, Network automation

Operating large numbers of digital services with different requirements will demand a new approach to network management where a high degree of autonomy in the operational processes will be required, eventually achieving a zero-touch network.
To prepare the network for these challenges, we need to make it more intelligent, and the approach we have taken is what we call the cognitive network.
As we explained in our previous blog post, cognition is a term from psychology and refers to an “action or process of acquiring knowledge, by reasoning or by intuition or through the senses.”

Humans perceive what happens around them, they reason about those perceptions, combine those with previous perceptions, draw conclusions, and act to reach a certain objective. A cognitive network will work in a similar way, using the capability to observe, reason and then act accordingly. It will operate autonomously by making complex, intelligent decisions that could only previously be done by humans.
Cognitive technologies are the enabling techniques that enable the implementation of cognitive capabilities to a technical system. This requires artificial intelligence (AI) techniques including machine learning and machine reasoning, as well as adaptive data and knowledge management.
Through observations, the cognitive network can, for example, autonomously find patterns in resource usage and take actions to optimize this usage towards an objective. A cognitive system has the capability to evaluate its actions based on a defined utility function. This makes it possible to determine what action has the most preferential effect. This way, the autonomous system can adapt itself not only to new situations in the managed environment, but also to a broad range of business objectives.
A cognitive network achieves a higher level of autonomy and effectively relieves the human network operator from direct network management tasks such as the decision on solution strategies to reach objectives, and the execution of operational actions. Thanks to the development of cognitive networks, the tasks of the human workforce will eventually shift towards monitoring and supervising. This includes guiding the network in its learning and decision processes as the network gradually becomes more autonomous and self-managed.
More autonomy in the network also means that humans are interacting with it by setting requirements and goals that reflect the operator’s business objectives and customer needs. Intent is the mechanism for communicating these requirements, and it is defined as:
“The formal specification of all expectations including requirements,
goals and constraints given to a technical system.”
If we want the network to be autonomous, we need to give it a certain level of freedom to choose its actions. By using intents, which specify what to achieve (not how to do it), the cognitive network can find solution strategies for meeting these requirements without further instructions.
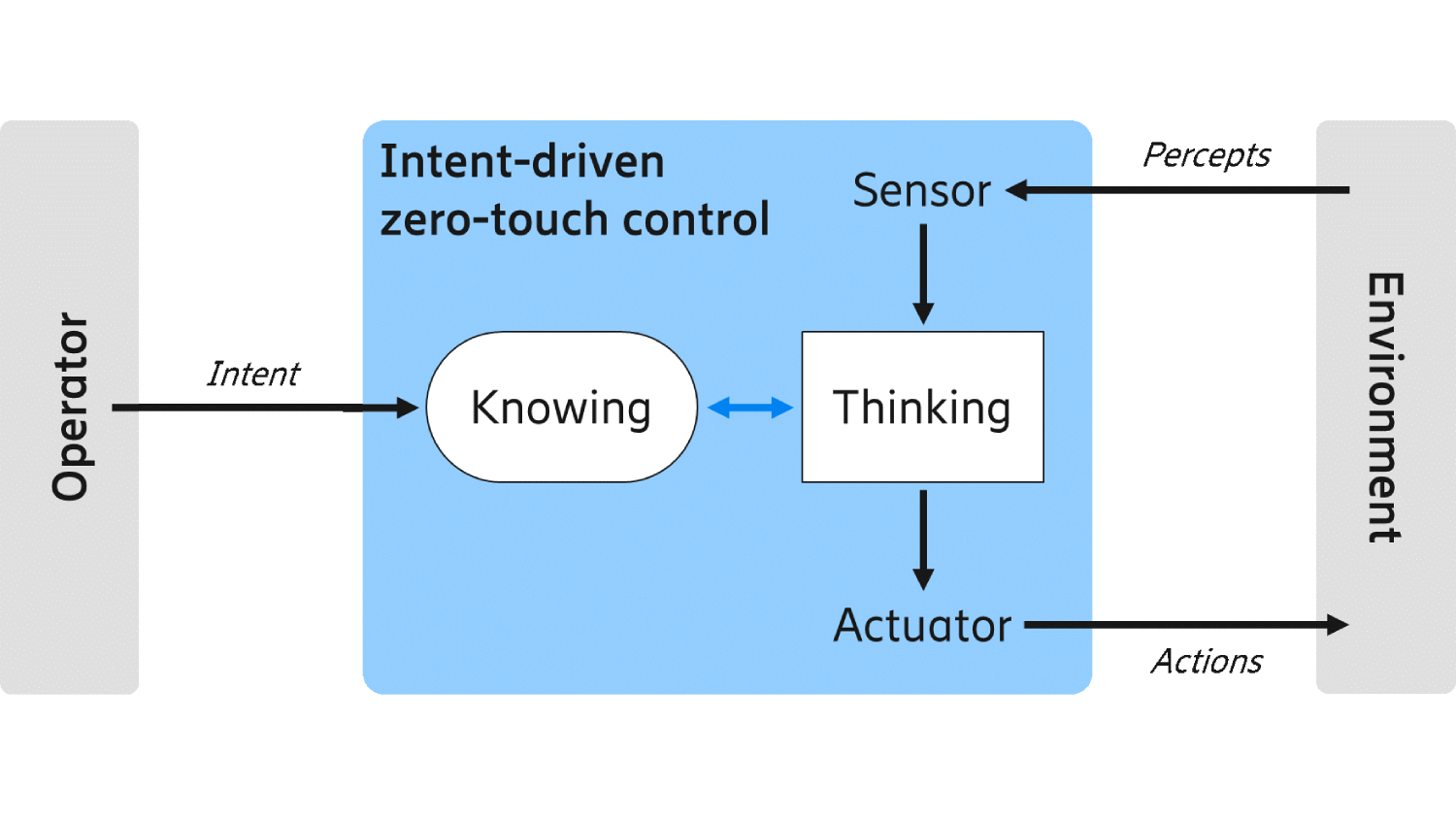
Figure 1: High-level view of an intent manager (blue) controlled by intents, where the intent manager monitors an environment and controls it through actions.
How do we realize this vision of a cognitive network? One way to start is to analyze what would characterize a cognitive network. Figure 1 above gives a high-level overview of a cognitive network where an intent manager controls an environment. Figure 2 below is a generalization where several layers interact to control the different aspects of the network environment. In this hierarchy, each layer may contain one or more intent managers that receive intents and process them to make sure the objectives stated by the intents are fulfilled.
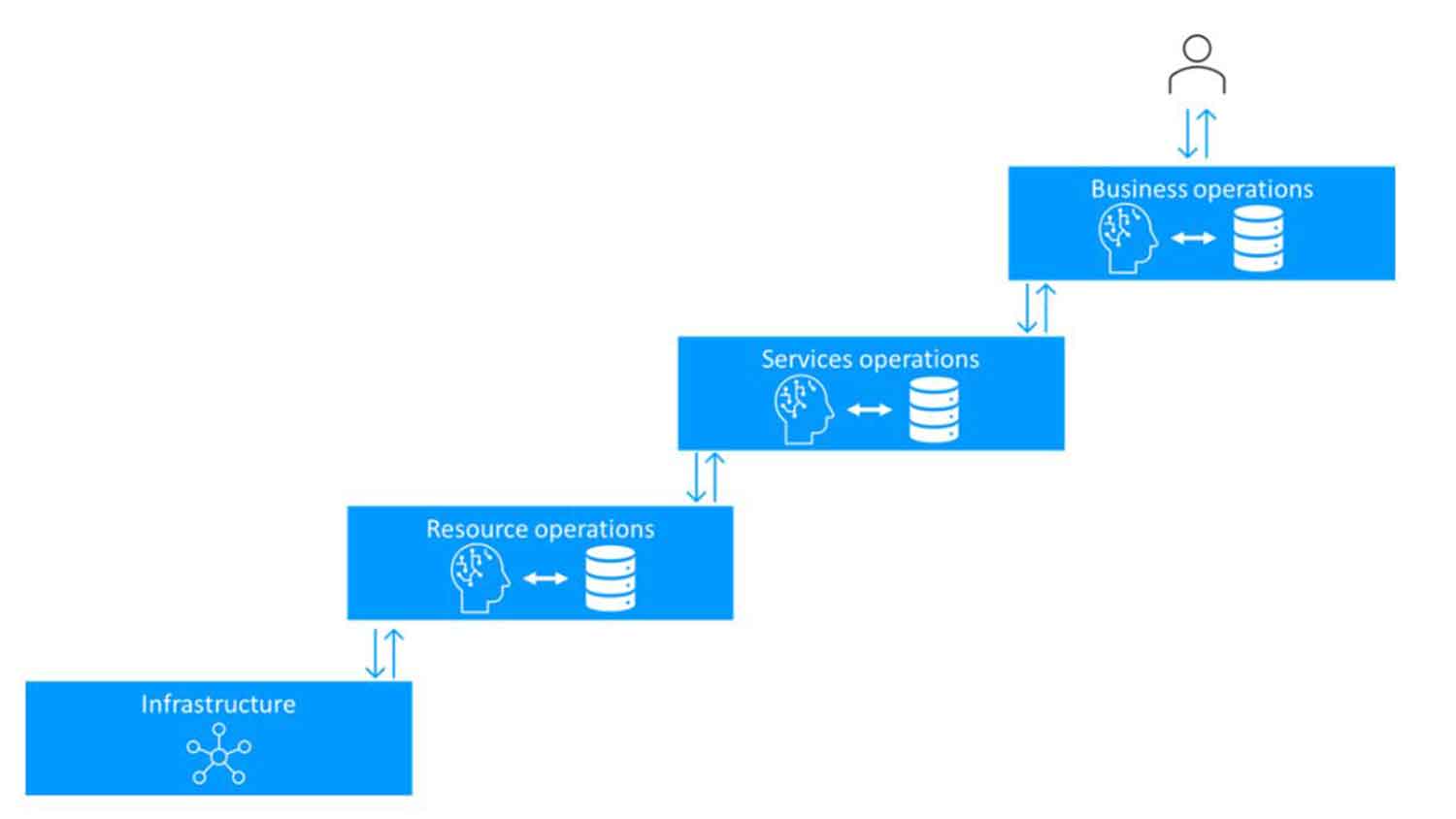
Figure 2: The cognitive network with several layers, all interacting through intents. In each layer, one or more intent managers are responsible for handling all intents given and take the right actions to fulfil the intents.
Because intents state what goals to achieve rather than how to achieve them, the resulting interface is different. Today, in many control interfaces, a system exposes what it is offering to do. It is exposing processes, and another sub-system can use and invoke them if it wants to perform the exposed actions. This creates a workflow for tasks that spans multiple sub-systems and system layers. It also introduces a relatively tight coupling between the sub-systems. It also means that one sub-system directly instructs the other sub-system what to do and how.
With the introduction of intent, the communication between sub-systems shifts towards setting requirements rather than invoking actions. This decouples the information of what needs to be achieved from the processes and actions that are executed for doing so. This strictly separates concerns and allows the buildup of sub-systems that can decide and act autonomously within their domain of responsibility and expertise.
Evolved system architecture – outlook towards 2030
To realize the cognitive network, there are some key areas in the network architecture that will evolve to support the needed capabilities for optimizing performance and operational efficiency. In our previous blog post, we defined six technology enablers:
- Data-driven operations
- Distributed intelligence
- Continuous learning
- Intent-based automation
- Explainable and trustworthy AI
- Cognitive system
We’ll now focus on the expected results of applying these enablers. In the following section, we describe the foreseen evolution from functional, deployment, and responsibility viewpoints.
Let’s start with a view on the current network system as in figure 3.
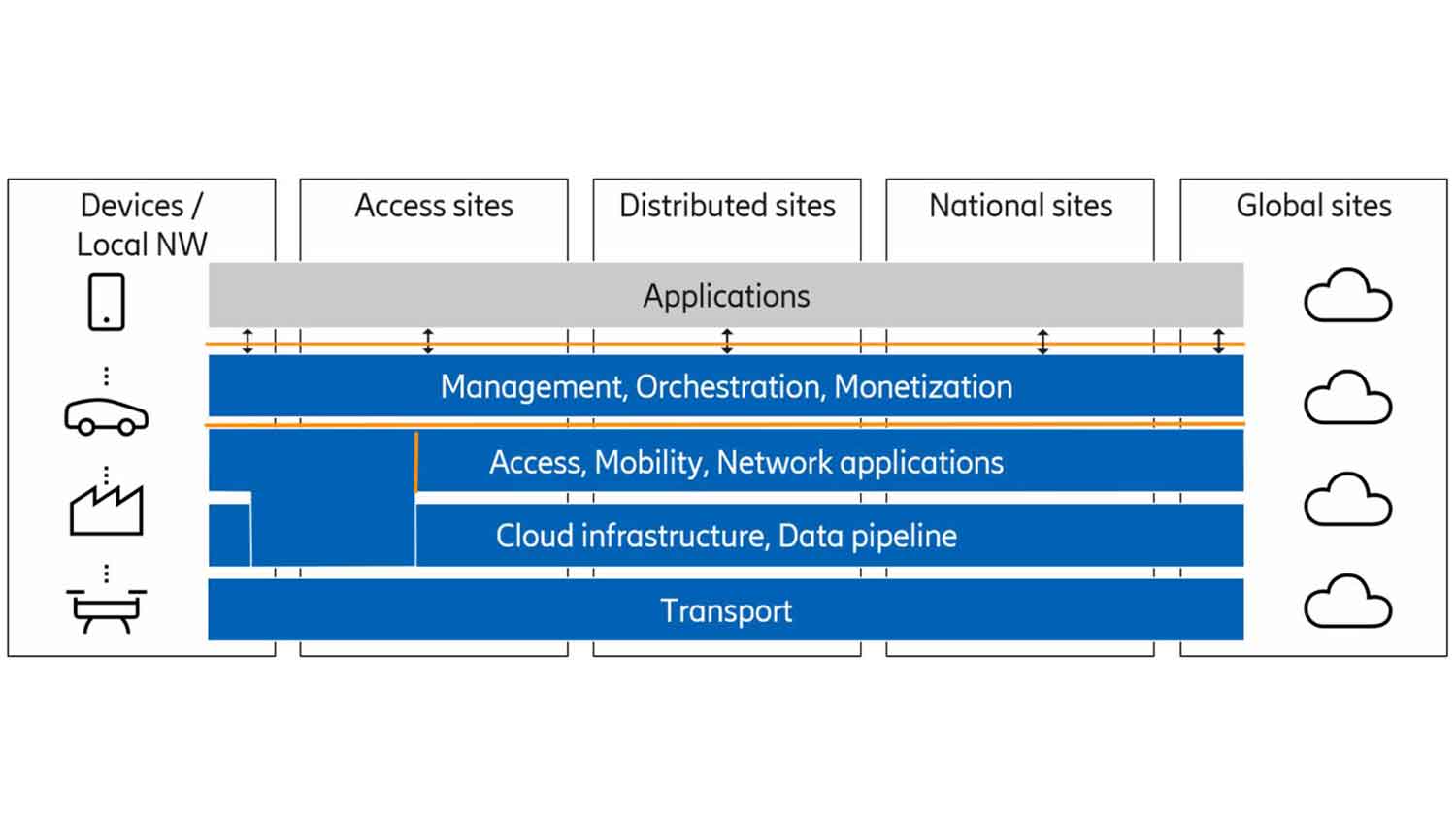
Figure 3: Network system architecture
The physical deployment is shown on the vertical axis: devices, access, distributed, national and global sites. Over time, there’s also been a gradual evolution towards the horizontal layered architecture, with transport at the bottom, followed by cloud infrastructure, network applications, and a management/monetization layer. The latter is represented by OSS and BSS in today’s network systems.
All this adds up to a foundation allowing applications at the top layer to make use of and interact with services provided by the network platform.
It should be noted that in the access, the RAN applications are integrated with underlying infrastructure to achieve the needed performance and take advantage of accelerator hardware.
Functional view
Going one step deeper into the cognitive network technology journey, we have identified areas where we see that major change and evolution will happen. Figure 4 below shows those areas. Functionality is indicated at a certain point or with a symbol in the architecture. This is a simplification to give examples rather than the full picture of new and evolved functionality, further explained in the text.
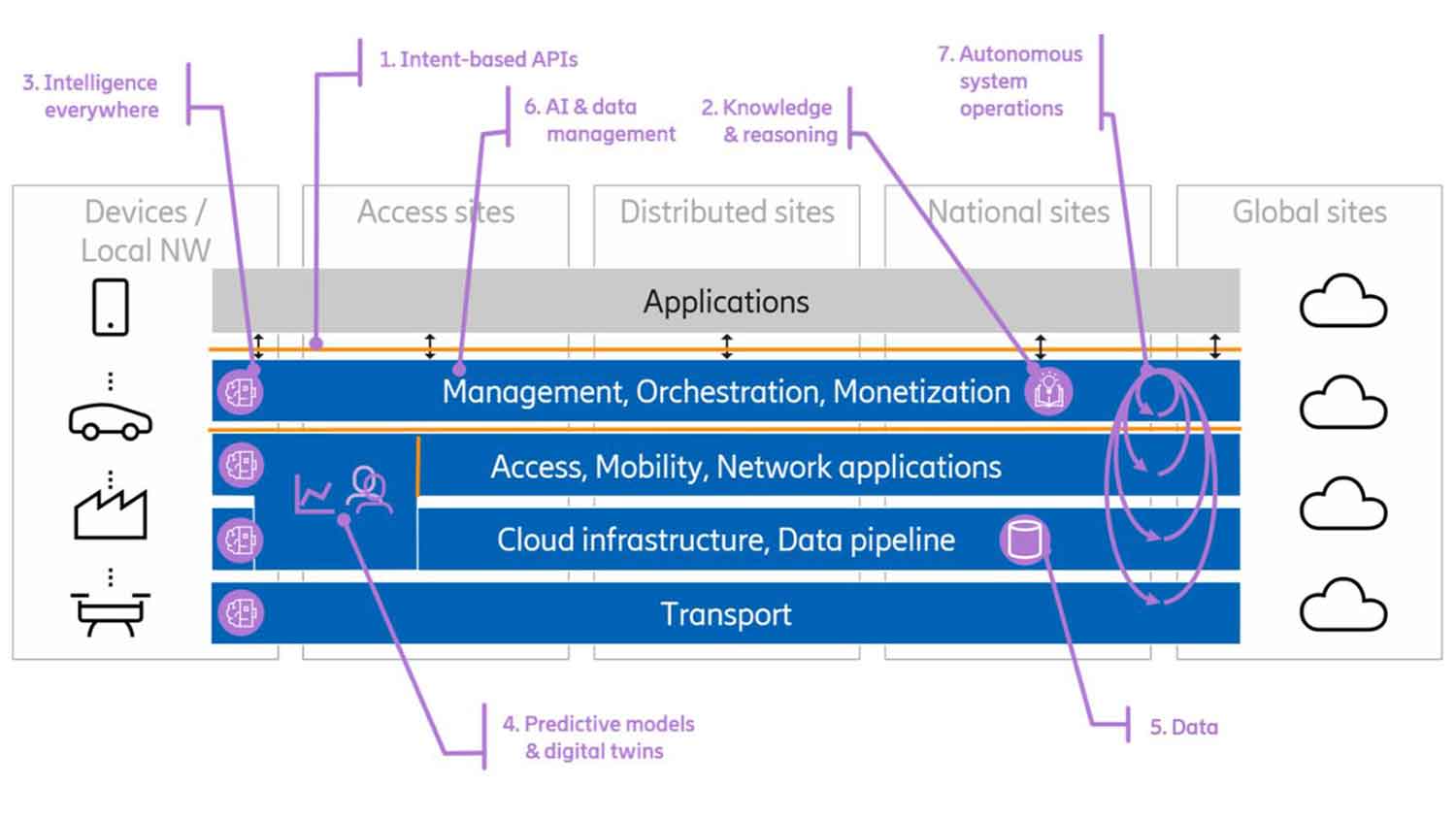
Figure 4: Cognitive network system - functional architecture view
- Intent-based application programming interfaces (APIs) will be used at many interfaces to formally capture the operational goals of different parts of the system in a measurable way. At the top level, human intentions would be translated and given to intent managers as formal intents. Higher-level intents would then be transformed and decomposed into lower-level intents by intent managers, which capture objectives and goals representative on each specific level. On an infrastructure level, these could be processor loads or the utilization of a router interface, whereas on the service level these could be frame rates and resolutions for a user of an augmented reality or virtual reality service. Different parts of the network would also interact via intents, where RAN could steer a transport domain through an intent-based interface.
- A cognitive network will capture and work with abstract knowledge. With machine reasoning capabilities, the operations systems will determine the right decisions and course of action based on logical reasoning and deduction. In this way, we advance from finding patterns in past experiences to understanding cause and effect, and can combine different knowledge items to new insights. As a result, the cognitive network would also be able to handle unknown situations that have not yet occurred. Intents, mentioned above, are a special type of knowledge.
- Intelligence will be present throughout the network, from applications and management to lowest level infrastructure. The scope of different algorithms will range from very focused, tuning a specific parameter in a specific location, to algorithms overseeing and steering complex operational procedures with many different objectives and control targets. The actual algorithms include AI methods trained on observed data or in simulators, formal methods, and heuristics, depending on the fit to specific requirements. These algorithms would to a larger extent be lifecycle managed (trained, developed and deployed) separately from the application logic. To ensure that trust in the system is maintained, there is also a need for explainable AI technologies that can explain decisions taken by algorithms.
- Predictive models and digital twins will enable a smooth interaction of the different control loops running in parallel in a complex autonomous system. The loops will interact, either directly or via the use of shared resources. As a result, control actions to improve one aspect of the system (for example, a service KPI) can have a negative impact on a different aspect (for example, energy consumption of a different service). Before actions are taken, a cognitive network needs to understand the impact on both service and infrastructure levels. Then, different KPIs and objectives can be evaluated and balanced to make the best choices from an overall system perspective. These models can focus on a specific aspect or part of the network, or they can have a wider scope. One approach is to create a digital twin of the network, where the state of the network (or a specific network domain) is monitored in (near) real time to create a mirror image. Using behavioral models and prediction tools in the digital twin, we can evaluate different actions and scenarios in a virtual environment without touching the real network.
- Data is essential in a cognitive network and needed to train AI models, analyze the current situation, and take correct decisions. Detailed observability is needed from all functions in the network to monitor state and performance. At the same time, we cannot measure everything at all times. Therefore, we need highly configurable interfaces for measurements and data, and flexible data pipelines to make data available at the right location at the right time in a secure way. In most cases, these pipelines include some form of preprocessing to adapt raw data to useful input for training, monitoring, and decisions. Data also needs to be stored and catalogued to be made available for later use. In addition, there are data privacy and ownership aspects which need to be managed properly.
- Today’s orchestration and management systems need to expand their responsibility domain to also include management of AI and data. While some existing aspects of software and network management in a distributed infrastructure apply here too (for example, placement of functions that require hardware acceleration support), there are new aspects that need to be considered (for example, data annotation, lifecycle management, training workloads).
- Finally, we bring these different technologies together to form an autonomous system which understands operational objectives given as intents, and then determine complex sequences of actions to fulfil these intents in the best way. In this process, different control functions and algorithms will be assembled to form many control loops, each with a different purpose. The procedures to dynamically set this up need to be in place, as well as methods to govern the resulting system of interconnected control loops. This would cover all aspects of the 6G system: business, service, resources, and all technology domains (RAN, core, cloud, transport).
Deployment view
In the deployment view we focus on the different sites that host the functionality of the cognitive network.
Data-driven operations will be one essential approach in the cognitive network. Figure 5 shows a deployment view with several components for data-driven operations based on data made available to the developing organization’s global sites. In this deployment view, the importance of the horizontal layers is subordinate, and the placement of the components in the figure does not relate to the horizontal layers in the background.
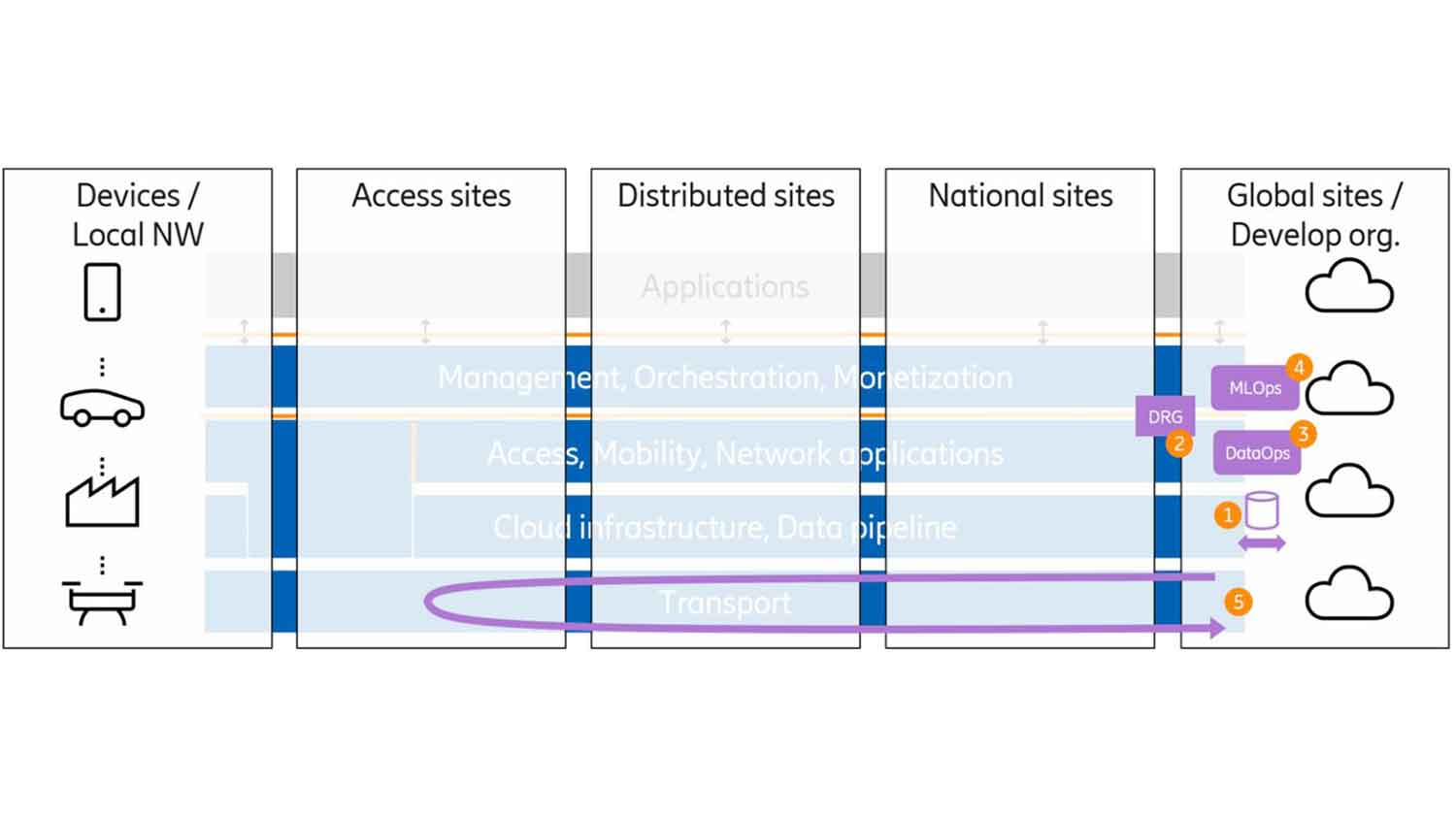
Figure 5: Deployment view - components at the developing organization’s premises
- Data Ingestion components. These are the components of the data ingestion architecture including data collectors, data catalogs, data routing and distribution and bulk data repository.
- The Data Relay Gateway (DRG) is the data ingestion architecture component that transfers data between the Communication Service Provider (CSP) and the domain of the developing organization.
- A Data Operations (DataOps) environment is used for feature engineering. Raw data collected by the data ingestion architecture is analyzed, filtered, extracted, pre-processed into a data set more suitable for AI model training. This data, and the rules used for feature engineering may be saved in a feature store. The DataOps may benefit from hardware acceleration support such as in-memory computing.
- A Machine Learning Operations (MLOps) environment is where ML models are developed, trained, validated and stored. Training is based on data from the DataOps feature store. Note that training data may also involve feedback from models that are already up andrunning. The MLOps environment may benefit from hardware acceleration such as Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs).
- Model lifecycle management will support the distribution of trained models and feedback information on model performance to trigger model updates due to performance degradation. Distribution can be to any type of site; access, distributed or national.
Figure 6 shows a more complete deployment view, with cognitive network components both at the developing organization’s sites but also at the CSP sites. Apart from the data ingestion, DataOps, and MLOps components, two additional components are presented.
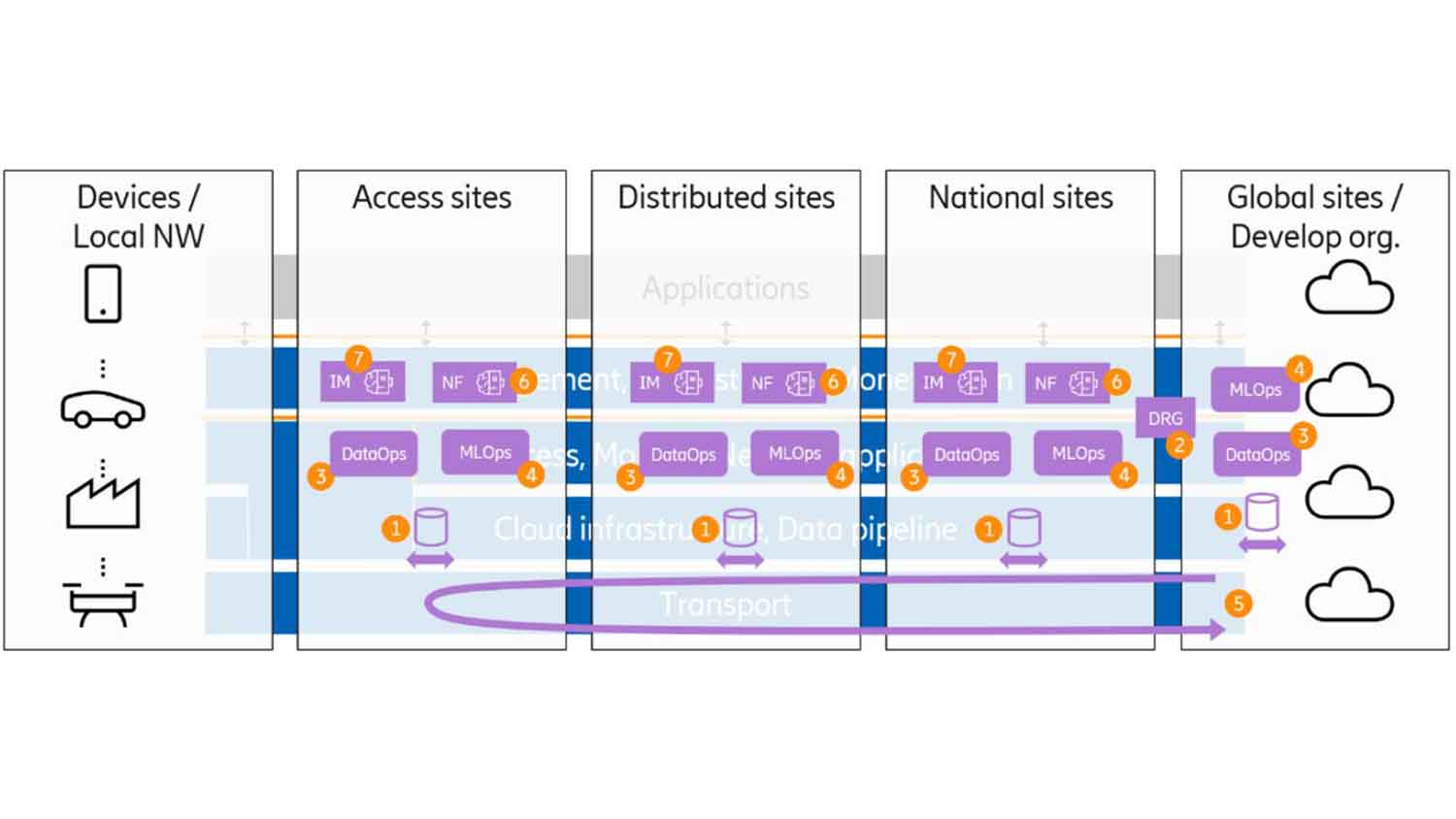
Figure 6: Deployment view - components at the CSP and the developing organization’s premises
- Intent Managers (IMs) will be distributed across different locations depending, for example, on their control scope, their required knowledge base, or their required data sources. They use trained models and consume data for both model inference and continuous learning.
- Network Functions (NFs) like gNB, AMF, SMF and MDAF may contain intelligent components (that require data and trained models) and may also be controlled by intent managers or separately deploy intelligent algorithms. Depending on the nature of the control loop (for example, timing requirements or availability of input data), these could be deployed on the same site/server or distributed across different sites. Note that NFs may contain multiple components that, in a deployment view, may be spread across multiple sites.
An observation from figure 6 is that most components may reside in any site type. There are multiple reasons for why all components end up everywhere. Some of these are:
- Data may be bound to privacy or national legal aspects. It may not be possible to transport data outside a jurisdiction.
- Inference of models and closed loops may have real-time aspects. Data may have ‘best before’ constraints. This means that control components and the control target may be constrained to a certain site. And since these intent managers and NFs require data, the DataOps and data ingestion components get constrained to the same site.
- There are multiple distributed ML training technologies, including transfer learning, split learning, horizontal federated learning, and vertical federated learning. Which technology to choose depends on the use case. Distribution may be across sites.
- Acquiring data, pre-processing data and training models may involve specialized hardware that is only available at certain sites.
- In reinforcement learning, training and inference are combined. This may be constrained to a certain site for the same reasons as already mentioned above; including real-time constraints, required hardware support or legal constraints.
- Configurations need to be dynamic to enable a variety of network offerings. We need to support all kinds of deployments from small-scale non-public-networks (NPNs) for a local industry, to large-scale distributed networks supporting the energy industry, to national or even worldwide scale mobile broadband deployments.
What is the consequence of all this? Today, we have orchestration for software components as a part of application lifecycle management. From the above, it becomes clear that we need to extend this with orchestration of data (what to store and where, what to transport and where), orchestration of training (what to train and where) and orchestration of inference (plain trained model inference or, in general, continuous learning). This implies, amongst others, the following:
- There is a need for logic that decides what data to store and transport, where. This logic would, for example, need input such as: where does the data originate from, where is data preprocessing hardware available, what is the available compute, storage, and transport?
- There is a need for logic that decides what to train and where. This logic would for example need input such as: which data is needed for the training, where is specialized training hardware available, what training technology will be used (distributed or not), what compute and transport capacity is available?
- There is a need for logic that decides where to do inference. When carrying out inference close to where data is generated is preferred, there needs to be support to deploy models remotely.
- To make this happen, training and learning use cases need to indicate their requirements. Data needs to come with annotations on timing aspects. The underlying hardware platform needs to expose what type of hardware acceleration is available.
- Finally, it should be noted that orchestration of data, training and inference is not a one-time deployment. Data may change over time, models may be retrained due to concept drift, application requirements may change over time, and so on. Orchestration should therefore be prepared for a highly dynamic environment.
Today’s application lifecycle management needs to evolve to also include lifecycle management of data, training and inference. All this needs to be integrated with the Continuous Integration/Continuous Delivery (CI/CD) pipeline (indicated as number 5 in the figure above). CI/CD would span from Ericsson all the way to the edge sites but may sometimes also have smaller loops that span more local lifecycle management.
Responsibility view
In the traditional development of a CI/CD process, the developing organization does the coding and testing of products within their own domain in a continuous process, typically with frequent releases and incremental feature additions. Once a release has reached the required quality level, it is pushed to the CSP’s sites and taken into production there. Up-and-running products send logs and other information back to the developing organization’s site, which is used to improve the product. What we see happening today are shorter and shorter CI/CD cycles, with smaller and smaller application components.
In a cognitive network, development will no longer be restricted to traditional coding. We will also see another type of product development in the form of feature engineering (as part of DataOps) and model training (as part of MLOps). Data for training may be produced within the developing organization but will in many cases come from the CSP’s network. Data is often seen as an asset. In many cases there are legal aspects and privacy aspects that need to be settled when using data. All this implies that agreements need to be in place when transferring data between the CSP and the developing organization. The DRG is the functionality that enforces data transfer according to the agreements. Related components are ‘helper functions’, for example to perform de-identification of data before a legal boundary is passed.
A DRG as a gateway between the developing organization and CSP site is one way to achieve a clear separation of responsibilities. It is a very similar separation as with traditional code development. This setup can be applied to use cases such as supervised learning where learning takes place within the developing organization’s domain. Long-term, we expect to see additional use cases where the DataOps and MLOps environments may be at the CSP site as well, and for some use cases only at the CSP’s site (for example, due to real-time constraints). This raises many new questions on the responsibility of resulting ML models. Some example questions are:
- If feature engineering and model training are performed by the developing organization at the CSP’s site with the CSP’s data, who owns the model and who takes responsibility for the model?
- What if the input data is a mixture of CSP data and data provided by the developing organization?
- If the model was trained in a federated way with multiple vendors involved, who owns the model and who is responsible?
Part of the answer to these questions may be to run protected environments within the CSP’s site; comparable to embassies in foreign countries. When passing the boundary between the CSP environment and the developing organization’s environment, functions like the DRG may be needed even when the developing organization’s environment is running remote at the CSP’s site. Secure hardware enclaves may be one technology that can be used to protect the developing organization’s environment.
Standardization
An aspect we do not address in this blog is the standardization efforts required for the evolution described in the previous sections. As we have outlined in our white paper AI adoption in in 5G networks, standardization work has already started in several industry fora, including: 3GPP SA2 for 5G core event data collection and insights for user and session-related use cases; 3GPP RAN3 and O-RAN for Radio Access Network (RAN) data collection and use cases; 3GPP SA5 for domain management and end-to-end use cases (such as slice assurance), and management of data collection; TMF for intent-based management services; and ETSI ZSM for closed loop control.
Summary
The expected scale and diversity of services served by future networks will make networks increasingly difficult for humans to operate, which means that future networks will be required to become increasingly intelligent and autonomous. Networks will gradually become cognitive systems with the ability to sense, reason, acquire new knowledge, and act autonomously. They will be fully controlled by intent-based technologies, while humans can focus on defining services and setting operational goals to fulfil business objectives.
The key enablers for this evolution will be data-driven operations, distributed intelligence, continuous learning, intent-based automation, and explainable and trustworthy AI. Moreover, all these technologies will have to be combined to work in synergy across different aspects of functional architecture, deployment scenarios and responsibility areas of different vendors and CSPs. Only then can we achieve the needed capabilities to optimize performance and operational efficiency.
Want to know more?
Read about cognitive networks in the Technology trends article 2021.
Read our whitepaper on ever-present intelligent communication.
Explore network automation
Learn more about AI in networks